This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By leveraging ML and natural language processing (NLP) techniques, CRM platforms can collect raw data from disparate sources, such as purchase patterns, customer interactions, buying behavior, and purchasing history. Dataingested from all these sources, coupled with predictive capability, generates unmatchable analytics.
Amazon Q Business , a new generative AI-powered assistant, can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in an enterprises systems. Large-scale dataingestion is crucial for applications such as document analysis, summarization, research, and knowledge management.
Amazon SageMaker Feature Store provides an end-to-end solution to automate feature engineering for machine learning (ML). For many ML use cases, raw data like log files, sensor readings, or transaction records need to be transformed into meaningful features that are optimized for model training. SageMaker Studio set up.
If you think about building a data pipeline, whether you’re doing a simple BI project or a complex AI or machine learning project, you’ve got dataingestion, data storage and processing, and data insight – and underneath all of those four stages, there’s a variety of different technologies being used,” explains Faruqui.
Data exploration and model development were conducted using well-known machine learning (ML) tools such as Jupyter or Apache Zeppelin notebooks. Apache Hive was used to provide a tabular interface to data stored in HDFS, and to integrate with Apache Spark SQL. This created a challenge for data scientists to become productive.
Do you need help to move your organization’s Machine Learning (ML) journey from pilot to production? Most executives think ML can apply to any business decision, but on average only half of the ML projects make it to production. Challenges Customers may face several challenges when implementing machine learning (ML) solutions.
For production deployment, the no-code recipes enable easy assembly of the dataingestion pipeline to create a knowledge base and deployment of RAG or agentic chains. These solutions include two primary components: a dataingestion pipeline for building a knowledge base and a system for knowledge retrieval and summarization.
Prior to starting LangChain, he led the ML team at Robus Intelligence, led the entity linking team at Kensho, and studied statistics and computer science at Harvard. Harrison Chase is the CEO and cofounder of LangChain, an open source framework and toolkit that helps developers build context-aware reasoning applications.
By helping customers integrate artificial intelligence (AI) and machine learning (ML) into their key business operations, Quantum helps customers to effectively manage and unlock meaningful value from their unstructured data, creating actionable business insights that lead to better business decisions.
By default, Amazon Bedrock encrypts all knowledge base-related data using an AWS managed key. When setting up a dataingestion job for your knowledge base, you can also encrypt the job using a custom AWS Key Management Service (AWS KMS) key. Alternatively, you can choose to use a customer managed key.
Data preparation isn’t just a part of the ML engineering process — it’s the heart of it. Photo by Myriam Jessier on Unsplash To set the stage, let’s examine the nuances between research-phase data and production-phase data. Data is a key differentiator in ML projects (more on this in my blog post below).
Creating RESTful APIs and services with JuliaImage Generated by AI on Gencraft U+1F44B Hello and welcome back to our series to explore the Julia programming language to develop end-to-end machine learning (ML) projects. In this post, we will introduce a package that could help develop RESTful APIs in Julia U+1F680.
This manual synchronization process, hindered by disparate data formats, is resource-intensive, limiting the potential for widespread data orchestration. The platform, although functional, deals with CSV and JSON files containing hundreds of thousands of rows from various manufacturers, demanding substantial effort for dataingestion.
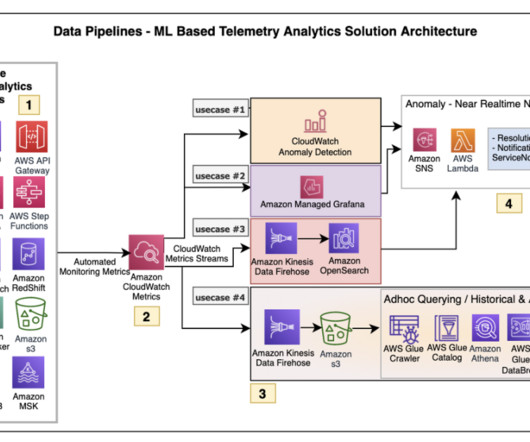
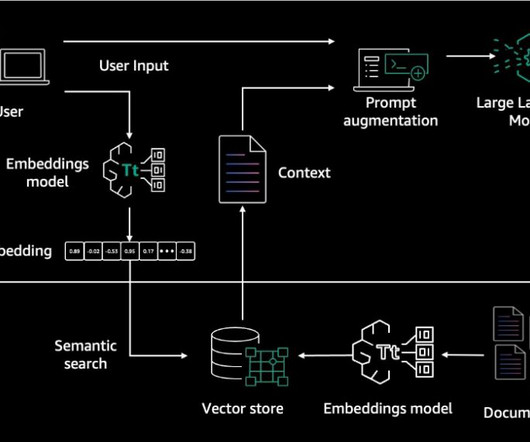
Deltek is continuously working on enhancing this solution to better align it with their specific requirements, such as supporting file formats beyond PDF and implementing more cost-effective approaches for their dataingestion pipeline. The first step is dataingestion, as shown in the following diagram. What is RAG?
