This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Be sure to check out her talk, “ Power trusted AI/ML Outcomes with DataIntegrity ,” there! Due to the tsunami of data available to organizations today, artificial intelligence (AI) and machine learning (ML) are increasingly important to businesses seeking competitive advantage through digital transformation.
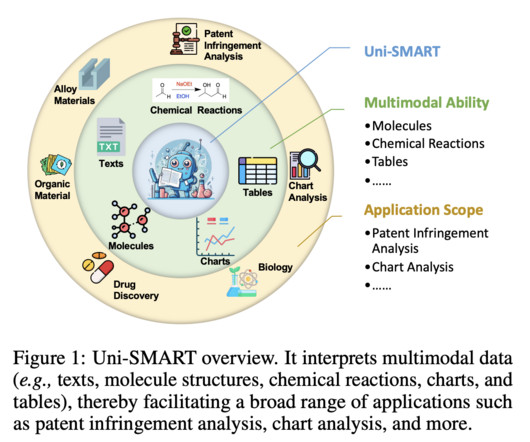
Don’t Forget to join our 38k+ ML SubReddit Want to get in front of 1.5 Work with us here The post This AI Paper Proposes Uni-SMART: Revolutionizing Scientific Literature Analysis with Multimodal DataIntegration appeared first on MarkTechPost. If you like our work, you will love our newsletter. Million AI enthusiasts?
The development of machine learning (ML) models for scientific applications has long been hindered by the lack of suitable datasets that capture the complexity and diversity of physical systems. This lack of comprehensive data makes it challenging to develop effective surrogate models for real-world scientific phenomena.
This solution ingests and processes data from hundreds of thousands of support tickets, escalation notices, public AWS documentation, re:Post articles, and AWS blog posts. By using Amazon Q Business, which simplifies the complexity of developing and managing ML infrastructure and models, the team rapidly deployed their chat solution.
Unified, governed data can also be put to use for various analytical, operational and decision-making purposes. This process is known as dataintegration, one of the key components to a strong data fabric. The remote execution engine is a fantastic technical development which takes dataintegration to the next level.
Amazon Redshift is the most popular cloud data warehouse that is used by tens of thousands of customers to analyze exabytes of data every day. SageMaker Studio is the first fully integrated development environment (IDE) for ML. You can use query_string to filter your dataset by SQL and unload it to Amazon S3.
Effective dataintegration is equally important. To ensure the highest degree of accuracy, we implemented rigorous validation checks, transforming raw data into actionable insights while avoiding the pitfalls of garbage in, garbage out. This insight allowed clients to capitalize on emerging opportunities.
AI and machine learning (ML) algorithms are capable of the following: Analyzing transaction patterns to detect fraudulent activities made by bots. AI-powered Analytics & Insights AI enhances the capabilities of blockchain systems using data-driven insights. AI and ML models often require high-speed processing and low latency.
These techniques utilize various machine learning (ML) based approaches. In this post, we look at how we can use AWS Glue and the AWS Lake Formation ML transform FindMatches to harmonize (deduplicate) customer data coming from different sources to get a complete customer profile to be able to provide better customer experience.
They focused on improving customer service using data with artificial intelligence (AI) and ML and saw positive results, with their Group AI Maturity increasing from 50% to 80%, according to the TM Forum’s AI Maturity Index. Amazon SageMaker Pipelines – Amazon SageMaker Pipelines is a CI/CD service for ML.
Healthcare agents can integrate LLM models and call external functions or APIs through a series of steps: natural language input processing , self-correction, chain of thought, function or API calling through an integration layer, dataintegration and processing, and persona adoption.
Extraction of relevant data points for electronic health records (EHRs) and clinical trial databases. Dataintegration and reporting The extracted insights and recommendations are integrated into the relevant clinical trial management systems, EHRs, and reporting mechanisms.
Furthermore, while machine learning (ML) algorithms can offer personalized treatment recommendations, the lack of transparency in these algorithms complicates individual accountability. Investing in modern dataintegration tools, such as Astera and Fivetran , with built-in data quality features will also help.
A groundbreaking few-shot prompting method using Gemini-Pro ensures the generation of high-quality implicit entailments while, concurrently, reducing annotation expenses and ensuring dataintegrity. Dont Forget to join our 70k+ ML SubReddit. The creation of the INLI dataset is a two-stage procedure.
