This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary: Dataquality is a fundamental aspect of Machine Learning. Poor-qualitydata leads to biased and unreliable models, while high-qualitydata enables accurate predictions and insights. What is DataQuality in Machine Learning? Bias in data can result in unfair and discriminatory outcomes.
In this post, we demonstrate how data aggregated within the AWS CCI Post Call Analytics solution allowed Principal to gain visibility into their contact center interactions, better understand the customer journey, and improve the overall experience between contact channels while also maintaining dataintegrity and security.
This “write once, run anywhere” capability allows developers to create applications that are not tied to a specific operating system, increasing portability and flexibility. Key Features of Scala DataIntegration and Management: SAS provides robust tools for dataintegration, cleansing, and transformation.
YData By enhancing the caliber of training datasets, YData offers a data-centric platform that speeds up the creation and raises the return on investment of AI solutions. Data scientists can now enhance datasets using cutting-edge synthetic data generation and automated dataquality profiling.
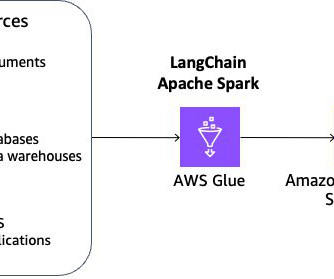
The benefits of this solution are: You can flexibly achieve data cleaning, sanitizing, and dataquality management in addition to chunking and embedding. You can build and manage an incremental data pipeline to update embeddings on Vectorstore at scale. Savio Dsouza is a SoftwareDevelopment Manager on the AWS Glue team.
Next, technical interventions are incorporated into our internal processes that focus on high-quality, unbiased data, with measures to ensure dataintegrity and fairness. Integrating GenAI into Agile practices is transforming how teams work. Our platform is built around the principles of responsible and mindful AI.
Their data pipeline (as shown in the following architecture diagram) consists of ingestion, storage, ETL (extract, transform, and load), and a data governance layer. Multi-source data is initially received and stored in an Amazon Simple Storage Service (Amazon S3) data lake.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













Let's personalize your content