This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
One of these strategies is using Amazon Simple Storage Service (Amazon S3) folder structures and Amazon Bedrock Knowledge Bases metadata filtering to enable efficient data segmentation within a single knowledge base. The S3 bucket, containing customer data and metadata, is configured as a knowledge base data source.
In the course of developing our Conformer and Universal speech recognition models , we've had to navigate the complexities of handling massive amounts of audio data and metadata. As our data needs grew, so too did the accompanying challenges, such as fragmentation, bottlenecks, and limited accessibility.
When we talk about dataintegrity, we’re referring to the overarching completeness, accuracy, consistency, accessibility, and security of an organization’s data. Together, these factors determine the reliability of the organization’s data. In short, yes.
It facilitates real-time data synchronization and updates by using GraphQL APIs, providing seamless and responsive user experiences. Efficient metadata storage with Amazon DynamoDB – To support quick and efficient data retrieval, document metadata is stored in Amazon DynamoDB.
In this post, we propose an end-to-end solution using Amazon Q Business to address similar enterprise data challenges, showcasing how it can streamline operations and enhance customer service across various industries. For the metadata file used in this example, we focus on boosting two key metadata attributes: _document_title and services.
VDURA prioritizes durability through multi-layered data protection, including erasure coding and hybrid storage architectures that balance performance and durability. This ensures that organizations can maintain dataintegrity while scaling their infrastructure.
The entire generative AI pipeline hinges on the data pipelines that empower it, making it imperative to take the correct precautions. 4 key components to ensure reliable data ingestion Data quality and governance: Data quality means ensuring the security of data sources, maintaining holistic data and providing clear metadata.
These datasets are offered in uniform grid formats and use HDF5 files, ensuring high dataintegrity and easy access for computational analysis. The data is available with a PyTorch interface, allowing for seamless integration into existing ML pipelines.
To maximize the value of their AI initiatives, organizations must maintain dataintegrity throughout its lifecycle. Managing this level of oversight requires adept handling of large volumes of data. Just as aircraft, crew and passengers are scrutinized, data governance maintains dataintegrity and prevents misuse or mishandling.
The funding will allow ApertureData to scale its operations and launch its new cloud-based service, ApertureDB Cloud, a tool designed to simplify and accelerate the management of multimodal data, which includes images, videos, text, and related metadata. ApertureData’s flagship product, ApertureDB , addresses this challenge head-on.
Among the tasks necessary for internal and external compliance is the ability to report on the metadata of an AI model. Metadata includes details specific to an AI model such as: The AI model’s creation (when it was created, who created it, etc.)
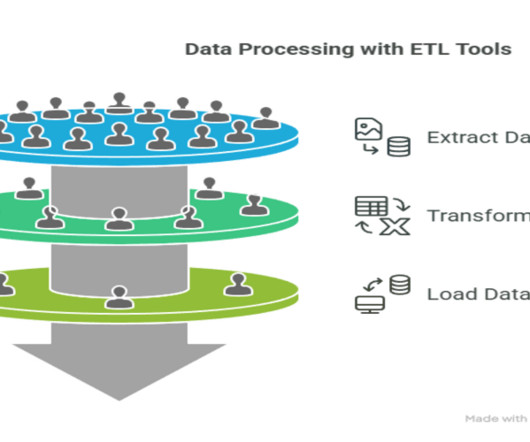
ETL ( Extract, Transform, Load ) Pipeline: It is a dataintegration mechanism responsible for extracting data from data sources, transforming it into a suitable format, and loading it into the data destination like a data warehouse. The pipeline ensures correct, complete, and consistent data.
Moreover, Crawl4AI offers features such as user-agent customization, JavaScript execution for dynamic data extraction, and proxy support to bypass web restrictions, enhancing its versatility compared to traditional crawlers. Crawl4AI employs a multi-step process to optimize web crawling for LLM training.
IBM Cloud Pak for Data Express solutions offer clients a simple on ramp to start realizing the business value of a modern architecture. Data governance. The data governance capability of a data fabric focuses on the collection, management and automation of an organization’s data. Dataintegration.
