This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Metadata can play a very important role in using data assets to make data driven decisions. Generating metadata for your data assets is often a time-consuming and manual task. First, we explore the option of in-context learning, where the LLM generates the requested metadata without documentation.
When we talk about dataintegrity, we’re referring to the overarching completeness, accuracy, consistency, accessibility, and security of an organization’s data. Together, these factors determine the reliability of the organization’s data. In short, yes.
Amazon Q Business , a new generative AI-powered assistant, can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in an enterprises systems. Large-scale data ingestion is crucial for applications such as document analysis, summarization, research, and knowledge management.
Throughout my career, Ive been building and refining this unique combination of technical and business insights, which continues to inform my approach to innovation in the industry. This ensures that organizations can maintain dataintegrity while scaling their infrastructure.
Everything is data—digital messages, emails, customer information, contracts, presentations, sensor data—virtually anything humans interact with can be converted into data, analyzed for insights or transformed into a product. Managing this level of oversight requires adept handling of large volumes of data.
The entire generative AI pipeline hinges on the data pipelines that empower it, making it imperative to take the correct precautions. 4 key components to ensure reliable data ingestion Data quality and governance: Data quality means ensuring the security of data sources, maintaining holistic data and providing clear metadata.
To prevent these scenarios, protection of data, user assets, and identity information has been a major focus of the blockchain security research community, as to ensure the development of the blockchain technology, it is essential to maintain its security.
In the rapidly evolving healthcare landscape, patients often find themselves navigating a maze of complex medical information, seeking answers to their questions and concerns. However, accessing accurate and comprehensible information can be a daunting task, leading to confusion and frustration.
Among the tasks necessary for internal and external compliance is the ability to report on the metadata of an AI model. Metadata includes details specific to an AI model such as: The AI model’s creation (when it was created, who created it, etc.) But the implementation of AI is only one piece of the puzzle.
In BI systems, data warehousing first converts disparate raw data into clean, organized, and integrateddata, which is then used to extract actionable insights to facilitate analysis, reporting, and data-informed decision-making. Data Sources: Data sources provide information and context to a data warehouse.
So, instead of wandering the aisles in hopes you’ll stumble across the book, you can walk straight to it and get the information you want much faster. An enterprise data catalog does all that a library inventory system does – namely streamlining data discovery and access across data sources – and a lot more.
Investment professionals face the mounting challenge of processing vast amounts of data to make timely, informed decisions. This challenge is particularly acute in credit markets, where the complexity of information and the need for quick, accurate insights directly impacts investment outcomes.
Data profiling is a crucial tool. For evaluating data quality. It entails analyzing, cleansing, transforming, and modeling data to find valuable information, improve data quality, and assist in better decision-making, What is Data Profiling? Fixing poor data quality might otherwise cost a lot of money.
Based on our experience from proof-of-concept (PoC) projects with clients, here are the best ways to leverage generative AI in the data layer: Understanding vendor data : Generative AI can process extensive vendor documentation to extract critical information about individual parameters.
Transparency throughout the data lifecycle and the ability to demonstrate dataintegrity and consistency are critical factors for improvement. The ledger delivers tamper evidence, enabling the detection of any modifications made to the data, even if carried out by privileged users.
The main features of the platform which are meant to make data workflows more efficient are as follows. Document Extraction: Unstructured is excellent at extracting metadata and document elements from a wide range of document types.
This enhances transparency and reliability, enabling businesses to make informed decisions with confidence. Our platform tracks data lineage, offering full traceability of data and transformations. AI-generated answers are connected back to their data sources, providing a clear trace of how each piece of information was derived.
Summary: Choosing the right ETL tool is crucial for seamless dataintegration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Also Read: Top 10 Data Science tools for 2024.
When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. Can you compare images?
Some of the common challenges that enterprises face when protecting data are: Maintaining dataintegrity and privacy amid the threat of potential data breaches and data leaks. Managing IT budgets while dealing with increased cyberthreats and regulatory compliance.
Age and Gender Targeting: Ads are delivered based on demographic information such as age and gender, which is collected during user registration or inferred from user behavior. Key components of this model include: User Tower: Captures and encodes user features such as demographic information and browsing history.
