This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Q Business , a new generative AI-powered assistant, can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in an enterprises systems. Large-scale dataingestion is crucial for applications such as document analysis, summarization, research, and knowledge management.
On the other hand, a Node is a snippet or “chunk” from a Document, enriched with metadata and relationships to other nodes, ensuring a robust foundation for precise data retrieval later on. Data Indexes : Post dataingestion, LlamaIndex assists in indexing this data into a retrievable format.
As a first step, they wanted to transcribe voice calls and analyze those interactions to determine primary call drivers, including issues, topics, sentiment, average handle time (AHT) breakdowns, and develop additional natural language processing (NLP)-based analytics.
Large language models (LLMs) are revolutionizing fields like search engines, natural language processing (NLP), healthcare, robotics, and code generation. A feature store maintains user profile data. A media metadata store keeps the promotion movie list up to date. The agent sends the personalized email campaign to the end user.
Dataingestion and extraction Evaluation reports are prepared and submitted by UNDP program units across the globe—there is no standard report layout template or format. The dataingestion and extraction component ingests and extracts content from these unstructured documents.
This talk will explore a new capability that transforms diverse clinical data (EHR, FHIR, notes, and PDFs) into a unified patient timeline, enabling natural language question answering.
Streamlining Unstructured Data for Retrieval Augmented Generatio n Matt Robinson | Open Source Tech Lead | Unstructured Learn about the complexities of handling unstructured data, and practical strategies for extracting usable text and metadata from it. You’ll also discuss loading processed data into destination storage.
Topics Include: Advanced ML Algorithms & EnsembleMethods Hyperparameter Tuning & Model Optimization AutoML & Real-Time MLSystems Explainable AI & EthicalAI Time Series Forecasting & NLP Techniques Who Should Attend: ML Engineers, Data Scientists, and Technical Practitioners working on production-level ML solutions.
The following table shows the metadata of three of the largest accelerated compute instances. The benchmark used is the RoBERTa-Base, a popular model used in natural language processing (NLP) applications, that uses the transformer architecture. 32xlarge 0 16 0 128 512 512 4 x 1.9
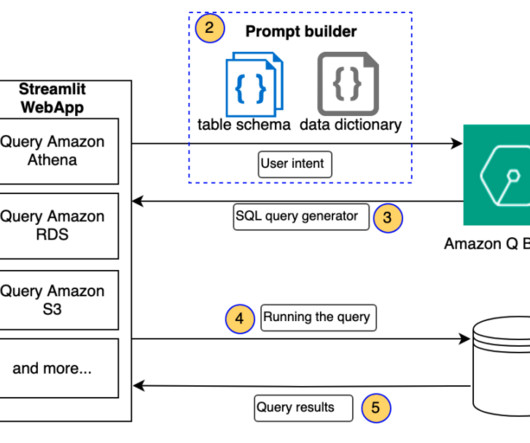
To bridge this gap, you need advanced natural language processing (NLP) to map user queries to database schema, tables, and operations. In this post, we discuss an architecture to query structured data using Amazon Q Business, and build out an application to query cost and usage data in Amazon Athena with Amazon Q Business.
To make that possible, your data scientists would need to store enough details about the environment the model was created in and the related metadata so that the model could be recreated with the same or similar outcomes. Your ML platform must have versioning in-built because code and data mostly make up the ML system.
Role of metadata while indexing data in vector databases Metadata plays a crucial role when loading documents into a vector data store in Amazon Bedrock. These identifiers can be used to uniquely reference and retrieve specific documents from the vector data store.
The core challenge lies in developing data pipelines that can handle diverse data sources, the multitude of data entities in each data source, their metadata and access control information, while maintaining accuracy. As a result, they can index one time and reuse that indexed content across use cases.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content