This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In 2025, open-source AI solutions will emerge as a dominant force in closing this gap, he explains. With so many examples of algorithmic bias leading to unwanted outputs and humans being, well, humans behavioural psychology will catch up to the AI train, explained Mortensen. The solutions?
Data privacy, data protection and data governance Adequate data protection frameworks and data governance mechanisms should be established or enhanced to ensure that the privacy and rights of individuals are maintained in line with legal guidelines around dataintegrity and personal data protection.
Lastly, balancing data volume and quality is an ongoing struggle. While massive, overly influential datasets can enhance model performance , they often include redundant or noisy information that dilutes effectiveness. This collaborative approach allows organizations to share knowledge without compromising sensitive information.
Data lineage becomes even more important as the need to provide “Explainability” in models is required by regulatory bodies. Enterprise data is often complex, diverse and scattered across various repositories, making it difficult to integrate into gen AI solutions.
That's an AI hallucination, where the AI fabricates incorrect information. The consequences of relying on inaccurate information can be severe for these industries. These tools help identify when AI makes up information or gives incorrect answers, even if they sound believable. What Are AI Hallucination Detection Tools?
Data scientists and engineers frequently collaborate on machine learning ML tasks, making incremental improvements, iteratively refining ML pipelines, and checking the model’s generalizability and robustness. To build a well-documented ML pipeline, data traceability is crucial. Examples of DATALORE utilization.
Documentation can also be generated and maintained with information such as a model’s data origins, training methods and behaviors. Security and privacy —When all data scientists and AI models are given access to data through a single point of entry, dataintegrity and security are improved.
In the rapidly evolving healthcare landscape, patients often find themselves navigating a maze of complex medical information, seeking answers to their questions and concerns. However, accessing accurate and comprehensible information can be a daunting task, leading to confusion and frustration.
Whether it's creating deepfake videos that distort the truth or generating deceptive texts, these technologies have the capacity to spread false information, encourage cyberbullying , and facilitate phishing schemes. Moreover, the proliferation of AI-generated content risks a decline in the overall quality of information.
A significant challenge in AI applications today is explainability. This enhances transparency and reliability, enabling businesses to make informed decisions with confidence. How does the knowledge graph architecture of the AI Context Engine enhance the accuracy and explainability of LLMs compared to SQL databases alone?
Summary In this blog post, we delve into the essential task of identifying anomalies within datasets, a critical step for improving dataintegrity and analysis accuracy. We start by defining what an outlier is and explain its importance in various fields (e.g., Citation Information Mangla, P. Huot, and P. Thakur, eds.,
This feature allows the model to keep track of previous interactions, recall relevant information, and provide more contextually appropriate responses. Concerns While advanced contextual awareness is beneficial, there are privacy concerns regarding the amount of personal data the AI needs to retain.
Context recall Ensures that the context contains all relevant information needed to answer the question. Higher scores mean the answer is complete and relevant, while lower scores indicate missing or redundant information. For more information, see Overview of access management: Permissions and policies.
Through a practical use case of processing a patient health package at a doctors office, you will see how this technology can extract and synthesize information from all three document types, potentially improving data accuracy and operational efficiency. For more information, see Create a guardrail.
With more than 16 years of experience, he provides strategic leadership in information security, covering products and infrastructure. Reliability is also paramountAI systems often support mission-critical tasks, and even minor downtime or data loss can lead to significant disruptions or flawed AI outputs. Aditya K Sood (Ph.D)
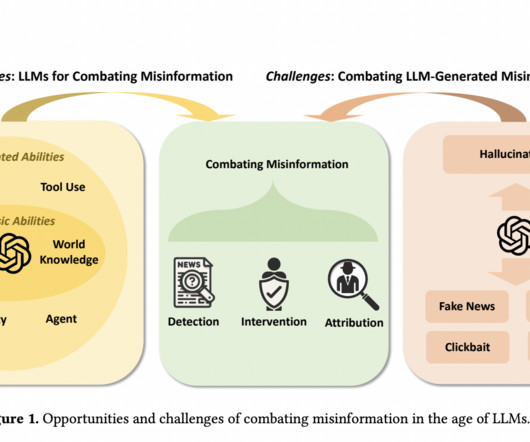
The spread of false information is an issue that has persisted in the modern digital era. The public’s trust in credible sources and the truth might be jeopardized due to the widespread dissemination of false information. It is crucial to fight disinformation to protect information ecosystems and maintain public trust.
Summary: The ETL process, which consists of data extraction, transformation, and loading, is vital for effective data management. Following best practices and using suitable tools enhances dataintegrity and quality, supporting informed decision-making. ETL stands for Extract, Transform, Load.
Gaining an understanding of available AI tools and their capabilities can assist you in making informed decisions when selecting a platform that aligns with your business objectives. Automated development: With AutoAI , beginners can quickly get started and more advanced data scientists can accelerate experimentation in AI development.
This article will analyse the functions of artificial intelligence and machine learning and how they can affect the data backup process. Still, we will discuss the importance of backups for the average user and explain the universal benefits of data management that AI improves. What is the Importance of Data Backup?
It’s possible to augment this basic process with OCR so the application can find data on paper forms, or to use natural language processing to gather information through a chat server. So from the start, we have a dataintegration problem compounded with a compliance problem. That’s the bad news.
So, instead of wandering the aisles in hopes you’ll stumble across the book, you can walk straight to it and get the information you want much faster. An enterprise data catalog does all that a library inventory system does – namely streamlining data discovery and access across data sources – and a lot more.
The tool also incorporates IP geolocation information, which enhances the user experience by tailoring website content to the visitor’s location and language. SEON SEON is an artificial intelligence fraud protection platform that uses real-time digital, social, phone, email, IP, and device data to improve risk judgments.