In the ever-evolving world of big data, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. They excel at managing structured data and supporting ACID (Atomicity, Consistency, Isolation, Durability) transactions.
Among those algorithms, deep/neural networks are more suitable for e-commerce forecasting problems as they accept item metadata features, forward-looking features for campaign and marketing activities, and – most importantly – related time series features. We are able to forecast over 10,000 SKUs daily in all the countries we serve.
Enterprises today face major challenges when it comes to using their information and knowledge bases for both internal and external business operations. Internally, employees can often spend countless hours hunting down information they need to do their jobs, leading to frustration and reduced productivity.
However, scaling up generative AI and making adoption easier for different lines of businesses (LOBs) comes with challenges around making sure data privacy and security, legal, compliance, and operational complexities are governed on an organizational level. For more information, see Monitor Amazon Bedrock with Amazon CloudWatch.
In this post, we demonstrate how data aggregated within the AWS CCI Post Call Analytics solution allowed Principal to gain visibility into their contact center interactions, better understand the customer journey, and improve the overall experience between contact channels while also maintaining dataintegrity and security.
Cons of the Python Pickle Approach 1 If you unpickle untrusted data, pickling could pose a security threat. Unpickling an object can execute malicious code, so it’s crucial to only unpickle information from reliable sources. Finally, you can store the model and other metadatainformation using the INSERT INTO command.
Irina Steenbeek introduces the concept of descriptive lineage as “a method to record metadata-based data lineage manually in a repository.” Extraction, transformation and loading (ETL) tools dominated the dataintegration scene at the time, used primarily for data warehousing and business intelligence.
They enhance dataintegrity, security, and accessibility while providing tools for efficient data management and retrieval. It serves as a robust intermediary between end-users, applications, and the underlying database, ensuring dataintegrity, security, accessibility, and overall efficiency.
Introduction The presence of large volumes of data within organisations requires effective sorting and analysing ensuring that decision-making is highly credible. Almost all organisations nowadays make informed decisions by leveraging data and analysing the market effectively. What is Data Profiling in ETL?
Challenge As AI becomes ubiquitous, it’s increasingly used to process information and interact with customers in a sensitive context. For cross-Region copying, see Copy data from an S3 bucket to another account and Region by using the AWS CLI. Suppose a tax agency is interacting with its users through a chatbot.
Its in-memory processing helps to ensure that data is ready for quick analysis and reporting, enabling real-time what-if scenarios and reports without lag. Our solution handles massive multidimensional cubes seamlessly, enabling you to maintain a complete view of your data without sacrificing performance or dataintegrity.
These include the database engine for executing queries, the query processor for interpreting SQL commands, the storage manager for handling physical data storage, and the transaction manager for ensuring dataintegrity through ACID properties. Data Independence: Changes in database structure do not affect application programs.
The primary purpose of a DBMS is to provide a systematic way to manage large amounts of data, ensuring that it is organised, accessible, and secure. By employing a DBMS, organisations can maintain dataintegrity, reduce redundancy, and streamline data operations, enabling more informed decision-making.
This blog aims to clarify Big Data concepts, illuminate Hadoops role in modern data handling, and further highlight how HDFS strengthens scalability, ensuring efficient analytics and driving informed business decisions. Key Takeaways HDFS in Big Data distributes large files across commodity servers, reducing hardware costs.
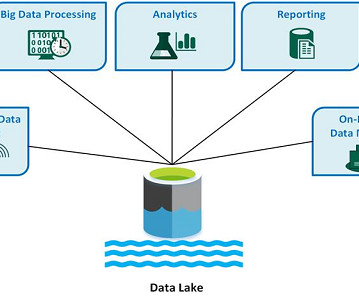
Data lakes are able to handle a diverse range of data types. From images, videos, text, and even sensor data. Then, there’s dataintegration. A data lake can also act as a central hub for integratingdata from various sources and systems within an organization.
