This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon SageMaker Feature Store provides an end-to-end solution to automate feature engineering for machine learning (ML). For many ML use cases, raw data like log files, sensor readings, or transaction records need to be transformed into meaningful features that are optimized for model training. SageMaker Studio set up.
The solution harnesses the capabilities of generative AI, specifically Large Language Models (LLMs), to address the challenges posed by diverse sensor data and automatically generate Python functions based on various data formats. The solution only invokes the LLM for new device data file type (code has not yet been generated).
With this new capability, you can ask questions of your data without the overhead of setting up a vector database or ingestingdata, making it effortless to use your enterprise data. You can now interact with your documents in real time without prior dataingestion or database configuration.
Detailed Examination of Tools Apache Spark: An open-source platform supporting multiple languages (Python, Java, SQL, Scala, and R). It is suitable for distributed and scalable large-scale data processing, providing quick big-data query and analysis capabilities. Weaknesses: Steep learning curve, especially during initial setup.
The service allows for simple audio dataingestion, easy-to-read transcript creation, and accuracy improvement through custom vocabularies. Hugging Face is an open-source machine learning (ML) platform that provides tools and resources for the development of AI projects. AWS CDK version 2.0
In this post, we discuss how the IEO developed UNDP’s artificial intelligence and machine learning (ML) platform—named Artificial Intelligence for Development Analytics (AIDA)— in collaboration with AWS, UNDP’s Information and Technology Management Team (UNDP ITM), and the United Nations International Computing Centre (UNICC).
In the ever-evolving landscape of machine learning, feature management has emerged as a key pain point for ML Engineers at Airbnb. Airbnb recognized the need for a solution that could streamline feature data management, provide real-time updates, and ensure consistency between training and production environments.
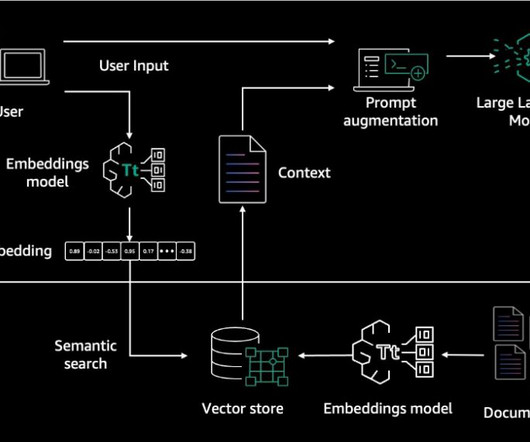
RAG architecture involves two key workflows: data preprocessing through ingestion, and text generation using enhanced context. The dataingestion workflow uses LLMs to create embedding vectors that represent semantic meaning of texts. It offers fully managed dataingestion and text generation workflows.
I highly recommend anyone coming from a Machine Learning or Deep Learning modeling background who wants to learn about deploying models (MLOps) on a cloud platform to take this exam or an equivalent; the exam also includes topics on SQL dataingestion with Azure and Databricks, which is also a very important skill to have in Data Science.
This post, part of the Governing the ML lifecycle at scale series ( Part 1 , Part 2 , Part 3 ), explains how to set up and govern a multi-account ML platform that addresses these challenges. An enterprise might have the following roles involved in the ML lifecycles. This ML platform provides several key benefits.
Machine learning (ML) is becoming increasingly complex as customers try to solve more and more challenging problems. This complexity often leads to the need for distributed ML, where multiple machines are used to train a single model. SageMaker is a fully managed service for building, training, and deploying ML models.
AWS provides various services catered to time series data that are low code/no code, which both machine learning (ML) and non-ML practitioners can use for building ML solutions. We recommend running this notebook on Amazon SageMaker Studio , a web-based, integrated development environment (IDE) for ML.
This e-book focuses on adapting large language models (LLMs) to specific use cases by leveraging Prompt Engineering, Fine-Tuning, and Retrieval Augmented Generation (RAG), tailored for readers with an intermediate knowledge of Python. Elymsyr wants to develop new projects to improve their ML, RL, computer vision, and co-working skills.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
We downloaded the data from AWS Data Exchange and processed it in AWS Glue to generate KG files. In Part 2 , we demonstrated how to use Amazon Neptune ML (in Amazon SageMaker ) to train the KG and create KG embeddings. Initializes the OpenSearch Service client using the Boto3 Python library.
