This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The ability to effectively deploy AI into production rests upon the strength of an organization’s data strategy because AI is only as strong as the data that underpins it. This situation will exacerbate data silos, increase pressure to manage cloud costs efficiently and complicate governance of AI and data workloads.
Organizations require reliable data for robust AI models and accurate insights, yet the current technology landscape presents unparalleled dataquality challenges. Unified, governed data can also be put to use for various analytical, operational and decision-making purposes. There are several styles of dataintegration.
Compiling data from these disparate systems into one unified location. This is where dataintegration comes in! Dataintegration is the process of combining information from multiple sources to create a consolidated dataset. Dataintegration tools consolidate this data, breaking down silos.
Compiling data from these disparate systems into one unified location. This is where dataintegration comes in! Dataintegration is the process of combining information from multiple sources to create a consolidated dataset. Dataintegration tools consolidate this data, breaking down silos.
Poor dataquality is one of the top barriers faced by organizations aspiring to be more data-driven. Ill-timed business decisions and misinformed business processes, missed revenue opportunities, failed business initiatives and complex data systems can all stem from dataquality issues.
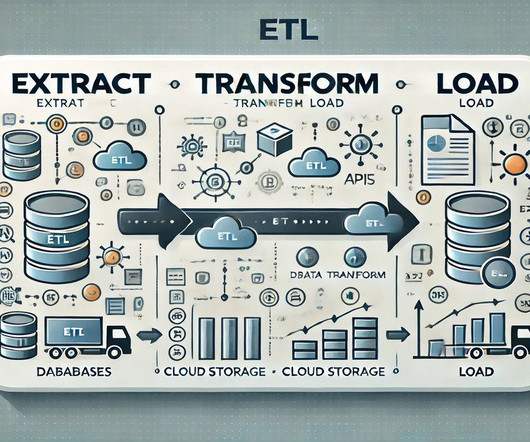
Summary: Selecting the right ETL platform is vital for efficient dataintegration. Consider your business needs, compare features, and evaluate costs to enhance data accuracy and operational efficiency. These platforms extract data from various sources, transform it into usable formats, and load it into target systems.
Summary: Choosing the right ETL tool is crucial for seamless dataintegration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high dataquality, and informed decision-making capabilities. Also Read: Top 10 Data Science tools for 2024.
Summary: This blog explores the key differences between ETL and ELT, detailing their processes, advantages, and disadvantages. Understanding these methods helps organizations optimize their data workflows for better decision-making. What is ETL? ETL stands for Extract, Transform, and Load.
Summary: This article explores the significance of ETLData in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
Summary: The ETL process, which consists of data extraction, transformation, and loading, is vital for effective data management. Following best practices and using suitable tools enhances dataintegrity and quality, supporting informed decision-making. What is ETL?
Here comes the role of Data Mining. Read this blog to know more about DataIntegration in Data Mining, The process encompasses various techniques that help filter useful data from the resource. Moreover, dataintegration plays a crucial role in data mining.
However, efficient use of ETL pipelines in ML can help make their life much easier. This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for data engineers to enhance and sustain their pipelines.
In addition, organizations that rely on data must prioritize dataquality review. Data profiling is a crucial tool. For evaluating dataquality. Data profiling gives your company the tools to spot patterns, anticipate consumer actions, and create a solid data governance plan.
Beyond Scale: DataQuality for AI Infrastructure The trajectory of AI over the past decade has been driven largely by the scale of data available for training and the ability to process it with increasingly powerful compute & experimental models. Another challenge is dataintegration and consistency.
Jay Mishra is the Chief Operating Officer (COO) at Astera Software , a rapidly-growing provider of enterprise-ready data solutions. Automation has been a key trend in the past few years and that ranges from the design to building of a data warehouse to loading and maintaining, all of that can be automated.
Dataquality plays a significant role in helping organizations strategize their policies that can keep them ahead of the crowd. Hence, companies need to adopt the right strategies that can help them filter the relevant data from the unwanted ones and get accurate and precise output.
They can contain structured, unstructured, or semi-structured data. These can include structured databases, log files, CSV files, transaction tables, third-party business tools, sensor data, etc. The data ecosystem is connected to company-defined data sources that can ingest historical data after a specified period.
However, analysis of data may involve partiality or incorrect insights in case the dataquality is not adequate. Accordingly, the need for Data Profiling in ETL becomes important for ensuring higher dataquality as per business requirements. What is Data Profiling in ETL?
Summary: Data transformation tools streamline data processing by automating the conversion of raw data into usable formats. These tools enhance efficiency, improve dataquality, and support Advanced Analytics like Machine Learning.
Data Warehouses and Relational Databases It is essential to distinguish data lakes from data warehouses and relational databases, as each serves different purposes and has distinct characteristics. Schema Enforcement: Data warehouses use a “schema-on-write” approach.
These technologies include the following: Data governance and management — It is crucial to have a solid data management system and governance practices to ensure data accuracy, consistency, and security. It is also important to establish dataquality standards and strict access controls.
