This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Q Business , a new generative AI-powered assistant, can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in an enterprises systems. Large-scale dataingestion is crucial for applications such as document analysis, summarization, research, and knowledge management.
Deltek is continuously working on enhancing this solution to better align it with their specific requirements, such as supporting file formats beyond PDF and implementing more cost-effective approaches for their dataingestion pipeline. The first step is dataingestion, as shown in the following diagram. What is RAG?
By default, Amazon Bedrock encrypts all knowledge base-related data using an AWS managed key. When setting up a dataingestion job for your knowledge base, you can also encrypt the job using a custom AWS Key Management Service (AWS KMS) key. Alternatively, you can choose to use a customer managed key.
Data preparation isn’t just a part of the ML engineering process — it’s the heart of it. Photo by Myriam Jessier on Unsplash To set the stage, let’s examine the nuances between research-phase data and production-phase data. Data is a key differentiator in ML projects (more on this in my blog post below).
In BI systems, data warehousing first converts disparate raw data into clean, organized, and integrated data, which is then used to extract actionable insights to facilitate analysis, reporting, and data-informed decision-making. The pipeline ensures correct, complete, and consistent data.
In this post, we discuss how the IEO developed UNDP’s artificial intelligence and machine learning (ML) platform—named Artificial Intelligence for Development Analytics (AIDA)— in collaboration with AWS, UNDP’s Information and Technology Management Team (UNDP ITM), and the United Nations International Computing Centre (UNICC).
Amazon Personalize is a fully managed machine learning (ML) service that makes it easy for developers to deliver personalized experiences to their users. You follow the same process of dataingestion, training, and creating a batch inference job as in the previous use case. You can also use this for sequential chains.
Amazon Kendra also supports the use of metadata for each source file, which enables both UIs to provide a link to its sources, whether it is the Spack documentation website or a CloudFront link. Furthermore, Amazon Kendra supports relevance tuning , enabling boosting certain data sources.
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machine learning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications. For information about model pricing, refer to Amazon Bedrock pricing.
With Knowledge Bases for Amazon Bedrock, you can securely connect foundation models (FMs) in Amazon Bedrock to your company data for fully managed Retrieval Augmented Generation (RAG). You can now interact with your documents in real time without prior dataingestion or database configuration.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
One such component is a feature store, a tool that stores, shares, and manages features for machine learning (ML) models. Features are the inputs used during training and inference of ML models. Amazon SageMaker Feature Store is a fully managed repository designed specifically for storing, sharing, and managing ML model features.
In the ever-evolving landscape of machine learning, feature management has emerged as a key pain point for ML Engineers at Airbnb. Airbnb recognized the need for a solution that could streamline feature data management, provide real-time updates, and ensure consistency between training and production environments.
Amazon SageMaker Serverless Inference is a purpose-built inference service that makes it easy to deploy and scale machine learning (ML) models. The dataset is a collection of 147,702 product listings with multilingual metadata and 398,212 unique catalogue images. We use the first metadata file in this demo.
We downloaded the data from AWS Data Exchange and processed it in AWS Glue to generate KG files. In Part 2 , we demonstrated how to use Amazon Neptune ML (in Amazon SageMaker ) to train the KG and create KG embeddings. The KG files were stored in Amazon Simple Storage Service (Amazon S3) and then loaded in Amazon Neptune.
In this post, we discuss a machine learning (ML) solution for complex image searches using Amazon Kendra and Amazon Rekognition. Amazon Kendra is an intelligent search service powered by ML, and Amazon Rekognition is an ML service that can identify objects, people, text, scenes, and activities from images or videos.
This approach, when applied to generative AI solutions, means that a specific AI or machine learning (ML) platform configuration can be used to holistically address the operational excellence challenges across the enterprise, allowing the developers of the generative AI solution to focus on business value.
Combining accurate transcripts with Genesys CTR files, Principal could properly identify the speakers, categorize the calls into groups, analyze agent performance, identify upsell opportunities, and conduct additional machine learning (ML)-powered analytics.
Simple methods for time series forecasting use historical values of the same variable whose future values need to be predicted, whereas more complex, machine learning (ML)-based methods use additional information, such as the time series data of related variables. A dataset must conform to the schema defined within Forecast.
Learn about the flow, difficulties, and tools for performing ML clustering at scale Ori Nakar | Principal Engineer, Threat Research | Imperva Given that there are billions of daily botnet attacks from millions of different IPs, the most difficult challenge of botnet detection is choosing the most relevant data.
Amazon DataZone makes it straightforward for engineers, data scientists, product managers, analysts, and business users to access data throughout an organization so they can discover, use, and collaborate to derive data-driven insights.
When machine learning (ML) models are deployed into production and employed to drive business decisions, the challenge often lies in the operation and management of multiple models. That is where Provectus , an AWS Premier Consulting Partner with competencies in Machine Learning, Data & Analytics, and DevOps, stepped in.
