This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When we talk about dataintegrity, we’re referring to the overarching completeness, accuracy, consistency, accessibility, and security of an organization’s data. Together, these factors determine the reliability of the organization’s data. In short, yes.
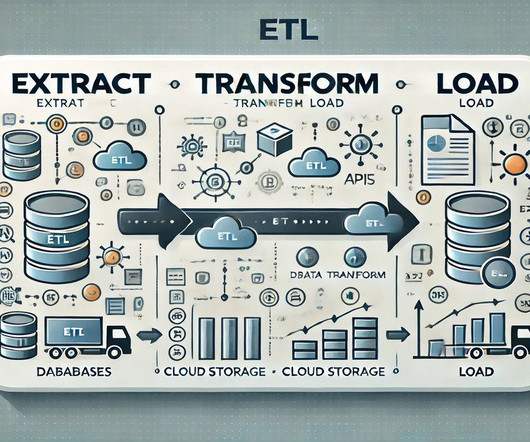
This article was published as a part of the DataScience Blogathon. Introduction Processing large amounts of raw data from various sources requires appropriate tools and solutions for effective dataintegration. Building an ETL pipeline using Apache […].
This article was published as a part of the DataScience Blogathon. Introduction to ETL ETL is a type of three-step dataintegration: Extraction, Transformation, Load are processing, used to combine data from multiple sources. It is commonly used to build Big Data.
This article was published as a part of the DataScience Blogathon. Introduction Azure Synapse Analytics is a cloud-based service that combines the capabilities of enterprise data warehousing, big data, dataintegration, data visualization and dashboarding.
This article was published as a part of the DataScience Blogathon. Introduction Azure data factory (ADF) is a cloud-based ETL (Extract, Transform, Load) tool and dataintegration service which allows you to create a data-driven workflow. In this article, I’ll show […].
It helps you manage and use data effectively, but how exactly? Cloud computing helps with datascience in various ways when you look deeper into its role. The Role of Cloud Computing in DataScienceData scientists use cloud computing for several reasons. That’s where cloud computing comes into effect.
Fermata , a trailblazer in datascience and computer vision for agriculture, has raised $10 million in a Series A funding round led by Raw Ventures. DataIntegration and Scalability: Integrates with existing sensors and data systems to provide a unified view of crop health.
This is creating a major headache for corporate datascience teams who have had to increasingly focus their limited resources on cleaning and organizing data. In a recent state of engineering report conducted by DBT , 57% of datascience professionals cited poor data quality as a predominant issue in their work.
Artificial Intelligence (AI) stands at the forefront of transforming data governance strategies, offering innovative solutions that enhance dataintegrity and security. By analyzing historical data patterns, AI can forecast potential risks and offer insights that help you preemptively adjust your strategies.
Be sure to check out her talk, “ Power trusted AI/ML Outcomes with DataIntegrity ,” there! Due to the tsunami of data available to organizations today, artificial intelligence (AI) and machine learning (ML) are increasingly important to businesses seeking competitive advantage through digital transformation.
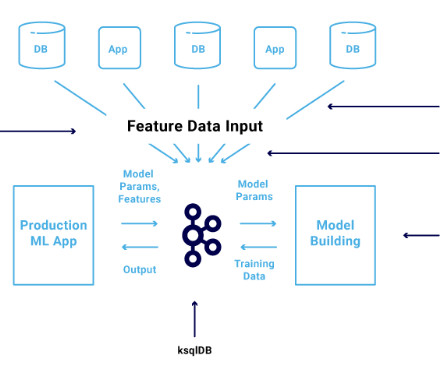
This capability will provide data users with visibility into origin, transformations, and destination of data as it is used to build products. The result is more useful data for decision-making, less hassle and better compliance. Dataintegration. Datascience and MLOps. Start a trial. Start a trial.
Here comes the role of Data Mining. Read this blog to know more about DataIntegration in Data Mining, The process encompasses various techniques that help filter useful data from the resource. Moreover, dataintegration plays a crucial role in data mining.
