This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ArangoDB offers the same functionality as Neo4j with more than competitive… arangodb.com In the course of this project, I set up a local instance of ArangoDB using docker, and employed the ArangoDB Python Driver, python-arango, to develop dataingestion scripts. This prevents timeout and reconnect issues.
Apache Pinot, an open-source OLAP datastore, offers the ability to handle real-time dataingestion and low-latency querying, making it […] The post Real-Time App Performance Monitoring with Apache Pinot appeared first on Analytics Vidhya.
Data engineering teams are frequently tasked with building bespoke ingestion solutions for myriad custom, proprietary, or industry-specific data sources. Many teams find that.
In this blog post, I’ll walk you through the process of creating a simple interactive question-answering application using Python, Gemini Flash Pro API, LangChain, and Gradio. file (if you're not already in the right directory) and type the following command: python app.py Gradio interface where […]
On the other hand, a Node is a snippet or “chunk” from a Document, enriched with metadata and relationships to other nodes, ensuring a robust foundation for precise data retrieval later on. Data Indexes : Post dataingestion, LlamaIndex assists in indexing this data into a retrievable format.
The solution harnesses the capabilities of generative AI, specifically Large Language Models (LLMs), to address the challenges posed by diverse sensor data and automatically generate Python functions based on various data formats. The solution only invokes the LLM for new device data file type (code has not yet been generated).
Table Search and Filtering: Integrated search and filtering functionalities allow users to find specific columns or values and filter data to spot trends and identify essential values. Enhanced Python Features: New Python coding capabilities include an interactive debugger, error highlighting, and enhanced code navigation features.
With this new capability, you can ask questions of your data without the overhead of setting up a vector database or ingestingdata, making it effortless to use your enterprise data. You can now interact with your documents in real time without prior dataingestion or database configuration.
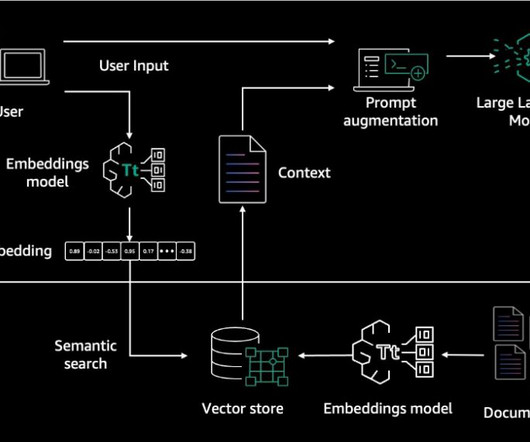
RAG architecture involves two key workflows: data preprocessing through ingestion, and text generation using enhanced context. The dataingestion workflow uses LLMs to create embedding vectors that represent semantic meaning of texts. It offers fully managed dataingestion and text generation workflows.
Detailed Examination of Tools Apache Spark: An open-source platform supporting multiple languages (Python, Java, SQL, Scala, and R). It is suitable for distributed and scalable large-scale data processing, providing quick big-data query and analysis capabilities. Weaknesses: Steep learning curve, especially during initial setup.
Transforming raw data into features using aggregation, encoding, normalization, and other operations is often needed and can require significant effort. Engineers must manually write custom data preprocessing and aggregation logic in Python or Spark for each use case. Choose the car-data-ingestion-pipeline.
However, to unlock their full potential, you often need robust frameworks that handle dataingestion, prompt engineering, memory storage, and tool usage. How It Works The agent might generate a snippet of Python (for instance, calling a search function, doing math, or parsing data).
Problem Statement In this experiment, I will build a Multi-Hop Question-Answering chatbot using Indexify, OpenAI, and DSPy (a Declarative Sequencing Python framework). Each stage of the pipeline can perform structured extraction using any AI model or transform ingesteddata. pip install gradio==4.31.0 pip install dspy-ai==2.0.8
Problem Statement In this experiment, I will build a Multi-Hop Question-Answering chatbot using Indexify, OpenAI, and DSPy (a Declarative Sequencing Python framework). Each stage of the pipeline can perform structured extraction using any AI model or transform ingesteddata. pip install gradio==4.31.0 pip install dspy-ai==2.0.8
The service allows for simple audio dataingestion, easy-to-read transcript creation, and accuracy improvement through custom vocabularies. Prerequisites To follow along with this post, you should have the following prerequisites: Python version greater than 3.9 AWS CDK version 2.0
It can also be used in a variety of languages, such as Python, C++, JavaScript, and Java. The basic data structure for TensorFlow are tensors. Component Integration: TFX has components such as TensorFlow Data Validation, Transform, Model Analysis, and Serving.
