This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
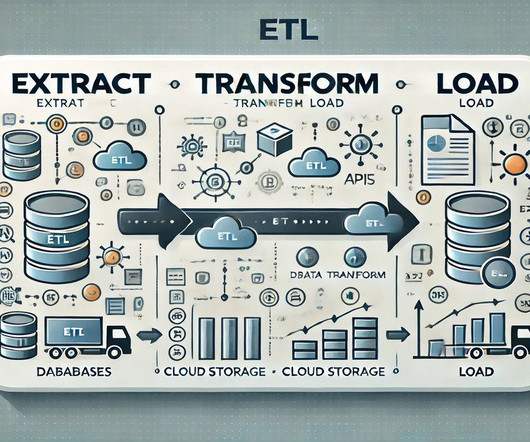
This article was published as a part of the DataScience Blogathon. Introduction to ETLETL is a type of three-step dataintegration: Extraction, Transformation, Load are processing, used to combine data from multiple sources. It is commonly used to build Big Data.
This article was published as a part of the DataScience Blogathon. Introduction Processing large amounts of raw data from various sources requires appropriate tools and solutions for effective dataintegration. Building an ETL pipeline using Apache […]. Building an ETL pipeline using Apache […].
This article was published as a part of the DataScience Blogathon. Introduction Azure data factory (ADF) is a cloud-based ETL (Extract, Transform, Load) tool and dataintegration service which allows you to create a data-driven workflow. In this article, I’ll show […].
Summary: Selecting the right ETL platform is vital for efficient dataintegration. Consider your business needs, compare features, and evaluate costs to enhance data accuracy and operational efficiency. These platforms extract data from various sources, transform it into usable formats, and load it into target systems.
Introduction to Data Engineering Data Engineering Challenges: Data engineering involves obtaining, organizing, understanding, extracting, and formatting data for analysis, a tedious and time-consuming task. Data scientists often spend up to 80% of their time on data engineering in datascience projects.
Summary: Choosing the right ETL tool is crucial for seamless dataintegration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Also Read: Top 10 DataScience tools for 2024.
Summary: The ETL process, which consists of data extraction, transformation, and loading, is vital for effective data management. Following best practices and using suitable tools enhances dataintegrity and quality, supporting informed decision-making. What is ETL? ETL stands for Extract, Transform, Load.
Summary: This article explores the significance of ETLData in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
Here comes the role of Data Mining. Read this blog to know more about DataIntegration in Data Mining, The process encompasses various techniques that help filter useful data from the resource. Moreover, dataintegration plays a crucial role in data mining.
Jay Mishra is the Chief Operating Officer (COO) at Astera Software , a rapidly-growing provider of enterprise-ready data solutions. What initially attracted you to computer science? What we have done is we have actually created this configuration where you are able to pick from a large list of options.
The advent of big data, affordable computing power, and advanced machine learning algorithms has fueled explosive growth in datascience across industries. However, research shows that up to 85% of datascience projects fail to move beyond proofs of concept to full-scale deployment.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. Big Data Technologies: Hadoop, Spark, etc. Read more to know.
They can contain structured, unstructured, or semi-structured data. These can include structured databases, log files, CSV files, transaction tables, third-party business tools, sensor data, etc. The data ecosystem is connected to company-defined data sources that can ingest historical data after a specified period.
Data Warehouses and Relational Databases It is essential to distinguish data lakes from data warehouses and relational databases, as each serves different purposes and has distinct characteristics. Schema Enforcement: Data warehouses use a “schema-on-write” approach. You can connect with her on Linkedin.
These technologies include the following: Data governance and management — It is crucial to have a solid data management system and governance practices to ensure data accuracy, consistency, and security. It is also important to establish data quality standards and strict access controls.
The right data architecture can help your organization improve data quality because it provides the framework that determines how data is collected, transported, stored, secured, used and shared for business intelligence and datascience use cases.
For budding data scientists and data analysts, there are mountains of information about why you should learn R over Python and the other way around. Though both are great to learn, what gets left out of the conversation is a simple yet powerful programming language that everyone in the datascience world can agree on, SQL.
Accordingly, the need for Data Profiling in ETL becomes important for ensuring higher data quality as per business requirements. The following blog will provide you with complete information and in-depth understanding on what is data profiling and its benefits and the various tools used in the method.
Then we have some other ETL processes to constantly land the past 5 years of data into the Datamarts. Then we have some other ETL processes to constantly land the past 5 years of data into the Datamarts. You can also get datascience training on-demand wherever you are with our Ai+ Training platform.
Additionally, Data Engineers implement quality checks, monitor performance, and optimise systems to handle large volumes of data efficiently. Differences Between Data Engineering and DataScience While Data Engineering and DataScience are closely related, they focus on different aspects of data.
IBM merged the critical capabilities of the vendor into its more contemporary Watson Studio running on the IBM Cloud Pak for Data platform as it continues to innovate. The platform makes collaborative datascience better for corporate users and simplifies predictive analytics for professional data scientists.
Introduction Data transformation plays a crucial role in data processing by ensuring that raw data is properly structured and optimised for analysis. Data transformation tools simplify this process by automating data manipulation, making it more efficient and reducing errors.
It covers essential skills like data cleaning, problem-solving, and data visualization using tools like SQL, Tableau, and R Programming. By completing the course, you’ll gain the skills to identify the appropriate data analytics strategy for various situations and understand your position within the analytics life cycle.