In this post, we discuss how the IEO developed UNDP’s artificial intelligence and machine learning (ML) platform—named Artificial Intelligence for Development Analytics (AIDA)— in collaboration with AWS, UNDP’s Information and Technology Management Team (UNDP ITM), and the United Nations International Computing Centre (UNICC).
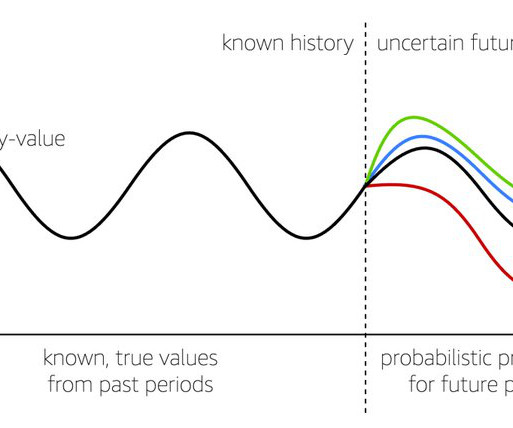
In this post, we show you how Amazon Web Services (AWS) helps in solving forecasting challenges by customizing machine learning (ML) models for forecasting. This visual, point-and-click interface democratizes ML so users can take advantage of the power of AI for various business applications. One of these methods is quantiles.
The architectures strengths lie in its consistency across environments, automatic dataingestion processes, and comprehensive monitoring capabilities. In addition, he builds and deploys AI/ML models on the AWS Cloud. Additionally, Ian focuses on building AI/ML solutions using AWS services.
Test the solution To validate the Amazon Q solution is functioning as expected, perform the following tests: Test dataingestion: Upload a test file to the S3 bucket. Verify that the file is successfully ingested and processed by Amazon Q. Check the Amazon Q web experience UI for the processed data.
With this new capability, you can ask questions of your data without the overhead of setting up a vector database or ingestingdata, making it effortless to use your enterprise data. You can now interact with your documents in real time without prior dataingestion or database configuration.
This post, part of the Governing the ML lifecycle at scale series ( Part 1 , Part 2 , Part 3 ), explains how to set up and govern a multi-account ML platform that addresses these challenges. An enterprise might have the following roles involved in the ML lifecycles. This ML platform provides several key benefits.
At its core, Amazon Bedrock provides the foundational infrastructure for robust performance, security, and scalability for deploying machine learning (ML) models. Data flow Here is an example of this data flow for an Agent Creator pipeline that involves dataingestion, preprocessing, and vectorization using Chunker and Embedding Snaps.
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificial intelligence (AI) to personalize experiences at scale. Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from dataingestion to model deployment.
They are also working on expanding OpenCopilot’s dataingestion capabilities with plans to support a range of formats, from texts and PDFs to websites and other data sources. Check out the GitHub and Documentation. All Credit For This Research Goes To the Researchers on This Project.
Image Source TensorFlow Extended (TFX): An open-source machine learning pipeline platform supporting end-to-end ML workflows. It provides components for dataingestion, validation, and feature extraction. Weaknesses: Steep learning curve, especially during initial setup.
In the ever-evolving landscape of machine learning, feature management has emerged as a key pain point for ML Engineers at Airbnb. Airbnb recognized the need for a solution that could streamline feature data management, provide real-time updates, and ensure consistency between training and production environments.
The system is meticulously designed for high flexibility in data processing tasks, including deduplication, bias mitigation, and toxicity removal, without specifying the use of particular datasets in the paper. Also, don’t forget to follow us on Twitter. Join our Telegram Channel , Discord Channel , and LinkedIn Gr oup.
Foundational models (FMs) are marking the beginning of a new era in machine learning (ML) and artificial intelligence (AI) , which is leading to faster development of AI that can be adapted to a wide range of downstream tasks and fine-tuned for an array of applications. Large language models (LLMs) have taken the field of AI by storm.
