This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this post, we share how Axfood, a large Swedish food retailer, improved operations and scalability of their existing artificial intelligence (AI) and machinelearning (ML) operations by prototyping in close collaboration with AWS experts and using Amazon SageMaker. This is a guest post written by Axfood AB.
In the ever-evolving landscape of machinelearning, feature management has emerged as a key pain point for MLEngineers at Airbnb. Airbnb recognized the need for a solution that could streamline feature data management, provide real-time updates, and ensure consistency between training and production environments.
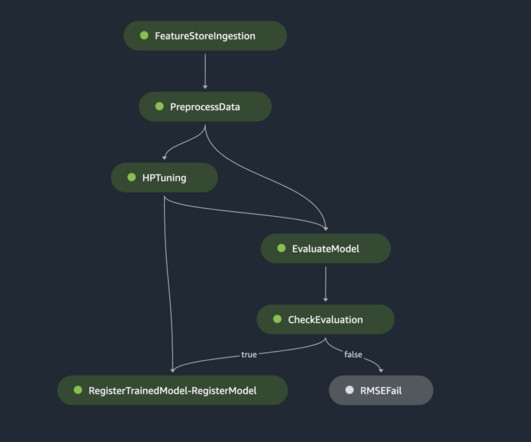
Machinelearning (ML) is becoming increasingly complex as customers try to solve more and more challenging problems. This complexity often leads to the need for distributed ML, where multiple machines are used to train a single model. Ingest the prepared data into the feature group by using the Boto3 SDK.
Data exploration and model development were conducted using well-known machinelearning (ML) tools such as Jupyter or Apache Zeppelin notebooks. Apache Hive was used to provide a tabular interface to data stored in HDFS, and to integrate with Apache Spark SQL.
Training and evaluating models is just the first step toward machine-learning success. For this, we have to build an entire machine-learning system around our models that manages their lifecycle, feeds properly prepared data into them, and sends their output to downstream systems. But what is an ML pipeline?
Data preparation isn’t just a part of the MLengineering process — it’s the heart of it. Photo by Myriam Jessier on Unsplash To set the stage, let’s examine the nuances between research-phase data and production-phase data. This post dives into key steps for preparing data to build real-world ML systems.
MachineLearning Operations (MLOps) can significantly accelerate how data scientists and MLengineers meet organizational needs. The data science team is now expected to be equipped with CI/CD skills to sustain ongoing inference with retraining cycles and automated redeployments of models.
Summary: Vertex AI is a comprehensive platform that simplifies the entire MachineLearning lifecycle. From data preparation and model training to deployment and management, Vertex AI provides the tools and infrastructure needed to build intelligent applications.
The Next Generation of Low-Code MachineLearning Devvret Rishi | Co-founder and Chief Product Officer | Predibase In this session, you’ll explore declarative machinelearning, a configuration-based modeling interface, which provides more flexibility and simplicity when implementing cutting-edge machinelearning.
Today we are excited to bring you just a few of the machinelearning sessions you’ll be able to participate in if you attend. In this session, you’ll take a deep dive into the three distinct types of Feature Stores and their uses in the machinelearning ecosystem. Check them out below. Who Wants to Live Forever?
When machinelearning (ML) models are deployed into production and employed to drive business decisions, the challenge often lies in the operation and management of multiple models. That is where Provectus , an AWS Premier Consulting Partner with competencies in MachineLearning, Data & Analytics, and DevOps, stepped in.
This is often referred to as platform engineering and can be neatly summarized by the mantra “You (the developer) build and test, and we (the platform engineering team) do all the rest!” Leveraging her expertise in Computer Vision and Deep Learning, she empowers customers to harness the power of the ML in AWS cloud efficiently.
How to evaluate MLOps tools and platforms Like every software solution, evaluating MLOps (MachineLearning Operations) tools and platforms can be a complex task as it requires consideration of varying factors. Pay-as-you-go pricing makes it easy to scale when needed.
Do you need help to move your organization’s MachineLearning (ML) journey from pilot to production? Most executives think ML can apply to any business decision, but on average only half of the ML projects make it to production. Ensuring data quality, governance, and security may slow down or stall ML projects.
At ODSC East 2025 , were excited to present 12 curated tracks designed to equip data professionals, machinelearningengineers, and AI practitioners with the tools they need to thrive in this dynamic landscape. MachineLearning TrackDeepen Your ML Expertise Machinelearning remains the backbone of AI innovation.
This post, part of the Governing the ML lifecycle at scale series ( Part 1 , Part 2 , Part 3 ), explains how to set up and govern a multi-account ML platform that addresses these challenges. Usually, there is one lead data scientist for a data science group in a business unit, such as marketing.
The future of business depends on artificial intelligence and machinelearning. According to IDC , 83% of CEOs want their organizations to be more data-driven. Data scientists could be your key to unlocking the potential of the Information Revolution—but what do data scientists do? What Do Data Scientists Do?
Using Graphs for Large Feature Engineering Pipelines Wes Madrigal | MLEngineer | Mad Consulting This talk will outline the complexity of feature engineering from raw entity-level data, the reduction in complexity that comes with composable compute graphs, and an example of the working solution. Sign me up!
One of the most prevalent complaints we hear from MLengineers in the community is how costly and error-prone it is to manually go through the ML workflow of building and deploying models. Building end-to-end machinelearning pipelines lets MLengineers build once, rerun, and reuse many times.
At that point, the Data Scientists or MLEngineers become curious and start looking for such implementations. Many questions regarding building machinelearning pipelines and systems have already been answered and come from industry best practices and patterns. How should the machinelearning pipeline operate?
Moving across the typical machinelearning lifecycle can be a nightmare. From gathering and processing data to building models through experiments, deploying the best ones, and managing them at scale for continuous value in production—it’s a lot. How to understand your users (data scientists, MLengineers, etc.).
For production deployment, the no-code recipes enable easy assembly of the dataingestion pipeline to create a knowledge base and deployment of RAG or agentic chains. These solutions include two primary components: a dataingestion pipeline for building a knowledge base and a system for knowledge retrieval and summarization.
Data lineage and auditing – Metadata can provide information about the provenance and lineage of documents, such as the source system, dataingestion pipeline, or other transformations applied to the data. This information can be valuable for data governance, auditing, and compliance purposes.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























Let's personalize your content