Summary: The DataScience and Data Analysis life cycles are systematic processes crucial for uncovering insights from raw data. Quality data is foundational for accurate analysis, ensuring businesses stay competitive in the digital landscape. Understanding their life cycles is critical to unlocking their potential.
The advent of big data, affordable computing power, and advanced machine learning algorithms has fueled explosive growth in datascience across industries. However, research shows that up to 85% of datascience projects fail to move beyond proofs of concept to full-scale deployment.
Summary: Selecting the right ETL platform is vital for efficient dataintegration. Consider your business needs, compare features, and evaluate costs to enhance data accuracy and operational efficiency. Introduction In today’s data-driven world, businesses rely heavily on ETL platforms to streamline dataintegration processes.
Figure 3: Implementing the Solution Stack with IBM Data and AI Implementation across the full lifecycle covers: Create : Ingest source data sets and feeds and transform these into data product assets using hybrid cloud lakehouse technology with integrateddatascience and AI development environments.
DataScience helps businesses uncover valuable insights and make informed decisions. But for it to be functional, programming languages play an integral role. Programming for DataScience enables Data Scientists to analyze vast amounts of data and extract meaningful information.
Demand forecasting, powered by datascience, helps predict customer needs. Optimize inventory, streamline operations, and make data-driven decisions for success. DataScience empowers businesses to leverage the power of data for accurate and insightful demand forecasts.
Check for Duplicates Before Updating/Inserting To maintain dataintegrity, it’s crucial to prevent duplicate records in your database. Maintain DataIntegrityDataintegrity checks should include validating data types to ensure seamless interactions with MongoDB. Happy coding and database exploration!
Dataintegration in different spectrums of life highlights its growing significance. It has become a driving force of transformation, and so a career in DataScience is flourishing. The role of DataScience is not just limited to the IT domain. Why Should You Prepare for DataScience in High School?
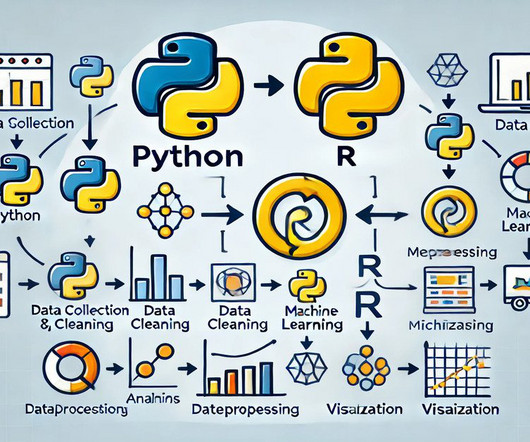
Summary : Combining Python and R enriches DataScience workflows by leveraging Python’s Machine Learning and data handling capabilities alongside R’s statistical analysis and visualisation strengths. Python excels in Machine Learning, automation, and data processing, while R shines in statistical analysis and visualisation.
Douwe Osinga and Jack Amadeo were working together at Sidewalk Labs , Alphabet’s venture to build tech-forward cities, when they arrived at the conclusion that most spreadsheet software doesn’t scale up to today’s data challenges.
Introduction : Microsoft Fabric is a cloud-based platform that offers a unified datascience, data engineering, and business intelligence experience. It provides a variety of features and services, such as data preparation, machine learning, and visualization. Create a new Lakehouse Upload files from your local device.
Together, data engineers, data scientists, and machine learning engineers form a cohesive team that drives innovation and success in data analytics and artificial intelligence. Their collective efforts are indispensable for organizations seeking to harness data’s full potential and achieve business growth.
Summary: Choosing the right ETL tool is crucial for seamless dataintegration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Let’s unlock the power of ETL Tools for seamless data handling.
Introduction to Data Engineering Data Engineering Challenges: Data engineering involves obtaining, organizing, understanding, extracting, and formatting data for analysis, a tedious and time-consuming task. Data scientists often spend up to 80% of their time on data engineering in datascience projects.
