This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Spark provides this abstraction layer to make it easy for a dataengineer to pass this interface to an MLengineer to implement. He previously worked as a product engineer in infrastructure automation. groupBy(window(embedding_stream['ts'], WINDOW_LENGTH, WINDOW_SLIDE)).applyInPandas(get_dists_to_mean,
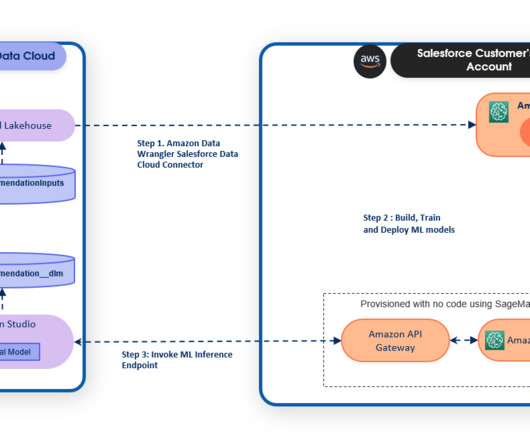
With this capability, businesses can access their Salesforce data securely with a zero-copy approach using SageMaker and use SageMaker tools to build, train, and deploy AI models. The inference endpoints are connected with Data Cloud to drive predictions in real time.
Data storage and versioning You need data storage and versioning tools to maintain dataintegrity, enable collaboration, facilitate the reproducibility of experiments and analyses, and ensure accurate ML model development and deployment. Easy collaboration, annotator management, and QA workflows.
However, scaling up generative AI and making adoption easier for different lines of businesses (LOBs) comes with challenges around making sure data privacy and security, legal, compliance, and operational complexities are governed on an organizational level. In this post, we discuss how to address these challenges holistically.
Perform an analysis on the transformed data Now that transformations have been done on the data, you may want to perform analyses to make sure they haven’t affected dataintegrity. About the Authors Rushabh Lokhande is a Senior Data & MLEngineer with AWS Professional Services Analytics Practice.
The Role of Data Scientists and MLEngineers in Health Informatics At the heart of the Age of Health Informatics are data scientists and MLengineers who play a critical role in harnessing the power of data and developing intelligent algorithms.
By demonstrating the process of deploying fine-tuned models, we aim to empower data scientists, MLengineers, and application developers to harness the full potential of FMs while addressing unique application requirements.
Machine Learning (ML) Machine Learning algorithms are like powerful engines, but they rely on clean fuel – clean data – to function effectively. Inaccurate data can lead to biased and unreliable models. But how can you personalize experiences and target marketing campaigns effectively if your customer data is a mess?
From data processing to quick insights, robust pipelines are a must for any ML system. Often the Data Team, comprising Data and MLEngineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier.
Packaging models with PMML Using the PMML library in Python, you can export your machine learning models to PMML format and then deploy that as a web service, a batch processing system, or a dataintegration platform. In this example, I’ll use the Neptune. You can set up a free account here or learn more about the tool here.
I see so many of these job seekers, especially on the MLOps side or the MLengineer side. You see them all the time with a headline like: “data science, machine learning, Java, Python, SQL, or blockchain, computer vision.” They started off as doing dataintegrations, and then became the ML monitoring team.
3 One team that started doing dataintegrations and, over time, evolved and shifted their focus to model monitoring. Then, we made an effort to engage data scientists through workshops and tailored support to transition smoothly to these better solutions. (This was my team.) 2 One team focused on serving the live models.
Available in SageMaker AI and SageMaker Unified Studio (preview) Data scientists and MLengineers can access these applications from Amazon SageMaker AI (formerly known as Amazon SageMaker) and from SageMaker Unified Studio. Comet has been trusted by enterprise customers and academic teams since 2017.
Employing robust data pipelines with tools like Apache Kafka or AWS Kinesis can maintain high throughput while safeguarding dataintegrity. Best Practices for Leveraging Simulation Platforms Teams are increasingly adopting a product-oriented mindset toward simulation platforms.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

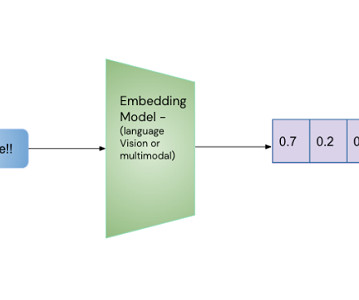


















Let's personalize your content