Data is driving most business decisions. In this, data modeling tools play a crucial role in developing and maintaining the information system. Moreover, it involves the creation of a conceptual representation of data and its relationship. Data modeling tools play a significant role in this.
This flexibility allows organizations to store vast amounts of raw data without the need for extensive preprocessing, providing a comprehensive view of information. Centralized Data Repository Data Lakes serve as a centralized repository, consolidating data from different sources within an organization.
Data Processes and Organizational Structure Data Governance access controls enable the end-users to see how data processing works inside an organization. It can include data refresh cadences, PII limitations, regulatory data regulations, or even data access. It ensures the safe storage of data.
This process involves real-time monitoring and documentation to provide visibility on the data quality, thereby helping the organization detect and address data-related issues. Bigeye Its analytical prowess and data visualization capabilities will help Data Scientists make effective data-driven decision-making.
Its architecture includes FlowFiles, repositories, and processors, enabling efficient data processing and transformation. With a user-friendly interface and robust features, NiFi simplifies complex data workflows and enhances real-time dataintegration. How Does Apache NiFi Ensure DataIntegrity?
Access Transparency Users experience seamless access to files, as the system hides the complexities of how data distributed across various servers. Efficient Data Retrieval AI algorithms often require quick access to data for training and inference. This centralization aids in efficient file management and coordination.
Introduction In today’s data-driven world, organizations generate approximately 2.5 quintillion bytes of data daily, highlighting the critical need for efficient data management. Database Management Systems (DBMS) serve as the backbone of data handling.
The use of the Terraform remote state , in particular, can be viewed from the perspective of data management , wherein accuracy, consistency, and efficiency are a must. These files contain metadata, current state details, and other information useful in planning and applying changes to infrastructure.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















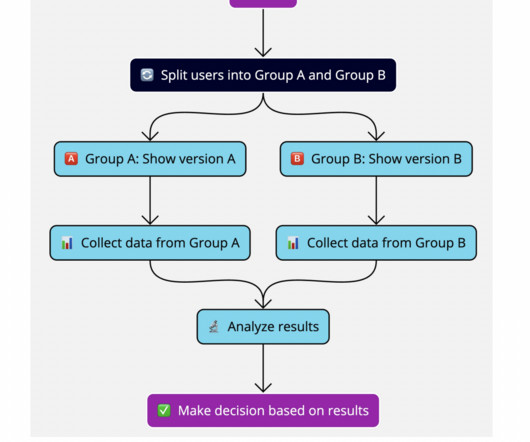

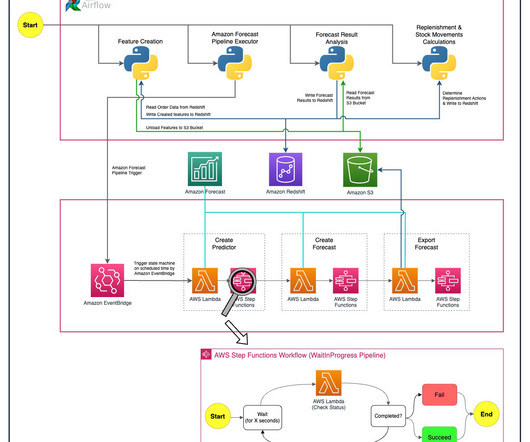
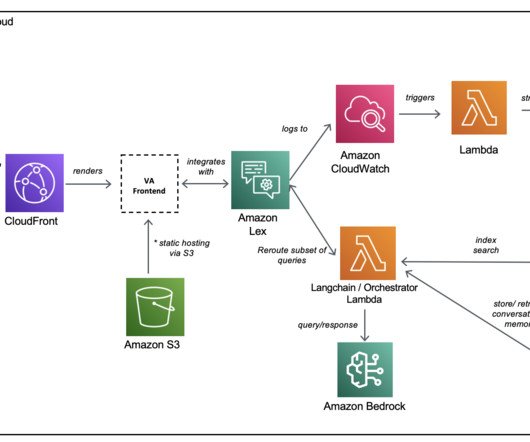
























Let's personalize your content