LlamaIndex Llama Index is a Python-based framework designed for constructing LLM applications. It acts as a versatile and straightforward data framework, seamlessly connecting custom data sources to LLMs. Langchain’s implementation of RAG sets the stage for a new generation of customer service chatbots.It
We explore how to extract characteristics, also called features , from time series data using the TSFresh library —a Python package for computing a large number of time series characteristics—and perform clustering using the K-Means algorithm implemented in the scikit-learn library.
This e-book focuses on adapting large language models (LLMs) to specific use cases by leveraging Prompt Engineering, Fine-Tuning, and Retrieval Augmented Generation (RAG), tailored for readers with an intermediate knowledge of Python. He is looking for someone with project ideas and a basic understanding of AI and coding (preferably Python).
Transforming Data with Flexibility With Chronon’s SQL-like transformations and time-based aggregations, ML practitioners have the freedom to process data with ease. Online and Offline Results Generation Chronon caters to both online and offline data generation requirements.
Chatbot on custom knowledge base using LLaMA Index — Pragnakalp Techlabs: AI, NLP, Chatbot, Python Development LlamaIndex is an impressive data framework designed to support the development of applications utilizing LLMs (Large Language Models).
The Apache Kafka ecosystem is used more and more to build scalable and reliable machine learning infrastructure for dataingestion, preprocessing, model training, real-time predictions, and monitoring. I had previously discussed example use cases and architectures that leverage Apache Kafka and machine learning.
Python = Powerful AI Research Agent By Gao Dalie () This article details building a powerful AI research agent using Pydantic AI, a web scraper (Tavily), and Llama 3.3. It emphasizes the role of LLamaindex in building RAG systems, managing dataingestion, indexing, and querying. If this sounds exciting, connect in the thread!
Dataingestion and extraction Evaluation reports are prepared and submitted by UNDP program units across the globe—there is no standard report layout template or format. The dataingestion and extraction component ingests and extracts content from these unstructured documents.
With Ray and AIR, the same Python code can scale seamlessly from a laptop to a large cluster. Ingesting features into the feature store contains the following steps: Define a feature group and create the feature group in the feature store. Ingest the prepared data into the feature group by using the Boto3 SDK.
a flexible user interface tool built on top of spaCy, a leading open source library in python for natural language processing. This additional text was labeled by the same coding team using Prodigy, [.]
Initializes the OpenSearch Service client using the Boto3 Python library. Creates two indexes for text ( ooc_text ) and kNN embedding search ( ooc_knn ) and bulk uploads data from the combined dataframe through the ingest_data_into_ops function. Merges the two input files to create a single dataframe for index creation.
You can implement this workflow in Forecast either from the AWS Management Console , the AWS Command Line Interface (AWS CLI), via API calls using Python notebooks , or via automation solutions. The console and AWS CLI methods are best suited for quick experimentation to check the feasibility of time series forecasting using your data.
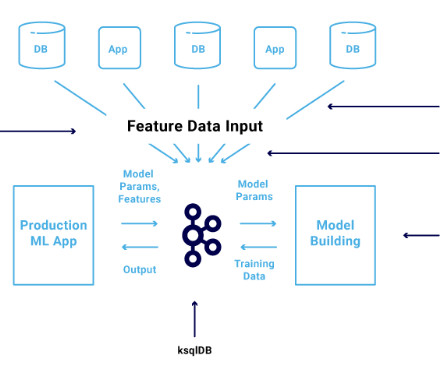
Recommended How to Solve the DataIngestion and Feature Store Component of the MLOps Stack Read more A unified architecture for ML systems One of the challenges in building machine-learning systems is architecting the system. All of them are written in Python. Typically, these activities are collectively called “ MLOps.”