AWS provides various services catered to time series data that are low code/no code, which both machine learning (ML) and non-ML practitioners can use for building ML solutions. We recommend running this notebook on Amazon SageMaker Studio , a web-based, integrated development environment (IDE) for ML.
Luckily, we have tried and trusted tools and architectural patterns that provide a blueprint for reliable ML systems. In this article, I’ll introduce you to a unified architecture for ML systems built around the idea of FTI pipelines and a feature store as the central component. But what is an ML pipeline?
It provides the ability to extract structured data, metadata, and other information from documents ingested from SharePoint to provide relevant search results based on the user query. For more information, see Encryption of transient data storage during dataingestion. Choose Next. Abhi Patlolla is a Sr.
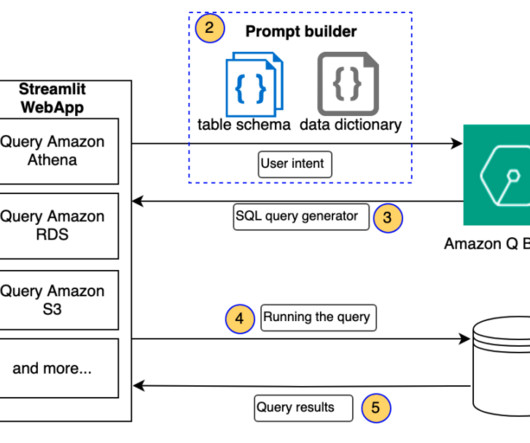
In this post, we discuss an architecture to query structured data using Amazon Q Business, and build out an application to query cost and usage data in Amazon Athena with Amazon Q Business. You can extend this architecture to use additional data sources, query validation, and prompting techniques to cover a wider range of use cases.
Topics Include: Agentic AI DesignPatterns LLMs & RAG forAgents Agent Architectures &Chaining Evaluating AI Agent Performance Building with LangChain and LlamaIndex Real-World Applications of Autonomous Agents Who Should Attend: Data Scientists, Developers, AI Architects, and ML Engineers seeking to build cutting-edge autonomous systems.
From gathering and processing data to building models through experiments, deploying the best ones, and managing them at scale for continuous value in production—it’s a lot. As the number of ML-powered apps and services grows, it gets overwhelming for data scientists and ML engineers to build and deploy models at scale.
These models offer tremendous potential but also bring a unique set of challenges when it comes to building large-scale ML projects. Naturally, training a machine learning model (regardless of the problem being solved or the particular model architecture that was chosen) is a key part of every ML project. But what happens next?
Large Model Quality and Evaluation Anoop Sinha | Research Director, AI & Future Technologies | Google Large model development faces many challenges when it comes to ML quality and evaluation, including the coverage, scale, and wide use cases for what LLMs are used for. Check out a few of them below.
Arranging Efficient Data Streams Modern companies typically receive data from multiple sources. Therefore, quick dataingestion for instant use can be challenging. Machine Learning Integration Opportunities Organizations harness machine learning (ML) algorithms to make forecasts on the data.
These activities cover disparate fields such as basic data processing, analytics, and machine learning (ML). ML is often associated with PBAs, so we start this post with an illustrative figure. The ML paradigm is learning followed by inference. The union of advances in hardware and ML has led us to the current day.
The solution lies in systems that can handle high-throughput dataingestion while providing accurate, real-time insights. A solution lies in adopting a single source of truth for all experiment metadata, encompassing everything from input data and training metrics to checkpoints and outputs. Tools like neptune.ai
Ensure that everyone handling data understands its importance and the role it plays in maintaining data quality. Data Documentation Comprehensive data documentation is essential. Create data dictionaries and metadata repositories to help users understand the data’s structure and context.
You might need to extract the weather and metadata information about the location, after which you will combine both for transformation. In the image, you can see that the extract the weather data and extract metadata information about the location need to run in parallel. This type of execution is shown below.
One of the most prevalent complaints we hear from ML engineers in the community is how costly and error-prone it is to manually go through the ML workflow of building and deploying models. Building end-to-end machine learning pipelines lets ML engineers build once, rerun, and reuse many times. If all goes well, of course ?
The traditional way to solve these problems is to use computer vision machine learning (ML) models to classify the damage and its severity and complement with regression models that predict numerical outcomes based on input features like the make and model of the car, damage severity, damaged part, and more.
Role of metadata while indexing data in vector databases Metadata plays a crucial role when loading documents into a vector data store in Amazon Bedrock. These identifiers can be used to uniquely reference and retrieve specific documents from the vector data store.
A document is a collection of information that consists of a title, the content (or the body), metadata (data about the document), and access control list (ACL) information to make sure answers are provided from documents that the user has access to. When the data source state is Active , choose Sync now.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content