This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
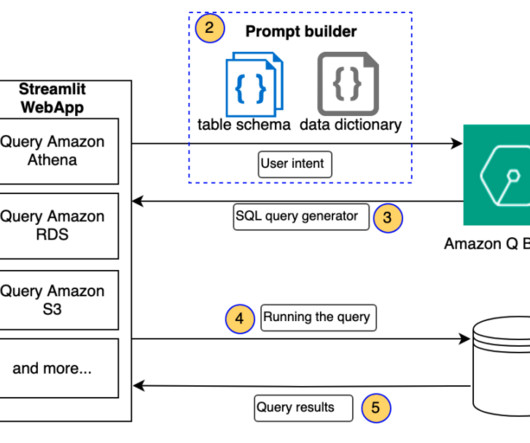
Amazon Q Business , a new generative AI-powered assistant, can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in an enterprises systems. Large-scale dataingestion is crucial for applications such as document analysis, summarization, research, and knowledge management.
Amazon Connect forwards the user’s message to Amazon Lex for naturallanguageprocessing. She leads machine learning projects in various domains such as computer vision, naturallanguageprocessing, and generative AI. For returning users, it resumes their existing Amazon Connect session.
Accelerated dataprocessing Efficient dataprocessing pipelines are critical for AI workflows, especially those involving large datasets. Leveraging distributed storage and processing frameworks such as Apache Hadoop, Spark or Dask accelerates dataingestion, transformation and analysis.
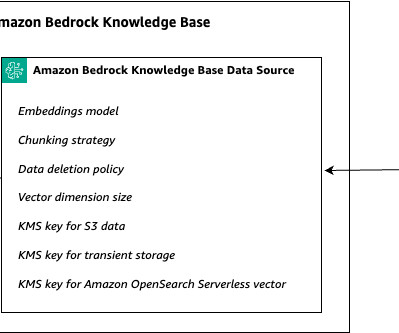
When storing a vector index for your knowledge base in an Aurora database cluster, make sure that the table for your index contains a column for each metadata property in your metadata files before starting dataingestion.
In simple terms, RAG is a naturallanguageprocessing (NLP) approach that blends retrieval and generation models to enhance the quality of generated content. It addresses challenges faced by Large Language Models (LLMs), including limited knowledge access, lack of transparency, and hallucinations in answers.
AI Copilots leverage various artificial intelligence, naturallanguageprocessing (NLP), machine learning, and code analysis. AI Copilots are often updated regularly to incorporate new programming languages, frameworks, and best practices, ensuring they remain valuable to developers as technology evolves.
The solution simplifies the setup process, allowing you to quickly deploy and start querying your data using the selected FM. Choose Sync to initiate the dataingestion job. She leads machine learning projects in various domains such as computer vision, naturallanguageprocessing, and generative AI.
Recently, pretrained language models have significantly advanced text embedding models, enabling better semantic understanding for tasks (e.g., However, in industrial applications, the main bottleneck in efficient document retrieval often lies in the dataingestion pipeline rather than the embedding model’s performance.
By using the AWS CDK, the solution sets up the necessary resources, including an AWS Identity and Access Management (IAM) role, Amazon OpenSearch Serverless collection and index, and knowledge base with its associated data source. Choose Sync to initiate the dataingestion job. Select the knowledge base you created.
Building a multi-hop retrieval is a key challenge in naturallanguageprocessing (NLP) and information retrieval because it requires the system to understand the relationships between different pieces of information and how they contribute to the overall answer. These pipelines are defined using declarative configuration.
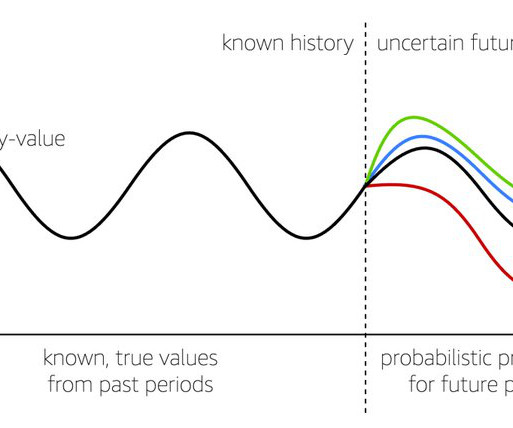
They use self-supervised learning algorithms to perform a variety of naturallanguageprocessing (NLP) tasks in ways that are similar to how humans use language (see Figure 1). Large language models (LLMs) have taken the field of AI by storm.
Building a multi-hop retrieval is a key challenge in naturallanguageprocessing (NLP) and information retrieval because it requires the system to understand the relationships between different pieces of information and how they contribute to the overall answer. These pipelines are defined using declarative configuration.
