This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Q Business , a new generative AI-powered assistant, can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in an enterprises systems. Large-scale dataingestion is crucial for applications such as document analysis, summarization, research, and knowledge management.
Welcome to Part II of the blog series on extracting entities from text reviews using NLP Lab. To recap, Part I covered the project creation and setup in NLP Lab, showcasing how to configure the environment and walked readers through an example of annotating text data.
AI Copilots leverage various artificial intelligence, natural language processing (NLP), machine learning, and code analysis. They also plan on incorporating offline LLMs as they can process sensitive or confidential information without the need to transmit data over the internet. Check out the GitHub and Documentation.
DataIngestion and Storage Resumes and job descriptions are collected from users and employers, respectively. AWS S3 is used to store and manage the data. NLP and Matching Engine Resumes and job descriptions are encoded into dense vector representations using a language model such as GPT or a custom fine-tuned model.
On the other hand, a Node is a snippet or “chunk” from a Document, enriched with metadata and relationships to other nodes, ensuring a robust foundation for precise data retrieval later on. Data Indexes : Post dataingestion, LlamaIndex assists in indexing this data into a retrievable format.
In simple terms, RAG is a natural language processing (NLP) approach that blends retrieval and generation models to enhance the quality of generated content. It acts as a versatile and straightforward data framework, seamlessly connecting custom data sources to LLMs. It facilitates RAG by integrating models and LLMs.
Building a multi-hop retrieval is a key challenge in natural language processing (NLP) and information retrieval because it requires the system to understand the relationships between different pieces of information and how they contribute to the overall answer. These pipelines are defined using declarative configuration.
The RAG workflow enables you to use your document data stored in an Amazon Simple Storage Service (Amazon S3) bucket and integrate it with the powerful natural language processing (NLP) capabilities of foundation models (FMs) provided by Amazon Bedrock. Choose Sync to initiate the dataingestion job.
Building a multi-hop retrieval is a key challenge in natural language processing (NLP) and information retrieval because it requires the system to understand the relationships between different pieces of information and how they contribute to the overall answer. These pipelines are defined using declarative configuration.
They use self-supervised learning algorithms to perform a variety of natural language processing (NLP) tasks in ways that are similar to how humans use language (see Figure 1). Large language models (LLMs) have taken the field of AI by storm.
Chatbot on custom knowledge base using LLaMA Index — Pragnakalp Techlabs: AI, NLP, Chatbot, Python Development LlamaIndex is an impressive data framework designed to support the development of applications utilizing LLMs (Large Language Models).
As a first step, they wanted to transcribe voice calls and analyze those interactions to determine primary call drivers, including issues, topics, sentiment, average handle time (AHT) breakdowns, and develop additional natural language processing (NLP)-based analytics.
An intelligent document processing (IDP) project typically combines optical character recognition (OCR) and natural language processing (NLP) to automatically read and understand documents. Effectively manage your data and its lifecycle Data plays a key role throughout your IDP solution.
Dataingestion and extraction Evaluation reports are prepared and submitted by UNDP program units across the globe—there is no standard report layout template or format. The dataingestion and extraction component ingests and extracts content from these unstructured documents.
The service allows for simple audio dataingestion, easy-to-read transcript creation, and accuracy improvement through custom vocabularies. She has been part of multiple NLP projects, from behavioral change in digital communication to fraud detection. Amazon Transcribe’s new ASR foundation model supports 100+ language variants.
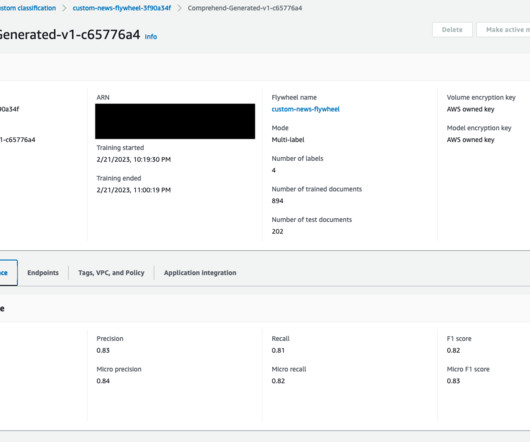
Solution overview Amazon Comprehend is a fully managed service that uses natural language processing (NLP) to extract insights about the content of documents. An Amazon Comprehend flywheel automates this ML process, from dataingestion to deploying the model in production.
