This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Today, enterprises need real-time data analysis, advanced analytics, and even predictive capabilities within the familiar spreadsheet format. LargeLanguageModels (LLMs) , advanced AI models capable of understanding and generating human language, are changing this domain.
Introduction Largelanguagemodels (LLMs) have revolutionized natural language processing (NLP), enabling various applications, from conversational assistants to content generation and analysis.
Data contamination in LargeLanguageModels (LLMs) is a significant concern that can impact their performance on various tasks. It refers to the presence of test data from downstream tasks in the training data of LLMs. What Are LargeLanguageModels?
When it comes to deploying largelanguagemodels (LLMs) in healthcare, precision is not just a goalits a necessity. Their work has set a gold standard for integrating advanced natural language processing (NLP ) into clinical settings. Peer-reviewed research to validate theoretical accuracy.
This is doubly true for complex AI systems, such as largelanguagemodels, that process extensive datasets for tasks like language processing, image recognition, and predictive analysis. Only then can we raise the potential of AI and largelanguagemodel projects to breathtaking new heights.
IntegratingLargeLanguageModels (LLMs) in autonomous agents promises to revolutionize how we approach complex tasks, from conversational AI to code generation. A significant challenge lies at the core of advancing independent agents: data’s vast and varied nature. Check out the Paper.
In recent years, largelanguagemodels (LLMs) have gained attention for their effectiveness, leading various industries to adapt general LLMs to their data for improved results, making efficient training and hardware availability crucial. Continual Pre-Training of LargeLanguageModels: How to (re) warm your model?
We cannot deny the significant strides made in natural language processing (NLP) through largelanguagemodels (LLMs). Still, these models often need to catch up when dealing with the complexities of structured information, highlighting a notable gap in their capabilities.
Looking ahead, how do you envision the role of data observability in supporting the deployment of AI and largelanguagemodels at scale, especially in industries with stringent data quality and governance requirements?
Generative AI has altered the tech industry by introducing new data risks, such as sensitive data leakage through largelanguagemodels (LLMs), and driving an increase in requirements from regulatory bodies and governments.
VideoLLaMA 2 retains the dual-branch architecture of its predecessor, with separate Vision-Language and Audio-Language branches that connect pre-trained visual and audio encoders to a largelanguagemodel.
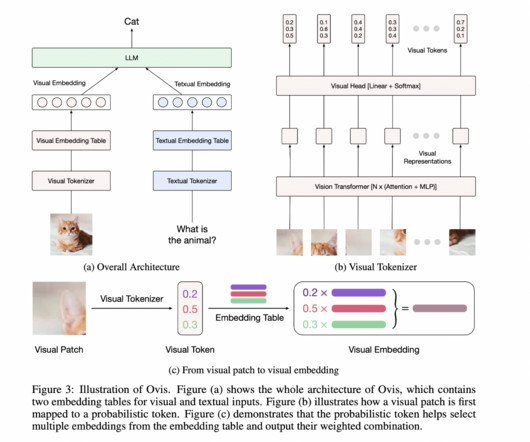
is a new multimodal largelanguagemodel (MLLM) that structurally aligns visual and textual embeddings to address this challenge. By introducing a structured visual embedding strategy, Ovis enables more effective multimodal dataintegration, improving performance across various tasks. Click here to set up a call!
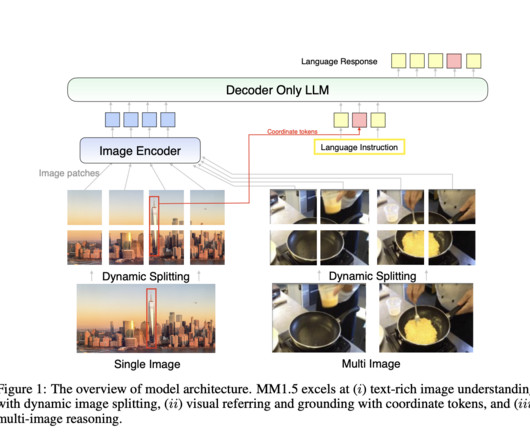
Multimodal largelanguagemodels (MLLMs) represent a cutting-edge area in artificial intelligence, combining diverse data modalities like text, images, and even video to build a unified understanding across domains. point gain in benchmarks focused on text-rich image understanding compared to prior models.
We started from a blank slate and built the first native largelanguagemodel (LLM) customer experience intelligence and service automation platform. This makes us the central hub, collecting data from all these sources and serving as the intelligence layer on top.