AI platforms offer a wide range of capabilities that can help organizations streamline operations, make data-driven decisions, deploy AI applications effectively and achieve competitive advantages. Visual modeling: Combine visual datascience with open source libraries and notebook-based interfaces on a unified data and AI studio.
In the following example, we use Python, the beloved programming language of the data scientist, for model training, and a robust and scalable Java application for real-time model predictions. You can also get datascience training on-demand wherever you are with our Ai+ Training platform.
Drawbacks: Latency: Fetching and processing external data can slow down response times. Dependency on Retrievers: Performance hinges on the quality and relevance of retrieved data. Integration Complexity: Requires seamless integration between the retriever and generator components.
Jay Mishra is the Chief Operating Officer (COO) at Astera Software , a rapidly-growing provider of enterprise-ready data solutions. What initially attracted you to computer science? What we have done is we have actually created this configuration where you are able to pick from a large list of options.
For budding data scientists and data analysts, there are mountains of information about why you should learn R over Python and the other way around. Though both are great to learn, what gets left out of the conversation is a simple yet powerful programming language that everyone in the datascience world can agree on, SQL.
With built-in components and integration with Google Cloud services, Vertex AI simplifies the end-to-end machine learning process, making it easier for datascience teams to build and deploy models at scale. Metaflow Metaflow helps data scientists and machine learning engineers build, manage, and deploy datascience projects.
Handling Large Data Volumes: Companies need scalable storage systems and cloud-based platforms to store and process massive amounts of data. Cloud services like AWS and Google Cloud help businesses manage their data efficiently. Businesses need strong data management strategies to merge and organise this data correctly.
They excel at managing structured data and supporting ACID (Atomicity, Consistency, Isolation, Durability) transactions. Scalability: Relational databases can scale vertically by upgrading hardware, but horizontal scaling can be more challenging due to the need to maintain dataintegrity and relationships.
These technologies include the following: Data governance and management — It is crucial to have a solid data management system and governance practices to ensure data accuracy, consistency, and security. It is also important to establish data quality standards and strict access controls.
He joined Getir in 2019 and currently works as a Senior DataScience & Analytics Manager. His team is responsible for designing, implementing, and maintaining end-to-end machine learning algorithms and data-driven solutions for Getir. He then joined Getir in 2019 and currently works as DataScience & Analytics Manager.
Integration with Programming Languages: DuckDB works as a standalone CLI application and has clients for multiple programming languages, including Python, R, Java, and WebAssembly (Wasm). It integrates well with datascience tools like pandas and dplyr, allowing users to run queries directly on data frames without importing or copying data.
Multimodal DataIntegration isCritical Relying solely on structured EHR data risks missing up to 80% of patient context. Combining notes, lab results, imaging data, and prescription histories give a fuller picturevital for accurate risk prediction and decisionsupport. transforming how clinicians interact withdata.
Overview of solution Five people from Getir’s datascience team and infrastructure team worked together on this project. He joined Getir in 2019 and currently works as a Senior DataScience & Analytics Manager. We used GPU jobs that help us run jobs that use an instance’s GPUs.
Vertex AI assimilates workflows from datascience, data engineering, and machine learning to help your teams work together with a shared toolkit and grow your apps with the help of Google Cloud. They can also take advantage of extra GCP features for data processing and analysis thanks to this connection.
DataScience is the process in which collecting, analysing and interpreting large volumes of data helps solve complex business problems. A Data Scientist is responsible for analysing and interpreting the data, ensuring it provides valuable insights that help in decision-making.
These can include structured databases, log files, CSV files, transaction tables, third-party business tools, sensor data, etc. The pipeline ensures correct, complete, and consistent data. The data ecosystem is connected to company-defined data sources that can ingest historical data after a specified period.
Fraud.net Fraud.net’s AI and Machine Learning Models use deep learning, neural networks, and datascience methodologies to improve insights for various industries, including financial services, e-commerce, travel and hospitality, insurance, etc.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content