Large language models (LLMs) are revolutionizing fields like search engines, natural language processing (NLP), healthcare, robotics, and code generation. For ingestion, data can be updated in an offline mode, whereas inference needs to happen in milliseconds. Gordon Wang is a Senior AI/ML Specialist TAM at AWS.
Creating a Custom Vocabulary for NLP tasks Using exBERT and spaCY There are several approaches to adding custom terms to a vocabulary for NLP, but in this tutorial, we’ll focus on exBERT and spaCY tokenizer. Officially Released PyTorch 2.0 Register by Friday for 50% off.
Finally, I will outline ongoing work and future directions, including improving dataingestion, enhancing model transparency, and refining the contextual application of AI within functional medicine.
Topics Include: Advanced ML Algorithms & EnsembleMethods Hyperparameter Tuning & Model Optimization AutoML & Real-Time MLSystems Explainable AI & EthicalAI Time Series Forecasting & NLP Techniques Who Should Attend: ML Engineers, Data Scientists, and Technical Practitioners working on production-level ML solutions.
LlamaIndex is an impressive data framework designed to support the development of applications utilizing LLMs (Large Language Models). It offers a wide range of essential tools that simplify tasks such as dataingestion, organization, retrieval, and integration with different application frameworks.
This talk will explore a new capability that transforms diverse clinical data (EHR, FHIR, notes, and PDFs) into a unified patient timeline, enabling natural language question answering.
Additionally, the solution must handle high data volumes with low latency and high throughput. This includes dataingestion, data preprocessing, converting documents to document types accepted by Amazon Textract, handling incoming document streams, routing documents by type, and implementing access control and retention policies.
Streamlining Unstructured Data for Retrieval Augmented Generatio n Matt Robinson | Open Source Tech Lead | Unstructured Learn about the complexities of handling unstructured data, and practical strategies for extracting usable text and metadata from it. You’ll also discuss loading processed data into destination storage.
An intelligent document processing (IDP) project usually combines optical character recognition (OCR) and natural language processing (NLP) to read and understand a document and extract specific terms or words. She focuses on NLP-specific workloads, and shares her experience as a conference speaker and a book author.
An IDP pipeline usually combines optical character recognition (OCR) and natural language processing (NLP) to read and understand a document and extract specific terms or words. By centralizing datasets within the flywheel’s dedicated Amazon S3 data lake, you ensure efficient data management.
Semantic search uses Natural Language Processing (NLP) and Machine Learning to interpret the intent behind a users query, enabling more accurate and contextually relevant results. Embedding models are the backbone of semantic search, powering applications in Natural Language Processing (NLP), recommendation systems, and more.
Personas associated with this phase may be primarily Infrastructure Team but may also include all of Data Engineers, Machine Learning Engineers, and Data Scientists. Model Development (Inner Loop): The inner loop element consists of your iterative data science workflow.
Networking Capabilities: Ensure your infrastructure has the networking capabilities to handle large volumes of data transfer. Data Pipeline Management: Set up efficient data pipelines for dataingestion, processing, and management.
The benchmark used is the RoBERTa-Base, a popular model used in natural language processing (NLP) applications, that uses the transformer architecture. The automated process of dataingestion, processing, packaging, combination, and prediction is referred to by WorldQuant as their “alpha factory.”
1 DataIngestion (e.g., Apache Kafka, Amazon Kinesis) 2 Data Preprocessing (e.g., The next section delves into these architectural patterns, exploring how they are leveraged in machine learning pipelines to streamline dataingestion, processing, model training, and deployment.
By leveraging ML and natural language processing (NLP) techniques, CRM platforms can collect raw data from disparate sources, such as purchase patterns, customer interactions, buying behavior, and purchasing history. Dataingested from all these sources, coupled with predictive capability, generates unmatchable analytics.
Bookmark for later Building MLOps Pipeline for NLP: Machine Translation Task [Tutorial] Building MLOps Pipeline for Time Series Prediction [Tutorial] Why do we need a model training pipeline? A typical pipeline may include: DataIngestion: The process begins with ingesting raw data from different sources, such as databases, files, or APIs.