What Is a Data Warehouse? On the other hand, a Data Warehouse is a structured storage system designed for efficient querying and analysis. It involves the extraction, transformation, and loading (ETL) process to organize data for business intelligence purposes. It often serves as a source for Data Warehouses.
DataIntegration: Integratesdata from multiple sources, providing a comprehensive view for business intelligence. Consistency and Accuracy : Ensures high data quality with consistent formatting and validation. Rigid Structure : Less flexible in handling unstructured data compared to data lakes.
This blog explains how to build data pipelines and provides clear steps and best practices. From data collection to final delivery, we explore how these pipelines streamline processes, enhance decision-making capabilities, and ensure dataintegrity. What are Data Pipelines?
The objective is to guide businesses, Data Analysts, and decision-makers in choosing the right tool for their needs. Whether you aim for comprehensive dataintegration or impactful visual insights, this comparison will clarify the best fit for your goals. Power BI : Provides dynamic dashboards and reporting tools.
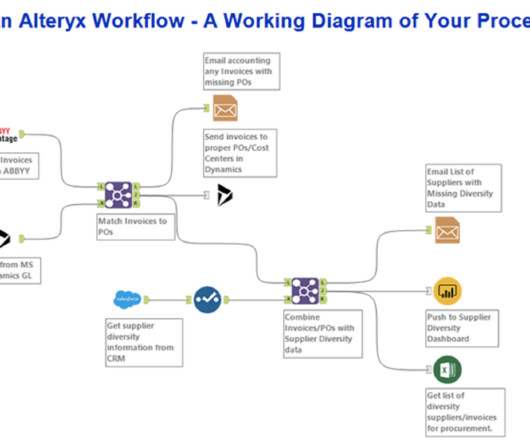
This user-friendly approach makes Alteryx suitable for a diverse user base, from data enthusiasts to business analysts. Streamlined DataIntegration Alteryx redefines the way organizations handle dataintegration. Is Alteryx an ETL tool? Yes, Alteryx is an ETL (Extract, Transform, Load) tool.
Introduction In today’s data-driven world, organizations generate approximately 2.5 quintillion bytes of data daily, highlighting the critical need for efficient data management. Database Management Systems (DBMS) serve as the backbone of data handling.
We created zpy to make synthetic data easy, by simplifying the simulation (sim) creation process and providing an easy way to generate synthetic data at scale. The library is centered on the following concetps: ETL : central framework to create data pipelines. Zpy is available in GitHub.
When data is organised hierarchically, queries can be optimised to aggregate data at various levels, improving performance and reducing processing time. Consistency in Reporting Hierarchies ensure that data is consistently structured across reports. organisational structures, product categories).
During a data analysis project, I encountered a significant data discrepancy that threatened the accuracy of our analysis. I conducted thorough data validation, collaborated with stakeholders to identify the root cause, and implemented corrective measures to ensure dataintegrity. 10% group discount available.
This includes removing duplicates, correcting typos, and standardizing data formats. It forms the bedrock of data quality improvement. Implement Data Validation Rules To maintain dataintegrity, establish strict validation rules. This ensures that the data entered meets predefined criteria.
Whether you’re working on Data Analysis, Machine Learning, or any other data-related task, having a well-organized Importing Data in Python Cheat Sheet for importing data in Python is invaluable. So, let me present to you an Importing Data in Python Cheat Sheet which will make your life easier.
It provided a platform for big data processing and machine learning, simplifying the process of building and deploying data pipelines. Delta Lake provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing. It helps data engineering teams by simplifying ETL development and management.
Students should learn about the architecture of data warehouses and how they differ from traditional databases. DataIntegration Tools Technologies such as Apache NiFi and Talend help in the seamless integration of data from various sources into a unified system for analysis.
Typically, data is gathered over a predetermined period of time, and the batch is subsequently processed as a whole. When there is a delay in the availability of data for analysis and real-time processing is not necessary, this method works well.
Managing Slowly Changing Dimensions (SCDs) When dimensions change over time, it can impact the accuracy of historical data. Use slowly changing dimension (SCD) techniques to capture historical changes and maintain dataintegrity. These tools help streamline the design process and ensure consistency.
A unified data fabric also enhances data security by enabling centralised governance and compliance management across all platforms. Automated DataIntegration and ETL Tools The rise of no-code and low-code tools is transforming dataintegration and Extract, Transform, and Load (ETL) processes.
Read Blogs: Crucial Statistics Interview Questions for DataScience Success. MongoDB is a NoSQL database that handles large-scale data and modern application requirements. Unlike traditional relational databases, MongoDB stores data in flexible, JSON-like documents, allowing for dynamic schemas. What is MongoDB?
Iris was designed to use machine learning (ML) algorithms to predict the next steps in building a data pipeline. By analyzing millions of metadata elements and data flows, Iris could make intelligent suggestions to users, democratizing dataintegration and allowing even those without a deep technical background to create complex workflows.
Let’s delve into the key components that form the backbone of a data warehouse: Source Systems These are the operational databases, CRM systems, and other applications that generate the raw data feeding the data warehouse. Data Extraction, Transformation, and Loading (ETL) This is the workhorse of architecture.
It covers essential skills like data cleaning, problem-solving, and data visualization using tools like SQL, Tableau, and R Programming. By completing the course, you’ll gain the skills to identify the appropriate data analytics strategy for various situations and understand your position within the analytics life cycle.
Following these steps, applications can efficiently connect to various databases using ODBC, making it a powerful dataintegration and management tool. ODBC supports standard SQL syntax, enabling developers to perform various operations such as retrieving, inserting, updating, and deleting data.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content