This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Compiling data from these disparate systems into one unified location. This is where dataintegration comes in! Dataintegration is the process of combining information from multiple sources to create a consolidated dataset. Dataintegration tools consolidate this data, breaking down silos.
Compiling data from these disparate systems into one unified location. This is where dataintegration comes in! Dataintegration is the process of combining information from multiple sources to create a consolidated dataset. Dataintegration tools consolidate this data, breaking down silos.
In quality control, an outlier could indicate a defect in a manufacturing process. By understanding and identifying outliers, we can improve dataquality, make better decisions, and gain deeper insights into the underlying patterns of the data. finance, healthcare, and quality control).
Summary: Choosing the right ETL tool is crucial for seamless dataintegration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high dataquality, and informed decision-making capabilities. Also Read: Top 10 Data Science tools for 2024.
For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc., Dolt allows you to version (integration with DVC) and manage structured data, making tracking changes, collaborating, and maintaining dataintegrity easier.
Table Search and Filtering: Integrated search and filtering functionalities allow users to find specific columns or values and filter data to spot trends and identify essential values. Enhanced Python Features: New Python coding capabilities include an interactive debugger, error highlighting, and enhanced code navigation features.
. “It all starts with our upstream collaboration on data—connecting watsonx.data with Salesforce Data Cloud. ” Dataintegration fuels AI agents The partnership also plans to incorporate AI agents into Slack, Salesforce’s workplace communication platform. ” he noted.
Looking for an effective and handy Python code repository in the form of Importing Data in Python Cheat Sheet? Your journey ends here where you will learn the essential handy tips quickly and efficiently with proper explanations which will make any type of data importing journey into the Python platform super easy.
Data modelling is crucial for structuring data effectively. It reduces redundancy, improves dataintegrity, and facilitates easier access to data. Key components of data warehousing include: ETL Processes: ETL stands for Extract, Transform, Load. ETL is vital for ensuring dataquality and integrity.
However, some core responsibilities include Data Warehousing and Management Designing and maintaining data warehouses and data marts to support Data Analysis and reporting. Ensuring dataintegrity and security. Identifying and resolving dataquality issues. What Are Key Skills for A BI Analyst?
Summary: The ETL process, which consists of data extraction, transformation, and loading, is vital for effective data management. Following best practices and using suitable tools enhances dataintegrity and quality, supporting informed decision-making. What is ETL? ETL stands for Extract, Transform, Load.
This blog explains how to build data pipelines and provides clear steps and best practices. From data collection to final delivery, we explore how these pipelines streamline processes, enhance decision-making capabilities, and ensure dataintegrity. What are Data Pipelines?
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. TensorFlow, Scikit-learn, Pandas, NumPy, Jupyter, etc.
Additionally, you will work closely with cross-functional teams, translating complex data insights into actionable recommendations that can significantly impact business strategies and drive overall success. Also Read: Explore data effortlessly with Python Libraries for (Partial) EDA: Unleashing the Power of Data Exploration.
This comprehensive guide covers practical frameworks to enable effective holistic scoping, planning, governance, and deployment of project management for data science. Proper management and strategic stakeholder alignment allow data science leaders to avoid common missteps and accelerate ROI.
Scalability : A data pipeline is designed to handle large volumes of data, making it possible to process and analyze data in real-time, even as the data grows. Dataquality : A data pipeline can help improve the quality of data by automating the process of cleaning and transforming the data.
There are different programming languages and in this article, we will explore 8 programming languages that play a crucial role in the realm of Data Science. 8 Most Used Programming Languages for Data Science 1. Python: Versatile and Robust Python is one of the future programming languages for Data Science.
The data professionals deploy different techniques and operations to derive valuable information from the raw and unstructured data. The objective is to enhance the dataquality and prepare the data sets for the analysis. What is Data Manipulation? Data manipulation is crucial for several reasons.
The following blog will discuss the familiar Data Science challenges professionals face daily. It will focus on the challenges of Data Scientists, which include data cleaning, dataintegration, model selection, communication and choosing the right tools and techniques.
Schema-Free Learning: why we do not need schemas anymore in the data and learning capabilities to make the data “clean” This does not mean that dataquality is not important, data cleaning will still be very crucial, but data in a schema/table is no longer requirement or pre-requisite for any learning and analytics purposes.
Data Processing: Performing computations, aggregations, and other data operations to generate valuable insights from the data. DataIntegration: Combining data from multiple sources to create a unified view for analysis and decision-making.
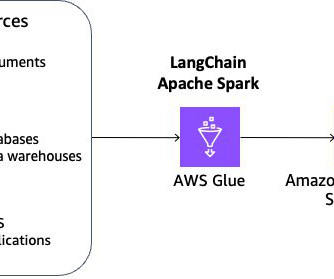
Apache Spark A fast, in-memory data processing engine that provides support for various programming languages, including Python, Java, and Scala. Data Warehousing Solutions Tools like Amazon Redshift, Google BigQuery, and Snowflake enable organisations to store and analyse large volumes of data efficiently.
During a data analysis project, I encountered a significant data discrepancy that threatened the accuracy of our analysis. I conducted thorough data validation, collaborated with stakeholders to identify the root cause, and implemented corrective measures to ensure dataintegrity. 10% group discount available.
Not only does it involve the process of collecting, storing, and processing data so that it can be used for analysis and decision-making, but these professionals are responsible for building and maintaining the infrastructure that makes this possible; and so much more. Think of it as like being a data doctor.
The project I did to land my business intelligence internship — CAR BRAND SEARCH ETL PROCESS WITH PYTHON, POSTGRESQL & POWER BI 1. Section 3: The technical section for the project where Python and pgAdmin4 will be used. Section 4: Reporting data for the project insights. Figure 3: Car Brand search ETL diagram 2.1.
Here are some specific reasons why they are important: DataIntegration: Organizations can integratedata from various sources using ETL pipelines. This provides data scientists with a unified view of the data and helps them decide how the model should be trained, values for hyperparameters, etc.
Job Submission and Cluster Management: To take advantage of Hadoop, you generally use the Hadoop API to generate code in Java, Python, or other compatible languages. When other big data technologies are integrated into the Hadoop ecosystem, the complexity grows. The reduction phase output usually gets saved to a file in HDFS.
Key challenges include data storage, processing speed, scalability, and security and compliance. What is the Role of Zookeeper in Big Data? How Do You Ensure DataQuality in a Big Data Project? Data validation, cleansing techniques, and monitoring tools are used to maintain accuracy and consistency.
It helps in standardizing the text data, reducing its dimensionality, and extracting meaningful features for machine learning models. LLMs require a large amount of data to be trained and fine-tuned, and managing this data is critical to the success of the deployment.
The benefits of this solution are: You can flexibly achieve data cleaning, sanitizing, and dataquality management in addition to chunking and embedding. You can build and manage an incremental data pipeline to update embeddings on Vectorstore at scale. You can choose a wide variety of embedding models.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content