Among such leading organizations are research centers at the Indian Institute of Technology Madras (IIT Madras) and the Indraprastha Institute of Information Technology Delhi (IIIT-Delhi), intelligent life sciences company Innoplexus and AI-led medical diagnostics platform provider 5C Network.
Context Awareness: They are often equipped to understand the context in which they operate, using that information to tailor their responses and actions. By analyzing market data in real time, they support financial institutions in making more informed decisions. This makes them effective for straightforward, real-time tasks.
Every business, irrespective of the niche of operations is harnessing the power of data and make their strategies result-oriented. As compared to the earlier times, businesses are inundated with vast amounts of information. To harness this information in the best interest of the business, it is imperative to filter quality inputs.
The native traceability support informs the requesting application about the sources used to answer a question. For enterprise implementations, Knowledge Bases supports AWS Key Management Service (AWS KMS) encryption, AWS CloudTrail integration, and more. This data is information rich but can be vastly heterogenous.
They expect that information being provided, and derivative outputs are accurate while adhering to their original purpose ( integrity ). They expect information to be available when it is needed ( availability ). Data should be classified and safeguarded in ways that are appropriate given their reason for use.
Overview of Deep Learning Technologies: Deep learning plays an important role in autonomous driving, with CNNs being crucial for processing spatial information like images, replacing traditional handcrafted features with learned representations.
Over the course of his career, Erik has been at the forefront of integrating building large-scale platforms and integrating AI into search technologies, significantly enhancing user interaction and information accessibility. I have been immersed in the Information Retrieval domain throughout my entire career.
Critical thinking involves analyzing information, questioning assumptions, and making ethical judgments based on our values and understanding of context. AI can process data and identify patterns, but it doesn't have the human capacity for discernment, skepticism, and moral reasoning.
Can you explain how DecisionNext leverages AI and machine learning to improve commodity price and supply forecasting? DecisionNext uses artificial intelligence and machine learning to consume thousands of data sets and find historical and current relationships between key factors.
However, scaling up generative AI and making adoption easier for different lines of businesses (LOBs) comes with challenges around making sure data privacy and security, legal, compliance, and operational complexities are governed on an organizational level. For more information, see Monitor Amazon Bedrock with Amazon CloudWatch.
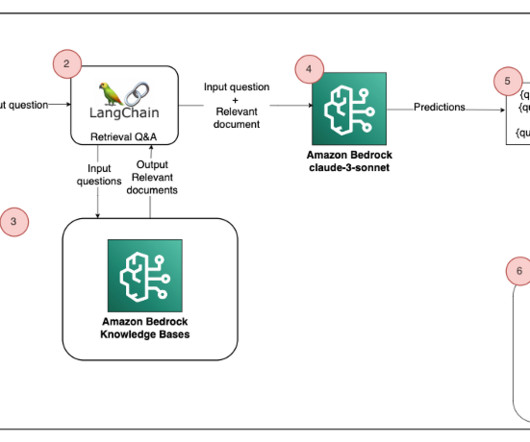
Now that weve explained the key features, we examine how these capabilities come together in a practical implementation. Feature overview The Amazon Bedrock Knowledge Bases RAG evaluation feature provides a comprehensive, end-to-end solution for assessing and optimizing RAG applications.
Encapsulation safeguards dataintegrity by restricting direct access to an object’s data and methods. Encapsulate Data: To safeguard dataintegrity, encapsulate data within classes and control access through well-defined interfaces and access modifiers.
Realizing the impact of these applications can provide enhanced insights to the customers and positively impact the performance efficiency in the organization, with easy information retrieval and automating certain time-consuming tasks. For more information about foundation models, see Getting started with Amazon SageMaker JumpStart.
This includes features for model explainability, fairness assessment, privacy preservation, and compliance tracking. Integration with ML tools and libraries: Provide you with flexibility and extensibility. Can you debug system information? Can you compare images? Can you customize the UI to your needs?
In this post, we explain how we built an end-to-end product category prediction pipeline to help commercial teams by using Amazon SageMaker and AWS Batch , reducing model training duration by 90%. For more information about how to get started building your own ML pipelines with SageMaker, see Amazon SageMaker resources.
Through the integration of Vertex AI with Google Earth Engine, users may gain access to sophisticated machine learning models and algorithms for more efficient analysis of Earth observation data. Users of Google Earth Engine may now easily access and examine Earth observation data that is stored in Google Cloud Platform (GCP) services.
The following blog will discuss the familiar Data Science challenges professionals face daily. It will focus on the challenges of Data Scientists, which include data cleaning, dataintegration, model selection, communication and choosing the right tools and techniques.
For users who are unfamiliar with Airflow, can you explain what makes it the ideal platform to programmatically author, schedule and monitor workflows? Airflow also has many dataintegrations with popular databases, applications, and tools, as well as dozens of cloud services — and more are added every month.
Challenge As AI becomes ubiquitous, it’s increasingly used to process information and interact with customers in a sensitive context. For example, the AI/ML governance team trusts the development teams are sending the correct bias and explainability reports for a given model. We use these values to retrieve the model package.
With the advent of big data in the modern world, RTOS is becoming increasingly important. As software expert Tim Mangan explains, a purpose-built real-time OS is more suitable for apps that involve tons of data processing. The Big Data and RTOS connection IoT and embedded devices are among the biggest sources of big data.
Based on the values of inputs or independent variables, these algorithms can make predictions about the dependent variable or classify output for the new input data based on this learned information. The Solution: XYZ Retail embarked on a transformative journey by integrating Machine Learning into its demand forecasting strategy.
Another area of advancement in bioinformatics is the integration of multi-omics data. Researchers can comprehensively understand biological systems by combining information from genomics, transcriptomics, proteomics, and other omics fields.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content