When machine learning (ML) models are deployed into production and employed to drive business decisions, the challenge often lies in the operation and management of multiple models. That is where Provectus , an AWS Premier Consulting Partner with competencies in Machine Learning, Data & Analytics, and DevOps, stepped in.
Luckily, we have tried and trusted tools and architectural patterns that provide a blueprint for reliable ML systems. In this article, I’ll introduce you to a unified architecture for ML systems built around the idea of FTI pipelines and a feature store as the central component. But what is an ML pipeline?
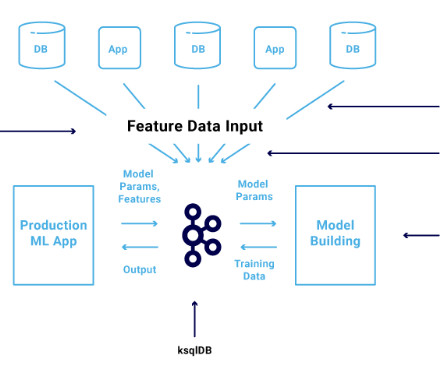
Be sure to check out his talk, “ Apache Kafka for Real-Time Machine Learning Without a Data Lake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the Apache Kafka ecosystem.
Amazon SageMaker Serverless Inference is a purpose-built inference service that makes it easy to deploy and scale machine learning (ML) models. This includes preparing data, creating a SageMaker model, and performing batch transform using the model. You can use CLIP with Amazon SageMaker to perform encoding. path local_data_root = f'.
Amazon SageMaker Processing jobs for large scale dataingestion into OpenSearch. This notebook will ingest the SageMaker docs to an OpenSearch Service index called llm_apps_workshop_embeddings. This will download the dataset locally into the notebook and then ingest it into the OpenSearch Service index.
Identification of relevant representation data from a huge volume of data – This is essential to reduce biases in the datasets so that common scenarios (driving at normal speed with obstruction) don’t create class imbalance. To yield better accuracy, DNNs require large volumes of diverse, good quality data.
Andre Franca | CTO | connectedFlow Join this session to demystify the world of Causal AI, with a focus on understanding cause-and-effect relationships within data to drive optimal decisions. By the end of this session, you’ll have a practical blueprint to efficiently harness feature stores within ML workflows.
In this post, we discuss a machine learning (ML) solution for complex image searches using Amazon Kendra and Amazon Rekognition. Amazon Kendra is an intelligent search service powered by ML, and Amazon Rekognition is an ML service that can identify objects, people, text, scenes, and activities from images or videos.
Simple methods for time series forecasting use historical values of the same variable whose future values need to be predicted, whereas more complex, machine learning (ML)-based methods use additional information, such as the time series data of related variables. All of this is possible without having to write or compile code.
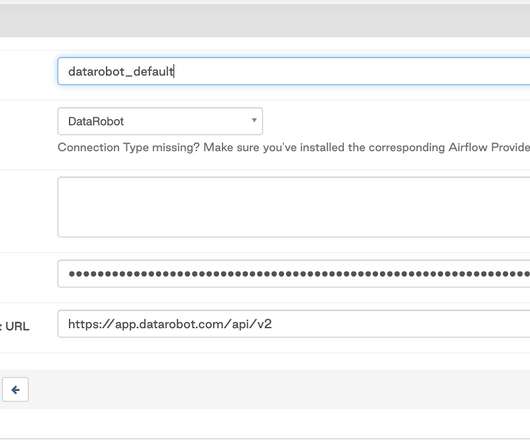
Airflow is a perfect tool to orchestrate stages of the DataRobot machine learning (ML) pipeline, because it provides an easy but powerful solution to integrate DataRobot capabilities into bigger pipelines, combine it with other services, as well as to clean your data, and store or publish the results. DataRobot Provider Modules.
Why the Best Time to Learn Python is Right Now In this blog, we will explore five reasons why Python has become the most popular programming language and why it is worth considering for your next project, regardless of your area of expertise.
Deploy with the SageMaker Python SDK You can use the SageMaker Python SDK to deploy the LLMs, as shown in the code available in the repository. Call the loader’s load_data method to parse your source files and data and convert them into LlamaIndex Document objects, ready for indexing and querying.
Unfortunately accessing data across various locations and file types and then operationalizing that data for AI usage has traditionally been a painfully manual, time-consuming, and costly process. Ahmad Khan, Head of AI/ML Strategy at Snowflake, discusses the challenges of operationalizing ML in a recent talk.
