This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When we talk about dataintegrity, we’re referring to the overarching completeness, accuracy, consistency, accessibility, and security of an organization’s data. Together, these factors determine the reliability of the organization’s data. In short, yes.
As a global leader in agriculture, Syngenta has led the charge in using datascience and machine learning (ML) to elevate customer experiences with an unwavering commitment to innovation. It facilitates real-time data synchronization and updates by using GraphQL APIs, providing seamless and responsive user experiences.
IBM Cloud Pak for Data Express solutions offer clients a simple on ramp to start realizing the business value of a modern architecture. Data governance. The data governance capability of a data fabric focuses on the collection, management and automation of an organization’s data. Dataintegration.
ETL ( Extract, Transform, Load ) Pipeline: It is a dataintegration mechanism responsible for extracting data from data sources, transforming it into a suitable format, and loading it into the data destination like a data warehouse. The pipeline ensures correct, complete, and consistent data.
With built-in components and integration with Google Cloud services, Vertex AI simplifies the end-to-end machine learning process, making it easier for datascience teams to build and deploy models at scale. Metaflow Metaflow helps data scientists and machine learning engineers build, manage, and deploy datascience projects.
The advent of big data, affordable computing power, and advanced machine learning algorithms has fueled explosive growth in datascience across industries. However, research shows that up to 85% of datascience projects fail to move beyond proofs of concept to full-scale deployment.
Summary: Choosing the right ETL tool is crucial for seamless dataintegration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Let’s unlock the power of ETL Tools for seamless data handling.
They excel at managing structured data and supporting ACID (Atomicity, Consistency, Isolation, Durability) transactions. Scalability: Relational databases can scale vertically by upgrading hardware, but horizontal scaling can be more challenging due to the need to maintain dataintegrity and relationships.
The right data architecture can help your organization improve data quality because it provides the framework that determines how data is collected, transported, stored, secured, used and shared for business intelligence and datascience use cases. Perform data quality monitoring based on pre-configured rules.
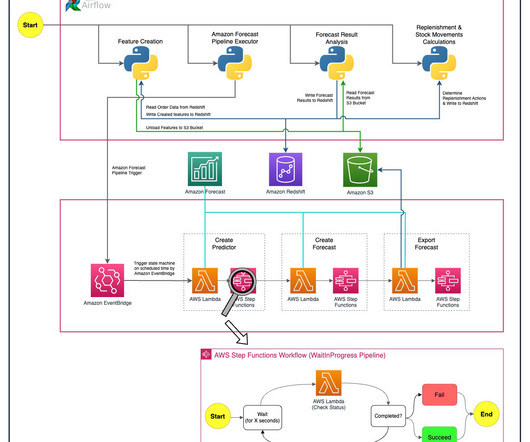
Solution overview Six people from Getir’s datascience team and infrastructure team worked together on this project. Deep/neural network algorithms also perform very well on sparse data set and in cold-start (new item introduction) scenarios. The following diagram shows the solution’s architecture.
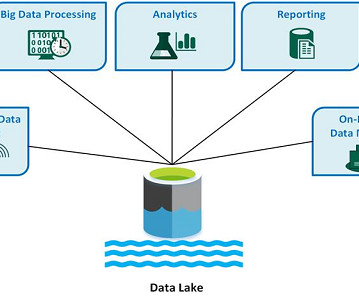
Data lakes are able to handle a diverse range of data types. From images, videos, text, and even sensor data. Then, there’s dataintegration. A data lake can also act as a central hub for integratingdata from various sources and systems within an organization.
However, scaling up generative AI and making adoption easier for different lines of businesses (LOBs) comes with challenges around making sure data privacy and security, legal, compliance, and operational complexities are governed on an organizational level. Tanvi Singhal is a Data Scientist within AWS Professional Services.
These files contain metadata, current state details, and other information useful in planning and applying changes to infrastructure. It helps to observe datascience principles in working with these files. They can provide encryption for passwords and other secrets to ensure state dataintegrity and confidentiality.
They enhance dataintegrity, security, and accessibility while providing tools for efficient data management and retrieval. A Database Management System (DBMS) is specialised software designed to efficiently manage and organise data within a computer system. Indices are data structures optimised for rapid data retrieval.
These are subject-specific subsets of the data warehouse, catering to the specific needs of departments like marketing or sales. They offer a focused selection of data, allowing for faster analysis tailored to departmental goals. Metadata This acts like the data dictionary, providing crucial information about the data itself.
Iris was designed to use machine learning (ML) algorithms to predict the next steps in building a data pipeline. By analyzing millions of metadata elements and data flows, Iris could make intelligent suggestions to users, democratizing dataintegration and allowing even those without a deep technical background to create complex workflows.
From financial services to e-commerce and telecommunications, organizations leverage Data Warehouses to unlock the full potential of their structured data for strategic advantage. What Is Data Lake Architecture? Delta Lake vs. Data Lake Delta Lake is an open-source storage layer that brings ACID transactions to Data Lakes.
Types of Data Profiling: Data profiling can be broadly categorized into three main types, each focusing on different aspects of the data: Structural Profiling: Structural profiling involves analyzing the structure and metadata of the data. It supports metadata analysis, data lineage, and data quality assessment.
This process involves real-time monitoring and documentation to provide visibility on the data quality, thereby helping the organization detect and address data-related issues. It is backed by sophisticated algorithms that empower the identification of budding data irregularities Simplify the amalgamation of data from diverse origins.
These include the database engine for executing queries, the query processor for interpreting SQL commands, the storage manager for handling physical data storage, and the transaction manager for ensuring dataintegrity through ACID properties. Data Independence: Changes in database structure do not affect application programs.
With the use of these tools, one can streamline the data modelling process. Moreover, these tools are designed to automate tasks like generating SQL scripts, documenting metadata and others. Improved Visualization Data modelling tools offer intuitive graphical representations of data models.
Introduction In today’s data-driven world, organizations generate approximately 2.5 quintillion bytes of data daily, highlighting the critical need for efficient data management. Database Management Systems (DBMS) serve as the backbone of data handling.
The primary purpose of a DBMS is to provide a systematic way to manage large amounts of data, ensuring that it is organised, accessible, and secure. By employing a DBMS, organisations can maintain dataintegrity, reduce redundancy, and streamline data operations, enabling more informed decision-making.
It requires sophisticated tools and algorithms to derive meaningful patterns and trends from the sheer magnitude of data. Meta DataMetadata, often dubbed “data about data,” provides essential context and descriptions for other datasets. To know more about Pickl.AI
Data Transparency Data Transparency is the pillar that ensures data is accessible and understandable to all stakeholders within an organization. This involves creating data dictionaries, documentation, and metadata. It provides clear insights into the data’s structure, meaning, and usage.
Online Processing: this type of data processing involves managing transactional data in real time and focuses on handling individual transaction. The systems are designed to ensure dataintegrity, concurrency and quick response times for enabling interactive user transactions. The DataScience courses provided by Pickl.AI
This includes removing duplicates, correcting typos, and standardizing data formats. It forms the bedrock of data quality improvement. Implement Data Validation Rules To maintain dataintegrity, establish strict validation rules. This ensures that the data entered meets predefined criteria.
The benefits of Databricks over Spark is Highly reliable and performant data pipelines and Productive datascience at scale — source: [link] Databricks also introduced Delta Lake, an open-source storage layer that brings reliability to data lakes. MapReduce: simplified data processing on large clusters.
So I was able to get from growth hacking to data analytics, then data analytics to datascience, and then datascience to MLOps. I switched from analytics to datascience, then to machine learning, then to data engineering, then to MLOps. How do I get this model in production?
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content