This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
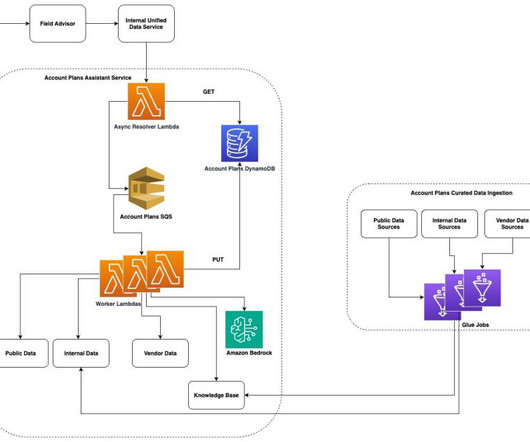
One of these strategies is using Amazon Simple Storage Service (Amazon S3) folder structures and Amazon Bedrock Knowledge Bases metadata filtering to enable efficient data segmentation within a single knowledge base. The S3 bucket, containing customer data and metadata, is configured as a knowledge base data source.
Amazon Q Business , a new generative AI-powered assistant, can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in an enterprises systems. Large-scale dataingestion is crucial for applications such as document analysis, summarization, research, and knowledge management.
As AI models grow and data volumes expand, databases must scale horizontally, to allow organisations to add capacity without significant downtime or performance degradation. Additionally, they accelerate time-to-market for AI-driven innovations by enabling rapid dataingestion and retrieval, facilitating faster experimentation.
The assistant then orchestrates a multi-source data collection process, performing web searches while also pulling account metadata from OpenSearch, Amazon DynamoDB , and Amazon Simple Storage Service (Amazon S3) storage.
It demands substantial effort in data preparation, coupled with a difficult optimization procedure, necessitating a certain level of machinelearning expertise. Data Indexes : Post dataingestion, LlamaIndex assists in indexing this data into a retrievable format.
In the ever-evolving landscape of machinelearning, feature management has emerged as a key pain point for ML Engineers at Airbnb. Airbnb recognized the need for a solution that could streamline feature data management, provide real-time updates, and ensure consistency between training and production environments.
Deltek is continuously working on enhancing this solution to better align it with their specific requirements, such as supporting file formats beyond PDF and implementing more cost-effective approaches for their dataingestion pipeline. The first step is dataingestion, as shown in the following diagram. What is RAG?
In BI systems, data warehousing first converts disparate raw data into clean, organized, and integrated data, which is then used to extract actionable insights to facilitate analysis, reporting, and data-informed decision-making. The pipeline ensures correct, complete, and consistent data.
Amazon DataZone makes it straightforward for engineers, data scientists, product managers, analysts, and business users to access data throughout an organization so they can discover, use, and collaborate to derive data-driven insights. On the Asset catalog tab, search for and choose the data asset Bank.
Training and evaluating models is just the first step toward machine-learning success. For this, we have to build an entire machine-learning system around our models that manages their lifecycle, feeds properly prepared data into them, and sends their output to downstream systems. But what is an ML pipeline?
Amazon Kendra also supports the use of metadata for each source file, which enables both UIs to provide a link to its sources, whether it is the Spack documentation website or a CloudFront link. Furthermore, Amazon Kendra supports relevance tuning , enabling boosting certain data sources.
Amazon Personalize is a fully managed machinelearning (ML) service that makes it easy for developers to deliver personalized experiences to their users. You follow the same process of dataingestion, training, and creating a batch inference job as in the previous use case. You can also use this for sequential chains.
How to evaluate MLOps tools and platforms Like every software solution, evaluating MLOps (MachineLearning Operations) tools and platforms can be a complex task as it requires consideration of varying factors. Pay-as-you-go pricing makes it easy to scale when needed.
This post dives into key steps for preparing data to build real-world ML systems. Dataingestion ensures that all relevant data is aggregated, documented, and traceable. Connecting to Data: Data may be scattered across formats, sources, and frequencies. Join thousands of data leaders on the AI newsletter.
With Knowledge Bases for Amazon Bedrock, you can securely connect foundation models (FMs) in Amazon Bedrock to your company data for fully managed Retrieval Augmented Generation (RAG). You can now interact with your documents in real time without prior dataingestion or database configuration.
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machinelearning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications. For information about model pricing, refer to Amazon Bedrock pricing.
One such component is a feature store, a tool that stores, shares, and manages features for machinelearning (ML) models. A feature store maintains user profile data. A media metadata store keeps the promotion movie list up to date. Features are the inputs used during training and inference of ML models.
The Next Generation of Low-Code MachineLearning Devvret Rishi | Co-founder and Chief Product Officer | Predibase In this session, you’ll explore declarative machinelearning, a configuration-based modeling interface, which provides more flexibility and simplicity when implementing cutting-edge machinelearning.
This approach, when applied to generative AI solutions, means that a specific AI or machinelearning (ML) platform configuration can be used to holistically address the operational excellence challenges across the enterprise, allowing the developers of the generative AI solution to focus on business value.
This mapping can be done by manually mapping frequent OOC queries to catalog content or can be automated using machinelearning (ML). In this post, we illustrate how to handle OOC by utilizing the power of the IMDb dataset (the premier source of global entertainment metadata) and knowledge graphs.
Combining accurate transcripts with Genesys CTR files, Principal could properly identify the speakers, categorize the calls into groups, analyze agent performance, identify upsell opportunities, and conduct additional machinelearning (ML)-powered analytics.