Unfortunately accessing data across various locations and file types and then operationalizing that data for AI usage has traditionally been a painfully manual, time-consuming, and costly process. Ahmad Khan, Head of AI/ML Strategy at Snowflake, discusses the challenges of operationalizing ML in a recent talk.
These activities cover disparate fields such as basic data processing, analytics, and machine learning (ML). ML is often associated with PBAs, so we start this post with an illustrative figure. The ML paradigm is learning followed by inference. The union of advances in hardware and ML has led us to the current day.
Andre Franca | CTO | connectedFlow Explore the world of Causal AI for data science practitioners, with a focus on understanding cause-and-effect relationships within data to drive optimal decisions. How do we figure out what is causal and what isn’t, with a brief introduction to methods of structure learning and causal discovery?
Machine Learning Operations (MLOps) can significantly accelerate how data scientists and ML engineers meet organizational needs. A well-implemented MLOps process not only expedites the transition from testing to production but also offers ownership, lineage, and historical data about ML artifacts used within the team.
It provides a web-based interface for building data pipelines and can be used to process both batch and streaming data. Azure Stream Analytics : A cloud-based service that can be used to process streaming data in real-time. It provides a variety of features, such as dataingestion, data transformation, and real-time processing.
Strong programming language skills in at least one of the languages like Python, Java, R, or Scala. Having a solid understanding of ML principles and practical knowledge of statistics, algorithms, and mathematics. Answer : Polybase helps optimize dataingestion into PDW and supports T-SQL. What is Polybase?
Photo by Andrew Neel on Unsplash Introduction If you are working or have worked on any data science task then you definitely used pandas. So, pandas is a library which helps with performing dataingestion and transformations.
pip install snowflake-connector-python import sys import boto3 import snowflake.connector region = 'us-west-2' # you need to know which region your Snowflake account is created from your admin We are going to use Python boto3 library to extract the user/password for the Snowflake connection.
In the image, you can see that the extract the weather data and extract metadata information about the location need to run in parallel. This is necessary because additional Python modules need to be installed. Similarly, if you need to complete a Python process, you will need the Python operator.
Handling Missing Data: Imputing missing values or applying suitable techniques like mean substitution or predictive modelling. Tools such as Python’s Pandas library, Apache Spark, or specialised data cleaning software streamline these processes, ensuring data integrity before further transformation.
Data pipeline stages But before delving deeper into the technical aspects of these tools, let’s quickly understand the core components of a data pipeline succinctly captured in the image below: Data pipeline stages | Source: Author What does a good data pipeline look like? Strong community and tech support.
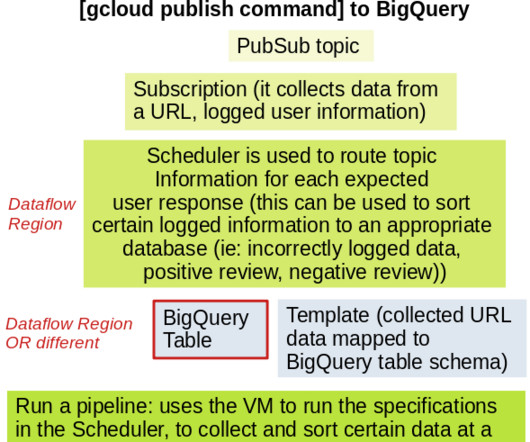
BigQuery is very useful in terms of having a centralized location of structured data; ingestion on GCP is wonderful using the ‘bq load’ command line tool for uploading local .csv PubSub and Dataflow are solutions for storing newly created data from website/application activity, in either BigQuery or Google Cloud Storage.
One of the most prevalent complaints we hear from ML engineers in the community is how costly and error-prone it is to manually go through the ML workflow of building and deploying models. Building end-to-end machine learning pipelines lets ML engineers build once, rerun, and reuse many times. If all goes well, of course ?
Complete ML model training pipeline workflow | Source But before we delve into the step-by-step model training pipeline, it’s essential to understand the basics, architecture, motivations, challenges associated with ML pipelines, and a few tools that you will need to work with.
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificial intelligence (AI) to personalize experiences at scale. Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from dataingestion to model deployment.
From gathering and processing data to building models through experiments, deploying the best ones, and managing them at scale for continuous value in production—it’s a lot. As the number of ML-powered apps and services grows, it gets overwhelming for data scientists and ML engineers to build and deploy models at scale.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content