By helping customers integrate artificial intelligence (AI) and machine learning (ML) into their key business operations, Quantum helps customers to effectively manage and unlock meaningful value from their unstructured data, creating actionable business insights that lead to better business decisions.
DataIntegrity: The Foundation for Trustworthy AI/ML Outcomes and Confident Business Decisions Let’s explore the elements of dataintegrity, and why they matter for AI/ML. Deep Learning Approaches to Sentiment Analysis, DataIntegrity, and Dolly 2.0
AI/ML models continuously evolve, enhancing their accuracy in detecting and circumventing the impacts of advanced persistent threats (APTs) and zero-day vulnerabilities. Reliability is also paramountAI systems often support mission-critical tasks, and even minor downtime or data loss can lead to significant disruptions or flawed AI outputs.
As such, organizations are increasingly interested in seeing how they can apply the whole suite of artificial intelligence (AI) and machine learning (ML) technologies to improve their business processes. For example, applied ML will help organizations that depend on the supply chain engage in better decision making, in real time.
Dataintegration stands as a critical first step in constructing any artificial intelligence (AI) application. While various methods exist for starting this process, organizations accelerate the application development and deployment process through data virtualization. Why choose data virtualization?
Origin and Vision The idea for Bagel emerged from its founder, Bidhan Roy , who has a rich engineering and machine learning background and has contributed to the worlds largest ML infrastructures at Amazon Alexa, Cash App, and Instacart.
Live DataIntegration : Capable of conducting detailed research, compiling up-to-date information into comprehensive visual and textual reports. Also,feel free to follow us on Twitter and dont forget to join our 85k+ ML SubReddit. Check out the Technical details and Try it here.
Introduction Deepchecks is a groundbreaking open-source Python package that aims to simplify and enhance the process of implementing automated testing for machine learning (ML) models. In this article, we will explore the various aspects of Deepchecks and how it can revolutionize the way we validate and maintain ML models.
It simplifies dataintegration from various sources and provides tools for data indexing, engines, agents, and application integrations. Babu Kariyaden Parambath is a Senior AI/ML Specialist at AWS. LlamaIndex is a framework for building LLM applications.
From data processing to quick insights, robust pipelines are a must for any ML system. Often the Data Team, comprising Data and ML Engineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier.
ELT Pipelines: Typically used for big data, these pipelines extract data, load it into data warehouses or lakes, and then transform it. DataIntegration, Ingestion, and Transformation Pipelines: These pipelines handle the organization of data from multiple sources, ensuring that it is properly integrated and transformed for use.
How to Scale Your Data Quality Operations with AI and ML: In the fast-paced digital landscape of today, data has become the cornerstone of success for organizations across the globe. Every day, companies generate and collect vast amounts of data, ranging from customer information to market trends.
Access to high-quality data can help organizations start successful products, defend against digital attacks, understand failures and pivot toward success. Emerging technologies and trends, such as machine learning (ML), artificial intelligence (AI), automation and generative AI (gen AI), all rely on good data quality.
For example, if you use AWS, you may prefer Amazon SageMaker as an MLOps platform that integrates with other AWS services. Knowledge and skills in the organization Evaluate the level of expertise and experience of your ML team and choose a tool that matches their skill set and learning curve. and Pandas or Apache Spark DataFrames.
This post presents a solution that uses a generative artificial intelligence (AI) to standardize air quality data from low-cost sensors in Africa, specifically addressing the air quality dataintegration problem of low-cost sensors. Qiong (Jo) Zhang , PhD, is a Senior Partner Solutions Architect at AWS, specializing in AI/ML.
Ring 3 uses the capabilities of Ring 1 and Ring 2, including the dataintegration capabilities of the platform for terminology standardization and person matching. This also supports the capabilities to insert actionable insights and care plan updates directly into the provider care flow within the Electronic Medical Record (EMR).
Artificial intelligence platforms enable individuals to create, evaluate, implement and update machine learning (ML) and deep learning models in a more scalable way. AI platform tools enable knowledge workers to analyze data, formulate predictions and execute tasks with greater speed and precision than they can manually.
Data scientists and engineers frequently collaborate on machine learning ML tasks, making incremental improvements, iteratively refining ML pipelines, and checking the model’s generalizability and robustness. To build a well-documented ML pipeline, data traceability is crucial.
Improvements over Idefics1 : Idefics2 utilizes the NaViT strategy for processing images in native resolutions, enhancing visual dataintegrity. Enhanced OCR capabilities through specialized dataintegration improve text transcription accuracy. Also, don’t forget to follow us on Twitter.
