This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this post, we propose an end-to-end solution using Amazon Q Business to address similar enterprise data challenges, showcasing how it can streamline operations and enhance customer service across various industries. The Process Data Lambda function redacts sensitive data through Amazon Comprehend.
NLP in particular has been a subfield that has been focussed heavily in the past few years that has resulted in the development of some top-notch LLMs like GPT and BERT. Artificial Intelligence is a very vast branch in itself with numerous subfields including deep learning, computer vision , natural language processing , and more.
In Natural Language Processing (NLP) tasks, data cleaning is an essential step before tokenization, particularly when working with text data that contains unusual word separations such as underscores, slashes, or other symbols in place of spaces. The post Is There a Library for Cleaning Data before Tokenization?
In addition, the Amazon Bedrock Knowledge Bases team worked closely with us to address several critical elements, including expanding embedding limits, managing the metadata limit (250 characters), testing different chunking methods, and syncing throughput to the knowledge base.
In this post, we demonstrate how data aggregated within the AWS CCI Post Call Analytics solution allowed Principal to gain visibility into their contact center interactions, better understand the customer journey, and improve the overall experience between contact channels while also maintaining dataintegrity and security.
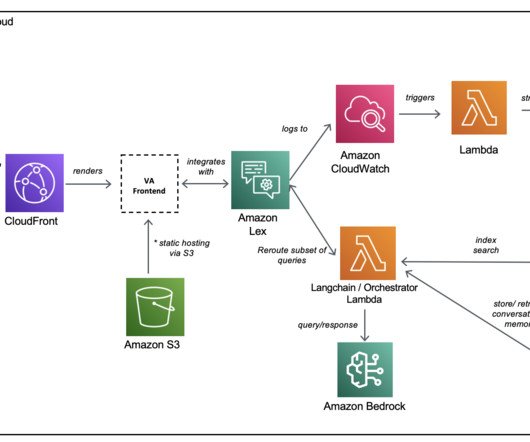
Each request/response interaction is facilitated by the AWS SDK and sends network traffic to Amazon Lex (the NLP component of the bot). Metadata about the request/response pairings are logged to Amazon CloudWatch. The CloudWatch log group is configured with a subscription filter that sends logs into Amazon OpenSearch Service.
2 For dynamic models, such as those with variable-length inputs or outputs, which are frequent in natural language processing (NLP) and computer vision, PyTorch offers improved support. Finally, you can store the model and other metadata information using the INSERT INTO command. track dataset version model[ "data/train_and_test" ].track_files(
It requires sophisticated tools and algorithms to derive meaningful patterns and trends from the sheer magnitude of data. Meta DataMetadata, often dubbed “data about data,” provides essential context and descriptions for other datasets.
The benefits of Databricks over Spark is Highly reliable and performant data pipelines and Productive data science at scale — source: [link] Databricks also introduced Delta Lake, an open-source storage layer that brings reliability to data lakes. MapReduce: simplified data processing on large clusters. Morgan Kaufmann.
There’s no component that stores metadata about this feature store? Mikiko Bazeley: In the case of the literal feature store, all it does is store features and metadata. We’re assuming that data scientists, for the most part, don’t want to write transformations elsewhere. Mikiko Bazeley: 100%.
It facilitates real-time data synchronization and updates by using GraphQL APIs, providing seamless and responsive user experiences. Efficient metadata storage with Amazon DynamoDB – To support quick and efficient data retrieval, document metadata is stored in Amazon DynamoDB.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















Let's personalize your content