As a result, it’s easier to find problems with data quality, inconsistencies, and outliers in the dataset. Metadata analysis is the first step in establishing the association, and subsequent steps involve refining the relationships between individual database variables. The 18 best data profiling tools are listed below.
In addition, the Amazon Bedrock Knowledge Bases team worked closely with us to address several critical elements, including expanding embedding limits, managing the metadata limit (250 characters), testing different chunking methods, and syncing throughput to the knowledge base.
Building knowledge graphs : Generative AI can automatically build comprehensive knowledge graphs by understanding the intricate data models of different vendors. These knowledge graphs represent data entities and their relationships, providing a structured and interconnected view of the vendor ecosystem.
An enterprise data catalog does all that a library inventory system does – namely streamlining data discovery and access across data sources – and a lot more. For example, data catalogs have evolved to deliver governance capabilities like managing data quality and data privacy and compliance.
Extraction of relevant data points for electronic health records (EHRs) and clinical trial databases. Dataintegration and reporting The extracted insights and recommendations are integrated into the relevant clinical trial management systems, EHRs, and reporting mechanisms.
Authority Management Access control is a security & privacy technology that is used to restrict a user’s access to authorized resources on the basis of pre-defined rules, set of instructions, policies, safeguarding dataintegrity, and system security.
Summary: Choosing the right ETL tool is crucial for seamless dataintegration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Choosing the right ETL tool is crucial for smooth data management.
How is data.world investing in research and development to stay at the forefront of AI and dataintegration technologies? We’re committed to staying at the bleeding edge of what’s possible in AI and dataintegration. Instead, we aim to eliminate the need for users to query their data altogether.
Because of the platform’s versatility in handling different document kinds and layouts, data scientists may effectively preprocess data at scale without being constrained by issues with format or cleaning. The main features of the platform which are meant to make data workflows more efficient are as follows.
When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. Can you compare images?
By leveraging data services and APIs, a data fabric can also pull together data from legacy systems, data lakes, data warehouses and SQL databases, providing a holistic view into business performance. It uses knowledge graphs, semantics and AI/ML technology to discover patterns in various types of metadata.
The training of generative models, such as GPT-4, Gemini, Cluade, and others, relies on often insufficiently documented and vetted data. This unstructured and obscure data collection poses severe challenges in maintaining dataintegrity and ethical standards.
Both approaches were typically monolithic and centralized architectures organized around mechanical functions of data ingestion, processing, cleansing, aggregation, and serving. Monitor and identify data quality issues closer to the source to mitigate the potential impact on downstream processes or workloads.
Some of the common challenges that enterprises face when protecting data are: Maintaining dataintegrity and privacy amid the threat of potential data breaches and data leaks. Managing IT budgets while dealing with increased cyberthreats and regulatory compliance.
Item Tower: Encodes item features like metadata, content characteristics, and contextual information. While these systems enhance user engagement and drive revenue, they also present challenges like data quality and privacy concerns.
Among those algorithms, deep/neural networks are more suitable for e-commerce forecasting problems as they accept item metadata features, forward-looking features for campaign and marketing activities, and – most importantly – related time series features. She has 12 years of software development and architecture experience.
They excel at managing structured data and supporting ACID (Atomicity, Consistency, Isolation, Durability) transactions. Scalability: Relational databases can scale vertically by upgrading hardware, but horizontal scaling can be more challenging due to the need to maintain dataintegrity and relationships.
Packaging models with PMML Using the PMML library in Python, you can export your machine learning models to PMML format and then deploy that as a web service, a batch processing system, or a dataintegration platform. Finally, you can store the model and other metadata information using the INSERT INTO command.
Amazon Redshift has been constantly innovating over the last decade to give you a modern, massively parallel processing cloud data warehouse that delivers the best price-performance, ease of use, scalability, and reliability. Discover how you can use Amazon Redshift to build a data mesh architecture to analyze your data.