This article was originally an episode of the ML Platform Podcast , a show where Piotr Niedźwiedź and Aurimas Griciūnas, together with ML platform professionals, discuss design choices, best practices, example tool stacks, and real-world learnings from some of the best ML platform professionals. How do I develop my body of work?
Crawl4AI supports parallel processing, allowing multiple web pages to be crawled and processed simultaneously, thus reducing the time required for large-scale data collection tasks. It is also capable of error handling mechanisms and retry policies, ensuring dataintegrity even when pages fail to load or other network issues arise.
On the other hand, the valuable data needed to gain those insights has to stay confidential and is only allowed to be shared with certain parties or no third parties at all. So, is there a way to gain insights of valuable data through AI without the need to expose the data set or the AI model (LLM, ML, DL) to another party?
This issue is pronounced in environments where dataintegrity and confidentiality are paramount. Existing research in Robotic Process Automation (RPA) has focused on rule-based systems like UiPath and Blue Prism, which automate routine tasks such as data entry and customer service. Also, don’t forget to follow us on Twitter.
Building Multimodal AI Agents: Agentic RAG with Vision-Language Models Suman Debnath, Principal AI/ML Advocate at Amazon WebServices Learn how to create AI agents that integrate both vision and language using retrieval-augmented generation (RAG).
In BI systems, data warehousing first converts disparate raw data into clean, organized, and integrateddata, which is then used to extract actionable insights to facilitate analysis, reporting, and data-informed decision-making. The pipeline ensures correct, complete, and consistent data.
Next, we will load the weights into the same model in another script and stream the data from the AffectNet repository using DDA to train the model on. Any changes made to the data will only update the data repositories , while changes to the code and model will update the code repository.
This case study sheds light on how a leading global retailer, XYZ Retail, harnessed the power of Machine Learning (ML) to revolutionize its demand forecasting process. Real-time Updates: ML models continuously updated forecasts, allowing XYZ Retail to make agile decisions regarding inventory management, promotions, and supply chain logistics.
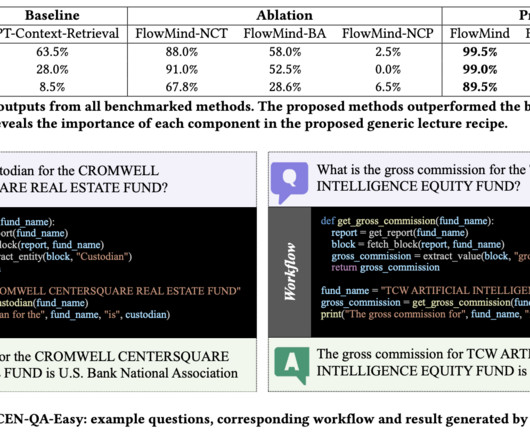
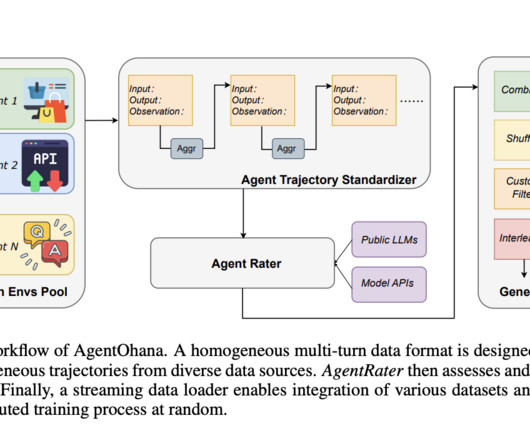
The heterogeneity of data not only poses a roadblock in terms of compatibility but also affects the consistency and quality of agent training. Existing methodologies, while commendable, often need to address the multifaceted challenges presented by this data diversity. Check out the Paper.
Jay Mishra is the Chief Operating Officer (COO) at Astera Software , a rapidly-growing provider of enterprise-ready data solutions. Speed Varying data formats Data publishing What are some ways that Astera has integrated AI into customer workflow? What initially attracted you to computer science?
Build a governed foundation for generative AI with IBM watsonx and data fabric With IBM watsonx , IBM has made rapid advances to place the power of generative AI in the hands of ‘AI builders’ IBM watsonx.ai Watsonx also includes watsonx.data — a fit-for-purpose data store built on an open lakehouse architecture.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content