Data modelling is crucial for structuring data effectively. It reduces redundancy, improves dataintegrity, and facilitates easier access to data. It enables reporting and Data Analysis and provides a historical data record that can be used for decision-making. from 2021 to 2026.
Scalability : A data pipeline is designed to handle large volumes of data, making it possible to process and analyze data in real-time, even as the data grows. Dataquality : A data pipeline can help improve the quality of data by automating the process of cleaning and transforming the data.
The diversity of data sources allows organizations to create a comprehensive view of their operations and market conditions. DataIntegration Once data is collected from various sources, it needs to be integrated into a cohesive format. What Are Some Common Tools Used in Business Intelligence Architecture?
Summary: Data ingestion is the process of collecting, importing, and processing data from diverse sources into a centralised system for analysis. This crucial step enhances dataquality, enables real-time insights, and supports informed decision-making. It provides a user-friendly interface for designing data flows.
This comprehensive guide covers practical frameworks to enable effective holistic scoping, planning, governance, and deployment of project management for data science. Proper management and strategic stakeholder alignment allow data science leaders to avoid common missteps and accelerate ROI.
This blog explains how to build data pipelines and provides clear steps and best practices. From data collection to final delivery, we explore how these pipelines streamline processes, enhance decision-making capabilities, and ensure dataintegrity. What are Data Pipelines?
However, some core responsibilities include Data Warehousing and Management Designing and maintaining data warehouses and data marts to support Data Analysis and reporting. Ensuring dataintegrity and security. Identifying and resolving dataquality issues.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Warehousing: Amazon Redshift, Google BigQuery, etc.
Cost-Effective: Generally more cost-effective than traditional data warehouses for storing large amounts of data. Cons: Complexity: Managing and securing a data lake involves intricate tasks that require careful planning and execution. DataQuality: Without proper governance, dataquality can become an issue.
What Is a Data Warehouse? On the other hand, a Data Warehouse is a structured storage system designed for efficient querying and analysis. It involves the extraction, transformation, and loading (ETL) process to organize data for business intelligence purposes. It often serves as a source for Data Warehouses.
When data is organised hierarchically, queries can be optimised to aggregate data at various levels, improving performance and reducing processing time. Consistency in Reporting Hierarchies ensure that data is consistently structured across reports. organisational structures, product categories).
The project I did to land my business intelligence internship — CAR BRAND SEARCH ETL PROCESS WITH PYTHON, POSTGRESQL & POWER BI 1. Section 2: Explanation of the ETL diagram for the project. Section 4: Reporting data for the project insights. ETL ARCHITECTURE DIAGRAM ETL stands for Extract, Transform, Load.
Example: Amazon Implementation: Amazon employs integration of information interfaced by its online shopping platform, Alexa conversations, and usage of Prime Video service, among others. Tools Used: AWS glue for dataintegration and transformation. Data Storage: Keeping altered data within Azure Synapse’s enrichment layer.
Additionally, it addresses common challenges and offers practical solutions to ensure that fact tables are structured for optimal dataquality and analytical performance. Introduction In today’s data-driven landscape, organisations are increasingly reliant on Data Analytics to inform decision-making and drive business strategies.
Schema-Free Learning: why we do not need schemas anymore in the data and learning capabilities to make the data “clean” This does not mean that dataquality is not important, data cleaning will still be very crucial, but data in a schema/table is no longer requirement or pre-requisite for any learning and analytics purposes.
During a data analysis project, I encountered a significant data discrepancy that threatened the accuracy of our analysis. I conducted thorough data validation, collaborated with stakeholders to identify the root cause, and implemented corrective measures to ensure dataintegrity.
Students should learn about the architecture of data warehouses and how they differ from traditional databases. DataIntegration Tools Technologies such as Apache NiFi and Talend help in the seamless integration of data from various sources into a unified system for analysis.
CSV, JSON), converting data types, handling character encoding (e.g., UTF-8), and addressing missing or inconsistent data. Properly managing data formats and encoding is crucial to maintaining dataintegrity and compatibility for subsequent analysis and processing.
Let’s delve into the key components that form the backbone of a data warehouse: Source Systems These are the operational databases, CRM systems, and other applications that generate the raw data feeding the data warehouse. Data Extraction, Transformation, and Loading (ETL) This is the workhorse of architecture.
Then, it applies these insights to automate and orchestrate the data lifecycle. Instead of handling extract, transform and load (ETL) operations within a data lake, a data mesh defines the data as a product in multiple repositories, each given its own domain for managing its data pipeline.
Their data pipeline (as shown in the following architecture diagram) consists of ingestion, storage, ETL (extract, transform, and load), and a data governance layer. Multi-source data is initially received and stored in an Amazon Simple Storage Service (Amazon S3) data lake.
Here are some effective strategies to break down data silos: DataIntegration Solutions Employing tools for dataintegration such as Extract, Transform, Load (ETL) processes can help consolidate data from various sources into a single repository.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content