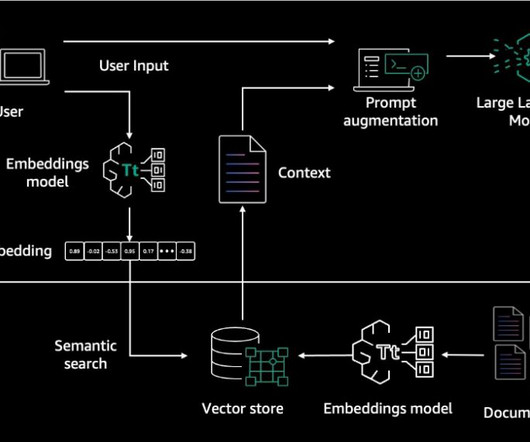
Retrieval Augmented Generation RAG is an approach to naturallanguage generation that incorporates information retrieval into the generation process. RAG architecture involves two key workflows: data preprocessing through ingestion, and text generation using enhanced context.
Explore feature processing pipelines and ML lineage In SageMaker Studio, complete the following steps: On the SageMaker Studio console, on the Home menu, choose Pipelines. You should see two pipelines created: car-data-ingestion-pipeline and car-data-aggregated-ingestion-pipeline. Choose the car-data feature group.
Furthermore, the data that the model was trained on might be out of date, which leads to providing inaccurate responses. RAG is an advanced naturallanguageprocessing technique that combines knowledge retrieval with generative text models.
Large language models (LLMs) are revolutionizing fields like search engines, naturallanguageprocessing (NLP), healthcare, robotics, and code generation. For ingestion, data can be updated in an offline mode, whereas inference needs to happen in milliseconds.
An intelligent document processing (IDP) project typically combines optical character recognition (OCR) and naturallanguageprocessing (NLP) to automatically read and understand documents. Effectively manage your data and its lifecycle Data plays a key role throughout your IDP solution.
As a first step, they wanted to transcribe voice calls and analyze those interactions to determine primary call drivers, including issues, topics, sentiment, average handle time (AHT) breakdowns, and develop additional naturallanguageprocessing (NLP)-based analytics.
a flexible user interface tool built on top of spaCy, a leading open source library in python for naturallanguageprocessing. This additional text was labeled by the same coding team using Prodigy, [.]
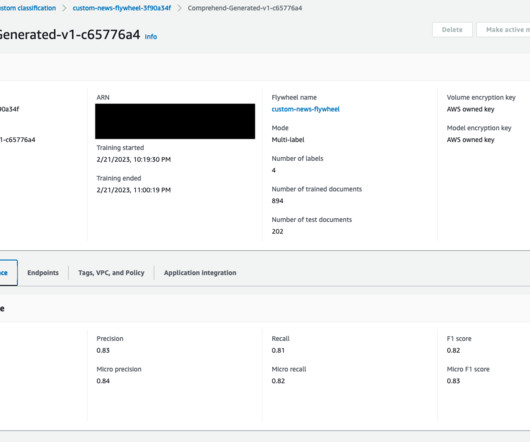
Solution overview Amazon Comprehend is a fully managed service that uses naturallanguageprocessing (NLP) to extract insights about the content of documents. An Amazon Comprehend flywheel automates this ML process, from dataingestion to deploying the model in production.
Additionally, the solution must handle high data volumes with low latency and high throughput. This includes dataingestion, data preprocessing, converting documents to document types accepted by Amazon Textract, handling incoming document streams, routing documents by type, and implementing access control and retention policies.
Call the loader’s load_data method to parse your source files and data and convert them into LlamaIndex Document objects, ready for indexing and querying. load_data() Build the index: The key feature of LlamaIndex is its ability to construct organized indexes over data, which is represented as documents or nodes.
An intelligent document processing (IDP) project usually combines optical character recognition (OCR) and naturallanguageprocessing (NLP) to read and understand a document and extract specific terms or words. His focus is naturallanguageprocessing and computer vision.
Amazon SageMaker Processing jobs for large scale dataingestion into OpenSearch. This notebook will ingest the SageMaker docs to an OpenSearch Service index called llm_apps_workshop_embeddings. This will download the dataset locally into the notebook and then ingest it into the OpenSearch Service index.
An IDP pipeline usually combines optical character recognition (OCR) and naturallanguageprocessing (NLP) to read and understand a document and extract specific terms or words. Keep documentation of processing rules thorough and up to date, fostering a transparent environment for all stakeholders.
Semantic search uses NaturalLanguageProcessing (NLP) and Machine Learning to interpret the intent behind a users query, enabling more accurate and contextually relevant results. Embedding models are the backbone of semantic search, powering applications in NaturalLanguageProcessing (NLP), recommendation systems, and more.
Creates two indexes for text ( ooc_text ) and kNN embedding search ( ooc_knn ) and bulk uploads data from the combined dataframe through the ingest_data_into_ops function. This dataingestionprocess takes 5–10 minutes and can be monitored through the Amazon CloudWatch logs on the Monitoring tab of the Lambda function.