Data flow Here is an example of this data flow for an Agent Creator pipeline that involves dataingestion, preprocessing, and vectorization using Chunker and Embedding Snaps. He focuses on Deep learning including NLP and Computer Vision domains.
During this time, I noticed a key limitation: while structured data was well-managed, unstructured datarepresenting 90% of all dataremained largely untapped, with only 1% analyzed meaningfully. In 2017, the growing ability of AI to process unstructured data marked a turning point.
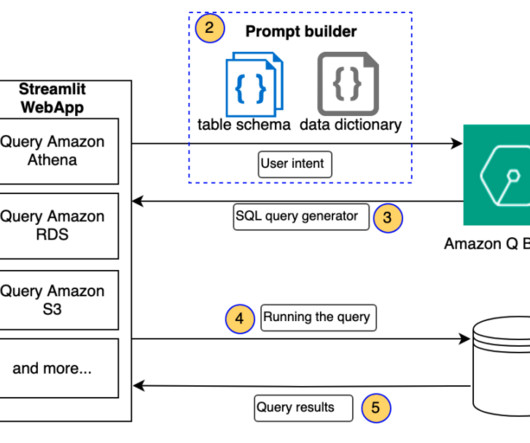
To bridge this gap, you need advanced natural language processing (NLP) to map user queries to database schema, tables, and operations. It augments your question with relevant information from the table schema and data dictionary to provide context for the query generation process.
Consider these technologies: Content-based filtering techniques: Utilizing natural language processing (NLP) techniques like word embeddings and topic modeling (e.g., This translates to longer session durations, increased page views, and deeper user engagement.
Data & ML/LLM Ops on AWS Amazon SageMaker: Comprehensive ML service to build, train, and deploy models at scale. Amazon EMR: Managed big data service to process large datasets quickly. Amazon Comprehend & Translate: Leverage NLP and translation for LLM (Large Language Models) applications.
Data & ML/LLM Ops on AWS Amazon SageMaker: Comprehensive ML service to build, train, and deploy models at scale. Amazon EMR: Managed big data service to process large datasets quickly. Amazon Comprehend & Translate: Leverage NLP and translation for LLM (Large Language Models) applications.
For example, predicting hospital readmissions and emerging COVID-19 hotspots In most cases, these would be batch jobs running on anonymized and de-identified patient data. The most important requirement you need to incorporate into your platform for this vertical is the regulation of data and algorithms.
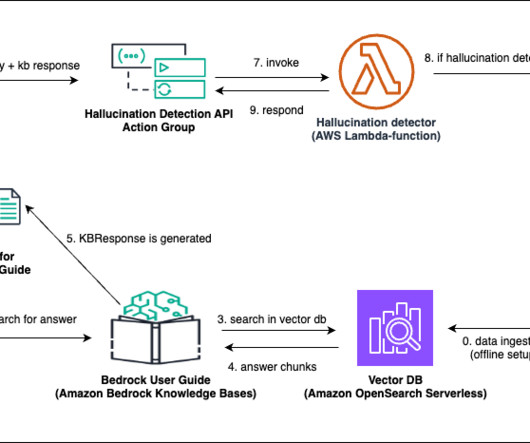
Implement the solution The following illustrates the solution architecture: Architecture Diagram for Custom Hallucination Detection and Mitigation The overall workflow involves the following steps: Dataingestion involving raw PDFs stored in an Amazon Simple Storage Service (Amazon S3) bucket synced as a data source with.
Relational databases like Postgres and Oracle were effective for structured data but required technical proficiency. Search tools like Elastic Search and Solr offered robust solutions for querying unstructured information, but Natural Language Processing (NLP) techniques such as TF-IDF and BM25 often lacked contextual understanding.
Amazon Kendra GenAI Index addresses common challenges in building retrievers for generative AI assistants, including dataingestion, model selection, and integration with various generative AI tools. Aakash Upadhyay is a Senior Software Engineer at AWS, specializing in building scalable NLP and Generative AI cloud services.
Data lineage and auditing – Metadata can provide information about the provenance and lineage of documents, such as the source system, dataingestion pipeline, or other transformations applied to the data. This information can be valuable for data governance, auditing, and compliance purposes.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content