This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Creating a Custom Vocabulary for NLP tasks Using exBERT and spaCY There are several approaches to adding custom terms to a vocabulary for NLP, but in this tutorial, we’ll focus on exBERT and spaCY tokenizer. Officially Released PyTorch 2.0 Register by Friday for 50% off.
Whats Next in AI TrackExplore the Cutting-Edge Stay ahead of the curve with insights into the future of AI. AI Engineering TrackBuild Scalable AISystems Learn how to bridge the gap between AI development and software engineering. This track will guide you in aligning AI systems with ethical standards and minimizing bias.
This talk will explore a new capability that transforms diverse clinical data (EHR, FHIR, notes, and PDFs) into a unified patient timeline, enabling natural language question answering.
Personas associated with this phase may be primarily Infrastructure Team but may also include all of Data Engineers, Machine Learning Engineers, and Data Scientists. Model Development (Inner Loop): The inner loop element consists of your iterative data science workflow. These include: 1.
ResponsibleAI Development: Phi-2 highlights the importance of considering responsible development practices when building large language models. Consider these technologies: Content-based filtering techniques: Utilizing natural language processing (NLP) techniques like word embeddings and topic modeling (e.g.,
ResponsibleAI and explainability. ML metadata and artifact repository Your data scientists can manually build and test models that you deploy to the production environment. ResponsibleAI and explainability component To fully trust ML systems, it’s important to interpret these predictions. Model serving.
Implement the solution The following illustrates the solution architecture: Architecture Diagram for Custom Hallucination Detection and Mitigation The overall workflow involves the following steps: Dataingestion involving raw PDFs stored in an Amazon Simple Storage Service (Amazon S3) bucket synced as a data source with.
Data lineage and auditing – Metadata can provide information about the provenance and lineage of documents, such as the source system, dataingestion pipeline, or other transformations applied to the data. This information can be valuable for data governance, auditing, and compliance purposes.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

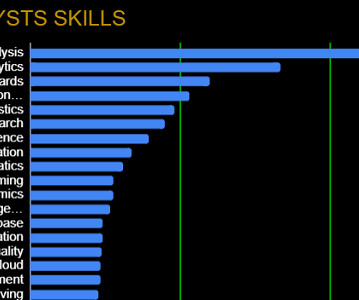



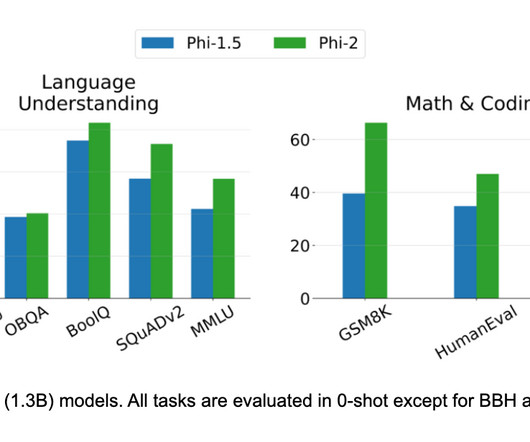

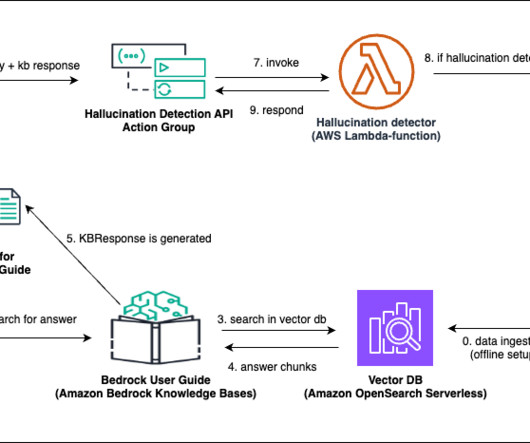







Let's personalize your content