This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction to Data Engineering Data Engineering Challenges: Data engineering involves obtaining, organizing, understanding, extracting, and formatting data for analysis, a tedious and time-consuming task. Datascientists often spend up to 80% of their time on data engineering in data science projects.
For budding datascientists and data analysts, there are mountains of information about why you should learn R over Python and the other way around. Though both are great to learn, what gets left out of the conversation is a simple yet powerful programming language that everyone in the data science world can agree on, SQL.
Summary: This blog explores the key differences between ETL and ELT, detailing their processes, advantages, and disadvantages. Understanding these methods helps organizations optimize their data workflows for better decision-making. What is ETL? ETL stands for Extract, Transform, and Load.
However, efficient use of ETL pipelines in ML can help make their life much easier. This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for data engineers to enhance and sustain their pipelines.
Jay Mishra is the Chief Operating Officer (COO) at Astera Software , a rapidly-growing provider of enterprise-ready data solutions. Automation has been a key trend in the past few years and that ranges from the design to building of a data warehouse to loading and maintaining, all of that can be automated.
Datascientists and engineers frequently collaborate on machine learning ML tasks, making incremental improvements, iteratively refining ML pipelines, and checking the model’s generalizability and robustness. This improves DATALORE’s efficiency by avoiding the costly investigation of search spaces.
Data Science focuses on analysing data to find patterns and make predictions. Data engineering, on the other hand, builds the foundation that makes this analysis possible. Without well-structured data, DataScientists cannot perform their work efficiently.
You can optimize your costs by using data profiling to find any problems with data quality and content. Fixing poor data quality might otherwise cost a lot of money. The 18 best data profiling tools are listed below. It comes with an Informatica Data Explorer function to meet your data profiling requirements.
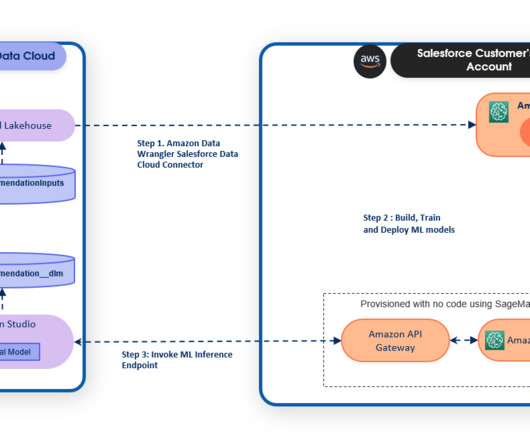
With this capability, businesses can access their Salesforce data securely with a zero-copy approach using SageMaker and use SageMaker tools to build, train, and deploy AI models. The inference endpoints are connected with Data Cloud to drive predictions in real time.
Unfolding the difference between data engineer, datascientist, and data analyst. Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Role of DataScientistsDataScientists are the architects of data analysis.
In contrast, data warehouses and relational databases adhere to the ‘Schema-on-Write’ model, where data must be structured and conform to predefined schemas before being loaded into the database. Schema Enforcement: Data warehouses use a “schema-on-write” approach.
This comprehensive guide covers practical frameworks to enable effective holistic scoping, planning, governance, and deployment of project management for data science. Proper management and strategic stakeholder alignment allow data science leaders to avoid common missteps and accelerate ROI.
The company’s H20 Driverless AI streamlines AI development and predictive analytics for professionals and citizen datascientists through open source and customized recipes. The platform makes collaborative data science better for corporate users and simplifies predictive analytics for professional datascientists.
They are responsible for building and maintaining data architectures, which include databases, data warehouses, and data lakes. Their work ensures that data flows seamlessly through the organisation, making it easier for DataScientists and Analysts to access and analyse information. from 2021 to 2026.
It covers essential skills like data cleaning, problem-solving, and data visualization using tools like SQL, Tableau, and R Programming. By completing the course, you’ll gain the skills to identify the appropriate data analytics strategy for various situations and understand your position within the analytics life cycle.
Business Applications: Big Data Analytics : Supporting advanced analytics, machine learning, and artificial intelligence applications. Data Archival : Storing historical data that might be needed for future analysis. Data Exploration : Allowing datascientists to explore and experiment with large datasets.
Unlike traditional databases, Data Lakes enable storage without the need for a predefined schema, making them highly flexible. Importance of Data Lakes Data Lakes play a pivotal role in modern data analytics, providing a platform for DataScientists and analysts to extract valuable insights from diverse data sources.
The objective is to guide businesses, Data Analysts, and decision-makers in choosing the right tool for their needs. Whether you aim for comprehensive dataintegration or impactful visual insights, this comparison will clarify the best fit for your goals. Power BI : Provides dynamic dashboards and reporting tools.
Students should learn about the architecture of data warehouses and how they differ from traditional databases. DataIntegration Tools Technologies such as Apache NiFi and Talend help in the seamless integration of data from various sources into a unified system for analysis.
A unified data fabric also enhances data security by enabling centralised governance and compliance management across all platforms. Automated DataIntegration and ETL Tools The rise of no-code and low-code tools is transforming dataintegration and Extract, Transform, and Load (ETL) processes.
During a data analysis project, I encountered a significant data discrepancy that threatened the accuracy of our analysis. I conducted thorough data validation, collaborated with stakeholders to identify the root cause, and implemented corrective measures to ensure dataintegrity.
Spark offered a more versatile programming model, supporting not only MapReduce-like batch processing but also real-time stream processing and interactive data queries. Its ability to efficiently handle iterative algorithms and machine learning tasks made it a popular choice for datascientists and engineers. Morgan Kaufmann.
Here we will upskill you with the Pandas library which stands as a highly favored asset amongst datascientists, facilitating seamless data manipulation and analysis. Alongside Matplotlib, a key tool for data visualization, and NumPy, the foundational library for scientific computing upon which Pandas was constructed.
He highlights innovations in data, infrastructure, and artificial intelligence and machine learning that are helping AWS customers achieve their goals faster, mine untapped potential, and create a better future. Learn more about the AWS zero-ETL future with newly launched AWS databases integrations with Amazon Redshift.
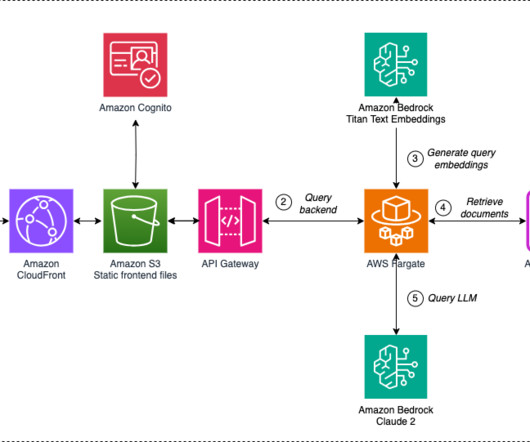
This is a guest post co-written with Vicente Cruz Mínguez, Head of Data and Advanced Analytics at Cepsa Química, and Marcos Fernández Díaz, Senior DataScientist at Keepler. The following diagram illustrates this architecture. Since 2023, he has also been working on scaling the use of generative AI in all departments.
When done well, data democratization empowers employees with tools that let everyone work with data, not just the datascientists. When workers get their hands on the right data, it not only gives them what they need to solve problems, but also prompts them to ask, “What else can I do with data?
It covers essential skills like data cleaning, problem-solving, and data visualization using tools like SQL, Tableau, and R Programming. By completing the course, you’ll gain the skills to identify the appropriate data analytics strategy for various situations and understand your position within the analytics life cycle.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content