Companies still often accept the risk of using internal data when exploring largelanguagemodels (LLMs) because this contextual data is what enables LLMs to change from general-purpose to domain-specific knowledge. In the generative AI or traditional AI development cycle, data ingestion serves as the entry point.
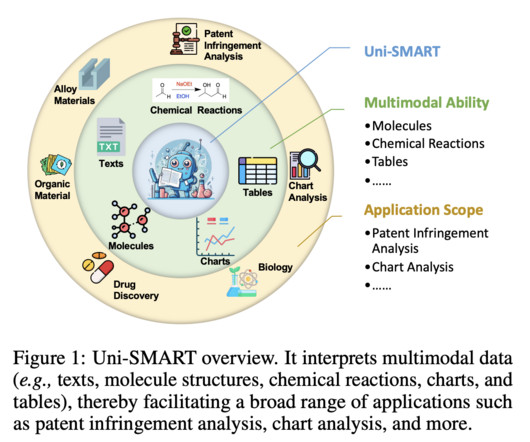
Work with us here The post This AI Paper Proposes Uni-SMART: Revolutionizing Scientific Literature Analysis with Multimodal DataIntegration appeared first on MarkTechPost. Don’t Forget to join our 38k+ ML SubReddit Want to get in front of 1.5 Million AI enthusiasts?
These datasets are offered in uniform grid formats and use HDF5 files, ensuring high dataintegrity and easy access for computational analysis. The data is available with a PyTorch interface, allowing for seamless integration into existing ML pipelines. If you like our work, you will love our newsletter.
DAOs also capture detailed descriptions of ID documents, ensuring accurate data validation and security checks at scale. Leveraging largelanguagemodels and multimodal models in conjunction with our DAO database, we can effectively generalize at scale while maintaining the necessary specificity for individual ID documents.
LLMs are one of the most exciting advancements in natural language processing (NLP). It helps in standardizing the text data, reducing its dimensionality, and extracting meaningful features for machine learning models.
As the demand for generative AI grows, so does the hunger for high-quality data to train these systems. Scholarly publishers have started to monetize their research content to provide training data for largelanguagemodels (LLMs).
Largelanguagemodels have been game-changers in artificial intelligence, but the world is much more than just text. These languagemodels are breaking boundaries, venturing into a new era of AI — Multi-Modal Learning. However, the influence of largelanguagemodels extends beyond text alone.
co-founder says data centers will be less energy-intensive in the future as artificial intelligence makes computations more efficient. bloomberg.com CData scores $350M as dataintegration needs surge in the age of AI In the race to adopt AI and gain a competitive edge, enterprises are making substantial investments.
Jay Mishra is the Chief Operating Officer (COO) at Astera Software , a rapidly-growing provider of enterprise-ready data solutions. Using Gen AI to enhance usability AI integration in RM and other modules AI functionality as a toolset What are some of the best practices to leverage AI and ML models in data management for large companies?
Now, Syngenta is advancing further by using largelanguagemodels (LLMs) and Amazon Bedrock Agents to implement Cropwise AI on AWS, marking a new era in agricultural technology. His primary focus lies in using the full potential of data, algorithms, and cloud technologies to drive innovation and efficiency.
A wide variety of areas have demonstrated excellent performance for largelanguagemodels (LLMs), which are flexible tools for language generation. To decipher the subjective experience of a user, the researchers effectively incorporate longitudinal time-series sensor features. Several restrictions apply to this work.
Cache-Augmented Generation (CAG) vs Retrieval-Augmented Generation (RAG) Image by Author In the evolving landscape of largelanguagemodels (LLMs), two significant techniques have emerged to address their inherent limitations: Cache-Augmented Generation (CAG) and Retrieval-Augmented Generation (RAG).
Meta's recent launch of Llama 3.2 , the latest iteration in its Llama series of largelanguagemodels, is a significant development in the evolution of open-source generative AI ecosystem. This upgrade extends Llama’s capabilities in two dimensions. On one hand, Llama 3.2
It can be challenging to manage enormous data volumes while ensuring users can quickly locate what they need. Regarding privacy issues, language support, and ease of use, existing tools frequently need to catch up, especially when dealing with sensitive data.
The recent success of artificial intelligence based largelanguagemodels has pushed the market to think more ambitiously about how AI could transform many enterprise processes. However, consumers and regulators have also become increasingly concerned with the safety of both their data and the AI models themselves.
