This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
On the other hand, a Node is a snippet or “chunk” from a Document, enriched with metadata and relationships to other nodes, ensuring a robust foundation for precise data retrieval later on. Data Indexes : Post dataingestion, LlamaIndex assists in indexing this data into a retrievable format.
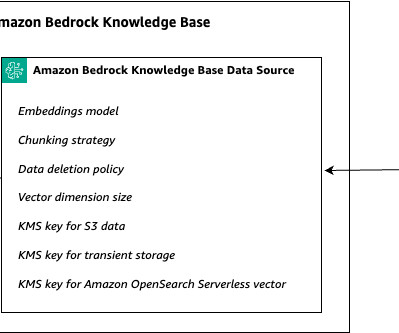
With Knowledge Bases for Amazon Bedrock, you can securely connect foundation models (FMs) in Amazon Bedrock to your company data for fully managed Retrieval Augmented Generation (RAG). You can now interact with your documents in real time without prior dataingestion or database configuration.
This includes preparing data, creating a SageMaker model, and performing batch transform using the model. Data overview and preparation You can use a SageMaker Studio notebook with a Python 3 (Data Science) kernel to run the sample code. We use the first metadata file in this demo. images/metadata/images.csv.gz
Dataingestion and extraction Evaluation reports are prepared and submitted by UNDP program units across the globe—there is no standard report layout template or format. The dataingestion and extraction component ingests and extracts content from these unstructured documents.
Transforming Data with Flexibility With Chronon’s SQL-like transformations and time-based aggregations, ML practitioners have the freedom to process data with ease. Online and Offline Results Generation Chronon caters to both online and offline data generation requirements.
In this post, we illustrate how to handle OOC by utilizing the power of the IMDb dataset (the premier source of global entertainment metadata) and knowledge graphs. Creates a Lambda function to process and load movie metadata and embeddings to OpenSearch Service indexes ( **-ReadFromOpenSearchLambda-** ).
Each dataset group can have up to three datasets, one of each dataset type: target time series (TTS), related time series (RTS), and item metadata. A dataset is a collection of files that contain data that is relevant for a forecasting task. DatasetGroupFrequencyTTS The frequency of data collection for the TTS dataset.
For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc., This includes features for data labeling, data versioning, data augmentation, and integration with popular data storage systems. Can you render audio/video?
We explore how to extract characteristics, also called features , from time series data using the TSFresh library —a Python package for computing a large number of time series characteristics—and perform clustering using the K-Means algorithm implemented in the scikit-learn library. References Dua, D. and Graff, C.
After modeling, detected services of each architecture diagram image and its metadata, like URL origin and image title, are indexed for future search purposes and stored in Amazon DynamoDB , a fully managed, serverless, key-value NoSQL database designed to run high-performance applications. join(", "), }; }).catch((error)
A feature store typically comprises a feature repository, a feature serving layer, and a metadata store. It can also transform incoming data on the fly. The metadata store manages the metadata associated with each feature, such as its origin and transformations. All of them are written in Python.
Streamlining Unstructured Data for Retrieval Augmented Generatio n Matt Robinson | Open Source Tech Lead | Unstructured Learn about the complexities of handling unstructured data, and practical strategies for extracting usable text and metadata from it. You’ll also discuss loading processed data into destination storage.
The ML components for dataingestion, preprocessing, and model training were available as disjointed Python scripts and notebooks, which required a lot of manual heavy lifting on the part of engineers. The initial solution also required the support of a technical third party, to release new models swiftly and efficiently.
You might need to extract the weather and metadata information about the location, after which you will combine both for transformation. In the image, you can see that the extract the weather data and extract metadata information about the location need to run in parallel. This type of execution is shown below.
The components comprise implementations of the manual workflow process you engage in for automatable steps, including: Dataingestion (extraction and versioning). Data validation (writing tests to check for data quality). Data preprocessing. Let’s briefly go over each of the components below. CSV, Parquet, etc.)
In terms of resulting speedups, the approximate order is programming hardware, then programming against PBA APIs, then programming in an unmanaged language such as C++, then a managed language such as Python. The following table shows the metadata of three of the largest accelerated compute instances. 32xlarge 0 16 0 128 512 512 4 x 1.9
To make that possible, your data scientists would need to store enough details about the environment the model was created in and the related metadata so that the model could be recreated with the same or similar outcomes. Your ML platform must have versioning in-built because code and data mostly make up the ML system.
In the context of RAG systems, tenants might have varying requirements for dataingestion frequency, document chunking strategy, or vector search configuration. Metadata filtering can be used in the silo pattern to restrict the search to a subset of documents with a specific characteristic.
Role of metadata while indexing data in vector databases Metadata plays a crucial role when loading documents into a vector data store in Amazon Bedrock. These identifiers can be used to uniquely reference and retrieve specific documents from the vector data store. This was created in Step-2 above.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content