In this post, we share how Axfood, a large Swedish food retailer, improved operations and scalability of their existing artificial intelligence (AI) and machine learning (ML) operations by prototyping in close collaboration with AWS experts and using Amazon SageMaker. This is a guest post written by Axfood AB.
With the IoT, tracking website clicks, capturing call data records for a mobile network carrier, tracking events generated by “smart meters” and embedded devices can all generate huge volumes of transactions. Many consider a NoSQL database essential for high dataingestion rates.
I highly recommend anyone coming from a Machine Learning or Deep Learning modeling background who wants to learn about deploying models (MLOps) on a cloud platform to take this exam or an equivalent; the exam also includes topics on SQL dataingestion with Azure and Databricks, which is also a very important skill to have in Data Science.
RAG architecture involves two key workflows: data preprocessing through ingestion, and text generation using enhanced context. The dataingestion workflow uses LLMs to create embedding vectors that represent semantic meaning of texts. It offers fully managed dataingestion and text generation workflows.
The service allows for simple audio dataingestion, easy-to-read transcript creation, and accuracy improvement through custom vocabularies. Hugging Face is an open-source machine learning (ML) platform that provides tools and resources for the development of AI projects.
This approach, when applied to generative AI solutions, means that a specific AI or machine learning (ML) platform configuration can be used to holistically address the operational excellence challenges across the enterprise, allowing the developers of the generative AI solution to focus on business value.
Choose Sync to initiate the dataingestion job. After the dataingestion job is complete, choose the desired FM to use for retrieval and generation. He has successfully delivered state-of-the-art AI/ML-powered solutions to solve complex business problems for diverse industries, optimizing efficiency and scalability.
In BI systems, data warehousing first converts disparate raw data into clean, organized, and integrated data, which is then used to extract actionable insights to facilitate analysis, reporting, and data-informed decision-making. Some key differences are discussed below.
Choose Sync to initiate the dataingestion job. After data synchronization is complete, select the desired FM to use for retrieval and generation (it requires model access to be granted to this FM in Amazon Bedrock before using). On the Amazon Bedrock console, navigate to the created knowledge base.
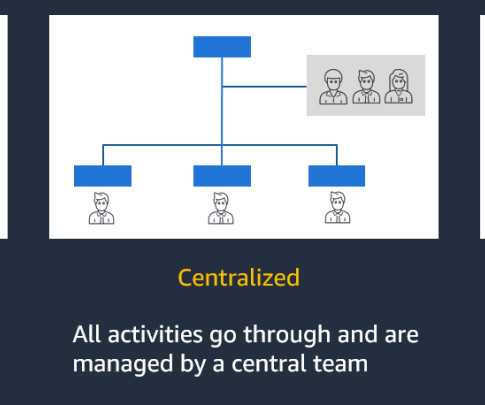
However, even in a decentralized model, often LOBs must align with central governance controls and obtain approvals from the CCoE team for production deployment, adhering to global enterprise standards for areas such as access policies, model risk management, data privacy, and compliance posture, which can introduce governance complexities.
Amazon DataZone makes it straightforward for engineers, data scientists, product managers, analysts, and business users to access data throughout an organization so they can discover, use, and collaborate to derive data-driven insights.
You can use machine learning (ML) to generate these insights and build predictive models. Educators can also use ML to identify challenges in learning outcomes, increase success and retention among students, and broaden the reach and impact of online learning content. The dataset comes under the Attribution 4.0 International (CC BY 4.0)
Combining accurate transcripts with Genesys CTR files, Principal could properly identify the speakers, categorize the calls into groups, analyze agent performance, identify upsell opportunities, and conduct additional machine learning (ML)-powered analytics.
When machine learning (ML) models are deployed into production and employed to drive business decisions, the challenge often lies in the operation and management of multiple models. That is where Provectus , an AWS Premier Consulting Partner with competencies in Machine Learning, Data & Analytics, and DevOps, stepped in.
Learn about the flow, difficulties, and tools for performing ML clustering at scale Ori Nakar | Principal Engineer, Threat Research | Imperva Given that there are billions of daily botnet attacks from millions of different IPs, the most difficult challenge of botnet detection is choosing the most relevant data.
The IDP Well-Architected Custom Lens follows the AWS Well-Architected Framework, reviewing the solution with six pillars with the granularity of a specific AI or machine learning (ML) use case, and providing the guidance to tackle common challenges. Additionally, the solution must handle high data volumes with low latency and high throughput.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content