
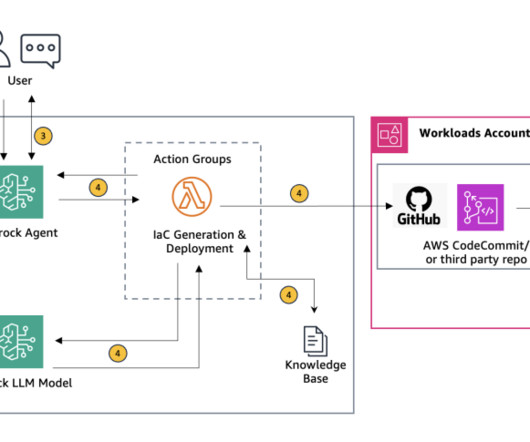
Using Agents for Amazon Bedrock to interactively generate infrastructure as code
AWS Machine Learning Blog
JULY 11, 2024
Agents for Amazon Bedrock automates the prompt engineering and orchestration of user-requested tasks. After being configured, an agent builds the prompt and augments it with your company-specific information to provide responses back to the user in natural language. Double-check all entered information for accuracy.










Let's personalize your content