This includes preparing data, creating a SageMaker model, and performing batch transform using the model. Data overview and preparation You can use a SageMaker Studio notebook with a Python 3 (Data Science) kernel to run the sample code. The dataingestion for this practice should finish within 60 seconds.
Deploy with the SageMaker Python SDK You can use the SageMaker Python SDK to deploy the LLMs, as shown in the code available in the repository. Call the loader’s load_data method to parse your source files and data and convert them into LlamaIndex Document objects, ready for indexing and querying.
Why the Best Time to Learn Python is Right Now In this blog, we will explore five reasons why Python has become the most popular programming language and why it is worth considering for your next project, regardless of your area of expertise.
Machine Learning with XGBoost Matt Harrison | Python & Data Science Corporate Trainer | Consultant | MetaSnake Join one of the leading experts in Python for this upcoming ODSC East session. Learn how to use XGBoost and see firsthand how to create, tune, evaluate, and interpret a model.
The ML components for dataingestion, preprocessing, and model training were available as disjointed Python scripts and notebooks, which required a lot of manual heavy lifting on the part of engineers. The initial solution also required the support of a technical third party, to release new models swiftly and efficiently.
I highly recommend anyone coming from a Machine Learning or Deep Learning modeling background who wants to learn about deploying models (MLOps) on a cloud platform to take this exam or an equivalent; the exam also includes topics on SQL dataingestion with Azure and Databricks, which is also a very important skill to have in Data Science.
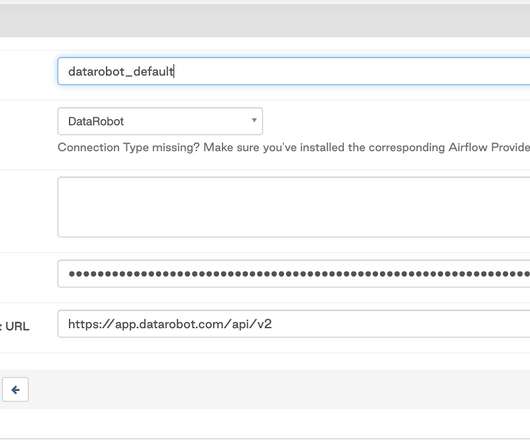
The DataRobot provider for Apache Airflow is a Python package built from source code available in a public GitHub repository and published in PyPi (The Python Package Index). The integration uses the DataRobot Python API Client , which communicates with DataRobot instances via REST API. DataRobot Python API Client >= 2.27.1.
SageMaker has developed the distributed data parallel library , which splits data per node and optimizes the communication between the nodes. You can use the SageMaker Python SDK to trigger a job with data parallelism with minimal modifications to the training script. Each node has a copy of the DNN.
Streamlining Unstructured Data for Retrieval Augmented Generatio n Matt Robinson | Open Source Tech Lead | Unstructured Learn about the complexities of handling unstructured data, and practical strategies for extracting usable text and metadata from it. You’ll also discuss loading processed data into destination storage.
With an understanding of the problem and solution, the subsequent sections dive into how to automate data sourcing through the crawling of architecture diagrams from credible sources. Lastly, we cover the dataingestion by an intelligent search service, powered by ML.
The key sectors where Data Engineering has a major contribution include IT, Internet/eCommerce, and Banking & Insurance. Salary of a Data Engineer ranges between ₹ 3.1 Data Storage: Storing the collected data in various storage systems, such as relational databases, NoSQL databases, data lakes, or data warehouses.
LlamaIndex is an impressive data framework designed to support the development of applications utilizing LLMs (Large Language Models). It offers a wide range of essential tools that simplify tasks such as dataingestion, organization, retrieval, and integration with different application frameworks.
Labeled data can be loaded back into Snowflake as structured data. Dataingestion sources in Snorkel Flow, now includes Snowflake Data Cloud Organizations also have the option of deploying complex ML models on Snowflake. Models built in Snorkel Flow can be registered on Snowflake as Snowpark UDFs.
Labeled data can be loaded back into Snowflake as structured data. Dataingestion sources in Snorkel Flow, now includes Snowflake Data Cloud Organizations also have the option of deploying complex ML models on Snowflake. Models built in Snorkel Flow can be registered on Snowflake as Snowpark UDFs.
For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc., This includes features for data labeling, data versioning, data augmentation, and integration with popular data storage systems.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content