This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
So let’s explore how MLOps for softwareengineers addresses these hurdles, enabling scalable, efficient AI development pipelines. One of the key benefits of MLOps for softwareengineers is its focus on version control and reproducibility. As datasets grow, scalable dataingestion and storage become critical.
With this new capability, you can ask questions of your data without the overhead of setting up a vector database or ingestingdata, making it effortless to use your enterprise data. You can now interact with your documents in real time without prior dataingestion or database configuration.
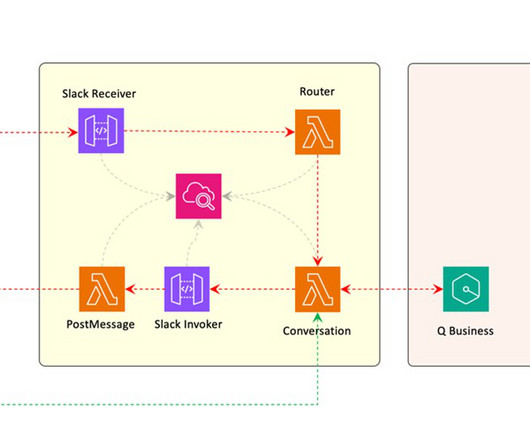
Deltek is continuously working on enhancing this solution to better align it with their specific requirements, such as supporting file formats beyond PDF and implementing more cost-effective approaches for their dataingestion pipeline. The first step is dataingestion, as shown in the following diagram. What is RAG?
By moving our core infrastructure to Amazon Q, we no longer needed to choose a large language model (LLM) and optimize our use of it, manage Amazon Bedrock agents, a vector database and semantic search implementation, or custom pipelines for dataingestion and management.
This manual synchronization process, hindered by disparate data formats, is resource-intensive, limiting the potential for widespread data orchestration. The platform, although functional, deals with CSV and JSON files containing hundreds of thousands of rows from various manufacturers, demanding substantial effort for dataingestion.
DataIngestion and Storage Resumes and job descriptions are collected from users and employers, respectively. AWS S3 is used to store and manage the data. DataIngestion and Storage: A Symphony in S3 Harmony We begin our masterpiece by curating the raw materials — the resumes and job descriptions. subscribe ? ,
You follow the same process of dataingestion, training, and creating a batch inference job as in the previous use case. Pranav Agarwal is a Senior SoftwareEngineer with AWS AI/ML and works on architecting software systems and building AI-powered recommender systems at scale.
Scaling AI/ML Workloads with Ray Kai Fricke | Senior SoftwareEngineer | Anyscale Inc. If so, when and who should perform them? And, Most importantly, what is the point of all this governance, and how much is too much?
Meme shared by ghost_in_the_machine TAI Curated section Article of the week The Design Shift: Building Applications in the Era of Large Language Models by Jun Li A new trend has recently reshaped our approach to building software applications: the rise of large language models (LLMs) and their integration into software development.
Dataengineering – Identifies the data sources, sets up dataingestion and pipelines, and prepares data using Data Wrangler. Data science – The heart of ML EBA and focuses on feature engineering, model training, hyperparameter tuning, and model validation. Connect with him on LinkedIn.
Topics Include: Advanced ML Algorithms & EnsembleMethods Hyperparameter Tuning & Model Optimization AutoML & Real-Time MLSystems Explainable AI & EthicalAI Time Series Forecasting & NLP Techniques Who Should Attend: ML Engineers, Data Scientists, and Technical Practitioners working on production-level ML solutions.
Tutorial: Introduction to Apache Arrow and Apache Parquet, using Python and Pyarrow Andrew Lamb | Chair of the Apache Arrow Program Management Committee | Staff SoftwareEngineer | InfluxData Build new skills in Apache Arrow and Apache Parquet in this upcoming ODSC East tutorial.
The following blog will help you know about the Azure DataEngineering Job Description, salary, and certification course. DataEngineering is one of the most productive job roles today because it imbibes both the skills required for softwareengineering and programming and advanced analytics needed by Data Scientists.
Streamlining Unstructured Data for Retrieval Augmented Generation Matt Robinson | Open Source Tech Lead | Unstructured In this talk, you’ll explore the complexities of handling unstructured data, and offer practical strategies for extracting usable text and metadata from unstructured data.
The solution lies in systems that can handle high-throughput dataingestion while providing accurate, real-time insights. For example, live tracking of GPU utilization or memory usage can reveal early signs of bottlenecks or out-of-memory errors, allowing engineers to proactively adjust course. Tools like neptune.ai
Personas associated with this phase may be primarily Infrastructure Team but may also include all of DataEngineers, Machine Learning Engineers, and Data Scientists. Model Development (Inner Loop): The inner loop element consists of your iterative data science workflow.
Core features of end-to-end MLOps platforms End-to-end MLOps platforms combine a wide range of essential capabilities and tools, which should include: Data management and preprocessing : Provide capabilities for dataingestion, storage, and preprocessing, allowing you to efficiently manage and prepare data for training and evaluation.
The components comprise implementations of the manual workflow process you engage in for automatable steps, including: Dataingestion (extraction and versioning). Data validation (writing tests to check for data quality). Data preprocessing. Let’s briefly go over each of the components below. CSV, Parquet, etc.)
Data flow Here is an example of this data flow for an Agent Creator pipeline that involves dataingestion, preprocessing, and vectorization using Chunker and Embedding Snaps. David Dellsperger is a Senior Staff SoftwareEngineer and Technical Lead of the Agent Creator product at SnapLogic.
My journey in the database field spans over 15 years, including six years as a softwareengineer at Oracle, where I was a founding member of the Oracle 12c Multitenant Database team. By leveraging GPU acceleration, we've dramatically reduced index-building time, enabling faster dataingestion and improved data visibility.
This helps address the requirements of the generative AI fine-tuning lifecycle, from dataingestion and multi-node fine-tuning to inference and evaluation. Special thanks to Kartikay Khandelwal (SoftwareEngineer at Meta), Eli Uriegas (Engineering Manager at Meta), Raj Devnath (Sr.
Automation You want the ML models to keep running in a healthy state without the data scientists incurring much overhead in moving them across the different lifecycle phases. It would make sure that all development and deployment workflows use good softwareengineering practices. My Story DevOps Engineers Who they are?
It involves two key workflows: dataingestion and text generation. The dataingestion workflow creates semantic embeddings for documents and questions, storing document embeddings in a vector database. This bucket is designated as the knowledge base data source.
When inference data is ingested on Amazon S3, EventBridge automatically runs the inference pipeline. This automated workflow streamlines the entire process, from dataingestion to inference, reducing manual interventions and minimizing the risk of errors. In his spare time, Mones enjoys operatic singing and scuba diving.
Amazon Kendra GenAI Index addresses common challenges in building retrievers for generative AI assistants, including dataingestion, model selection, and integration with various generative AI tools. Aakash Upadhyay is a Senior SoftwareEngineer at AWS, specializing in building scalable NLP and Generative AI cloud services.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content