Once an organization has identified its AI use cases , data scientists informally explore methodologies and solutions relevant to the business’s needs in the hunt for proofs of concept. These might include—but are not limited to—deep learning, image recognition and naturallanguageprocessing.
LlamaIndex is an impressive data framework designed to support the development of applications utilizing LLMs (Large Language Models). It offers a wide range of essential tools that simplify tasks such as dataingestion, organization, retrieval, and integration with different application frameworks.
Networking Capabilities: Ensure your infrastructure has the networking capabilities to handle large volumes of data transfer. Data Pipeline Management: Set up efficient data pipelines for dataingestion, processing, and management.
Personas associated with this phase may be primarily Infrastructure Team but may also include all of Data Engineers, Machine Learning Engineers, and Data Scientists. Model Development (Inner Loop): The inner loop element consists of your iterative data science workflow.
This service enables Data Scientists to query data on their terms using serverless or provisioned resources at scale. It also integrates deeply with Power BI and Azure Machine Learning, providing a seamless workflow from dataingestion to advanced analytics.
Learn more The Best Tools, Libraries, Frameworks and Methodologies that ML Teams Actually Use – Things We Learned from 41 ML Startups [ROUNDUP] Key use cases and/or user journeys Identify the main business problems and the data scientist’s needs that you want to solve with ML, and choose a tool that can handle them effectively.
The benchmark used is the RoBERTa-Base, a popular model used in naturallanguageprocessing (NLP) applications, that uses the transformer architecture. The automated process of dataingestion, processing, packaging, combination, and prediction is referred to by WorldQuant as their “alpha factory.”
By leveraging ML and naturallanguageprocessing (NLP) techniques, CRM platforms can collect raw data from disparate sources, such as purchase patterns, customer interactions, buying behavior, and purchasing history. Dataingested from all these sources, coupled with predictive capability, generates unmatchable analytics.
1 DataIngestion (e.g., Apache Kafka, Amazon Kinesis) 2 Data Preprocessing (e.g., The next section delves into these architectural patterns, exploring how they are leveraged in machine learning pipelines to streamline dataingestion, processing, model training, and deployment.
SageMaker Canvas supports multiple ML modalities and problem types, catering to a wide range of use cases based on data types, such as tabular data (our focus in this post), computer vision, naturallanguageprocessing, and document analysis.
The inherent ambiguity of naturallanguage can also result in multiple interpretations of a single query, making it difficult to accurately understand the user’s precise intent. To bridge this gap, you need advanced naturallanguageprocessing (NLP) to map user queries to database schema, tables, and operations.
Consider these technologies: Content-based filtering techniques: Utilizing naturallanguageprocessing (NLP) techniques like word embeddings and topic modeling (e.g., Distributed computing platforms: Spark and Ray enable parallel processing and model training on large datasets,crucial for real-time scalability.
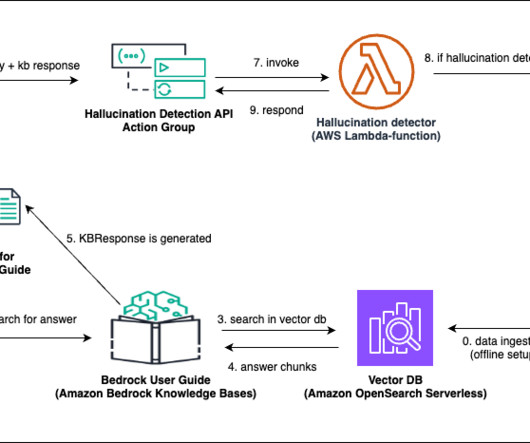
Implement the solution The following illustrates the solution architecture: Architecture Diagram for Custom Hallucination Detection and Mitigation The overall workflow involves the following steps: Dataingestion involving raw PDFs stored in an Amazon Simple Storage Service (Amazon S3) bucket synced as a data source with.
Machine learning platform in healthcare There are mostly three areas of ML opportunities for healthcare, including computer vision, predictive analytics, and naturallanguageprocessing. Let’s look at the healthcare vertical for context.
Relational databases like Postgres and Oracle were effective for structured data but required technical proficiency. Search tools like Elastic Search and Solr offered robust solutions for querying unstructured information, but NaturalLanguageProcessing (NLP) techniques such as TF-IDF and BM25 often lacked contextual understanding.
With the advent of foundation models (FMs) and their remarkable naturallanguageprocessing capabilities, a new opportunity has emerged to unlock the value of their data assets. Single knowledge base A single knowledge base is created to handle the dataingestion for your tenants.
Data lineage and auditing – Metadata can provide information about the provenance and lineage of documents, such as the source system, dataingestion pipeline, or other transformations applied to the data. This information can be valuable for data governance, auditing, and compliance purposes.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content