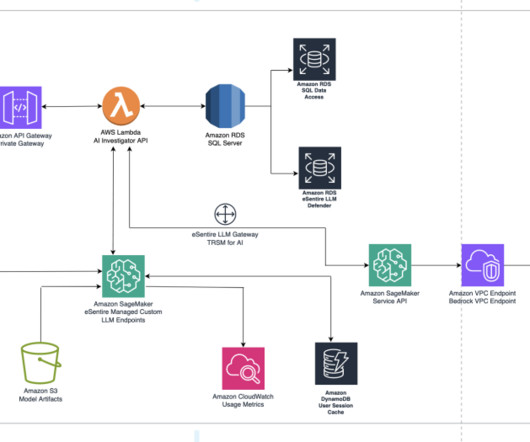
eSentire has over 2 TB of signal data stored in their Amazon Simple Storage Service (Amazon S3) data lake. eSentire used gigabytes of additional human investigation metadata to perform supervised fine-tuning on Llama 2. They needed no additional infrastructure for dataintegration.
DataIntegration : The embeddings and metadata are compiled into GeoParquet archives, ensuring streamlined access and usability. Preprocessing : Fragments are normalized and scaled according to the requirements of the embedding models.
It provides insights into considerations for choosing the right tool, ensuring businesses can optimize their dataintegration processes for better analytics and decision-making. Introduction In todays data-driven world, organizations are overwhelmed with vast amounts of information. What is ETL?
However, scaling up generative AI and making adoption easier for different lines of businesses (LOBs) comes with challenges around making sure data privacy and security, legal, compliance, and operational complexities are governed on an organizational level. In this post, we discuss how to address these challenges holistically.
In this post, we demonstrate how data aggregated within the AWS CCI Post Call Analytics solution allowed Principal to gain visibility into their contact center interactions, better understand the customer journey, and improve the overall experience between contact channels while also maintaining dataintegrity and security.
Irina Steenbeek introduces the concept of descriptive lineage as “a method to record metadata-based data lineage manually in a repository.” Extraction, transformation and loading (ETL) tools dominated the dataintegration scene at the time, used primarily for data warehousing and business intelligence.
The Amazon S3 PUT action invokes an AWS Lambda This Lambda function copies all the artifacts from the S3 bucket in the development account to another S3 bucket in the AI/ML governance account, providing restricted access and dataintegrity. This post assumes your accounts and S3 buckets are in the same AWS Region.
They enhance dataintegrity, security, and accessibility while providing tools for efficient data management and retrieval. A Database Management System (DBMS) is specialised software designed to efficiently manage and organise data within a computer system. Indices are data structures optimised for rapid data retrieval.
Its in-memory processing helps to ensure that data is ready for quick analysis and reporting, enabling real-time what-if scenarios and reports without lag. Our solution handles massive multidimensional cubes seamlessly, enabling you to maintain a complete view of your data without sacrificing performance or dataintegrity.
These are subject-specific subsets of the data warehouse, catering to the specific needs of departments like marketing or sales. They offer a focused selection of data, allowing for faster analysis tailored to departmental goals. Metadata This acts like the data dictionary, providing crucial information about the data itself.
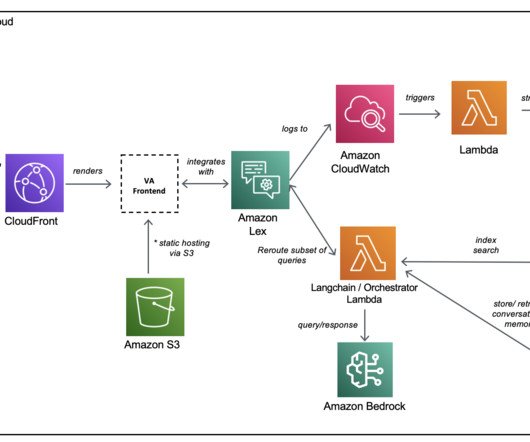
Metadata about the request/response pairings are logged to Amazon CloudWatch. As an Information Technology Leader, Jay specializes in artificial intelligence, dataintegration, business intelligence, and user interface domains.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content