This complexity arises from the diverse requirements and unique challenges that each network presents, including variations in network architecture, operational priorities and data landscapes. These knowledge graphs represent data entities and their relationships, providing a structured and interconnected view of the vendor ecosystem.
Cleanlab Image source Cleanlab is developed to enhance the quality of AI data by identifying and correcting errors, such as hallucinations in an LLM (LargeLanguageModel). Cons The pricing and licensing model may not be suitable for all budgets. Dataintegrity auditing techniques to identify biases.
This means it can carry out multi-step tasks such as researching information, transforming data, or even performing real-world actions (like making a phone call) without constant guidance. Each task is intelligently routed to the optimal model based on complexity, speed, and accuracy needs, ensuring efficient and precise execution.
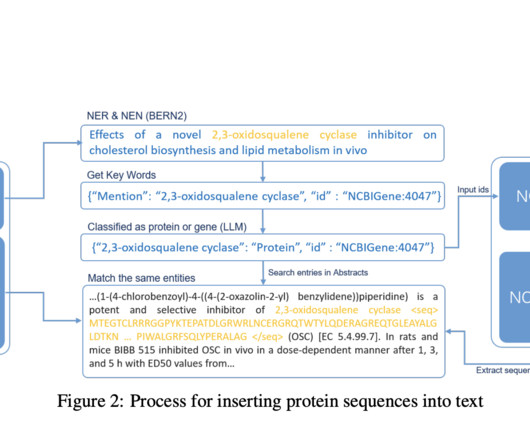
The dataset and benchmark aim to bridge the gap in protein-text dataintegration, enabling LLMs to understand protein sequences without extra encoders and to generate accurate protein knowledge using the novel Enzyme Chain of Thought (ECoT) approach. Join our Telegram Channel and LinkedIn Gr oup.
This is where the integration of cutting-edge technologies, such as audio-to-text translation and largelanguagemodels (LLMs), holds the potential to revolutionize the way patients receive, process, and act on vital medical information. Recommendations for personalized patient care or adjustments to treatment regimens.
This issue is pronounced in environments where dataintegrity and confidentiality are paramount. Existing research in Robotic Process Automation (RPA) has focused on rule-based systems like UiPath and Blue Prism, which automate routine tasks such as data entry and customer service.
Pathology, an aspect of diagnosis is undergoing significant changes, with the emergence of LargeLanguageModels (LLMs). A research published in “Nature Medicine” reported that an AI model achieved a 0.98 This progress signals the start of an era in healthcare known as precision pathology.
DataIntegrity: The Foundation for Trustworthy AI/ML Outcomes and Confident Business Decisions Let’s explore the elements of dataintegrity, and why they matter for AI/ML. How MLOps Work in the Era of LargeLanguageModels In the era of largelanguagemodels, how we approach MLOps may be a bit different than usual.
Largelanguagemodels (LLMs) have revolutionized the field of natural language processing, enabling machines to understand and generate human-like text with remarkable accuracy. However, despite their impressive language capabilities, LLMs are inherently limited by the data they were trained on.
Traditional Databases : Structured Data Storage : Traditional databases, like relational databases, are designed to store structured data. This means data is organized into predefined tables, rows, and columns, ensuring dataintegrity and consistency.
With the advent of multimodal models, the ambition to engage the textual with the visual opens up unprecedented avenues for machine comprehension. These advanced models go beyond the traditional scope of largelanguagemodels (LLMs), aiming to grasp and utilize both forms of data to tackle many tasks.
LLMs and Their Role in Telemedicine and Remote Care LargeLanguageModels (LLMs) are advanced artificial intelligence systems developed to understand and generate text in a human-like manner. LLMs are crucial in telemedicine and remote care.
By integrating cryptographic techniques like zero-knowledge proofs and differential privacy, ZKLoRA ensures the security of proprietary LoRA updates and base models. The protocol enables trust-driven collaborations across geographically distributed teams without compromising dataintegrity or intellectual property.
They are more advanced and flexible but require a large amount of high-quality data and may create texts that need to be more relevant or accurate for the target task or domain. Model-based Approaches These state-of-the-art techniques that use LargeLanguageModels (LLMs) like BERT , GPT , and XLNet present a promising solution.
Join Us On Discord AssemblyAI Integrations Check out our new integrations page for all the latest AssemblyAI integrations and start building with your favorite tools and services. LlamaIndex Integration : With LlamaIndex, you can easily store and index your data, and then use them with LLMs to build applications.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content