In this post, we discuss a machinelearning (ML) solution for complex image searches using Amazon Kendra and Amazon Rekognition. With an understanding of the problem and solution, the subsequent sections dive into how to automate data sourcing through the crawling of architecture diagrams from credible sources.
Amazon SageMaker Serverless Inference is a purpose-built inference service that makes it easy to deploy and scale machinelearning (ML) models. The dataset is a collection of 147,702 product listings with multilingual metadata and 398,212 unique catalogue images. We use the first metadata file in this demo.
Time series forecasting refers to the process of predicting future values of time series data (data that is collected at regular intervals over time). Each dataset group can have up to three datasets, one of each dataset type: target time series (TTS), related time series (RTS), and item metadata.
In this post, we discuss how the IEO developed UNDP’s artificial intelligence and machinelearning (ML) platform—named Artificial Intelligence for Development Analytics (AIDA)— in collaboration with AWS, UNDP’s Information and Technology Management Team (UNDP ITM), and the United Nations International Computing Centre (UNICC).
AWS provides various services catered to time series data that are low code/no code, which both machinelearning (ML) and non-ML practitioners can use for building ML solutions. Refer to the Amazon Forecast Developer Guide for information about dataingestion , predictor training , and generating forecasts.
When machinelearning (ML) models are deployed into production and employed to drive business decisions, the challenge often lies in the operation and management of multiple models. That is where Provectus , an AWS Premier Consulting Partner with competencies in MachineLearning, Data & Analytics, and DevOps, stepped in.
The recent strides made in the field of machinelearning have given us an array of powerful language models and algorithms. In this blog post we will discuss the importance of LLMOps principles and best practices, which will enable you to take your existing or new machinelearning projects to the next level.
At ODSC East 2025 , were excited to present 12 curated tracks designed to equip data professionals, machinelearning engineers, and AI practitioners with the tools they need to thrive in this dynamic landscape. MachineLearning TrackDeepen Your ML Expertise Machinelearning remains the backbone of AI innovation.
It provides the ability to extract structured data, metadata, and other information from documents ingested from SharePoint to provide relevant search results based on the user query. For more information, see Encryption of transient data storage during dataingestion. Choose Next.
Prerequisites To implement this solution, you need the following: Historical and real-time user click data for the interactions dataset Historical and real-time news article metadata for the items dataset Ingest and prepare the data To train a model in Amazon Personalize, you need to provide training data.
Streamlining Unstructured Data for Retrieval Augmented Generatio n Matt Robinson | Open Source Tech Lead | Unstructured Learn about the complexities of handling unstructured data, and practical strategies for extracting usable text and metadata from it. You’ll also discuss loading processed data into destination storage.
Arranging Efficient Data Streams Modern companies typically receive data from multiple sources. Therefore, quick dataingestion for instant use can be challenging. MachineLearning Integration Opportunities Organizations harness machinelearning (ML) algorithms to make forecasts on the data.
These work together to enable efficient data processing and analysis: · Hive Metastore It is a central repository that stores metadata about Hive’s tables, partitions, and schemas. It applies the data structure during querying rather than dataingestion.
Ensure that everyone handling data understands its importance and the role it plays in maintaining data quality. Data Documentation Comprehensive data documentation is essential. Create data dictionaries and metadata repositories to help users understand the data’s structure and context.
These activities cover disparate fields such as basic data processing, analytics, and machinelearning (ML). The following table shows the metadata of three of the largest accelerated compute instances. Machinelearning Generative AI is the most topical ML application at this point in time.
MachineLearning Operations (MLOps) vs Large Language Model Operations (LLMOps) LLMOps fall under MLOps (MachineLearning Operations). Many MLOps best practices apply to LLMOps, like managing infrastructure, handling data processing pipelines, and maintaining models in production. Specifically focused on LLMs.
You might need to extract the weather and metadata information about the location, after which you will combine both for transformation. In the image, you can see that the extract the weather data and extract metadata information about the location need to run in parallel. This type of execution is shown below.
They run scripts manually to preprocess their training data, rerun the deployment scripts, manually tune their models, and spend their working hours keeping previously developed models up to date. Building end-to-end machinelearning pipelines lets ML engineers build once, rerun, and reuse many times.
Moving across the typical machinelearning lifecycle can be a nightmare. From gathering and processing data to building models through experiments, deploying the best ones, and managing them at scale for continuous value in production—it’s a lot. How to understand your users (data scientists, ML engineers, etc.).
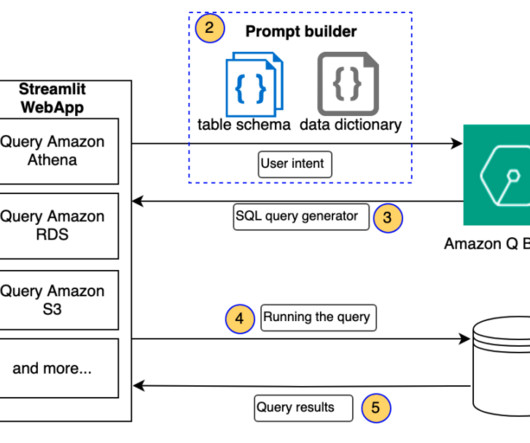
In this post, we discuss an architecture to query structured data using Amazon Q Business, and build out an application to query cost and usage data in Amazon Athena with Amazon Q Business. You can extend this architecture to use additional data sources, query validation, and prompting techniques to cover a wider range of use cases.
The traditional way to solve these problems is to use computer vision machinelearning (ML) models to classify the damage and its severity and complement with regression models that predict numerical outcomes based on input features like the make and model of the car, damage severity, damaged part, and more.
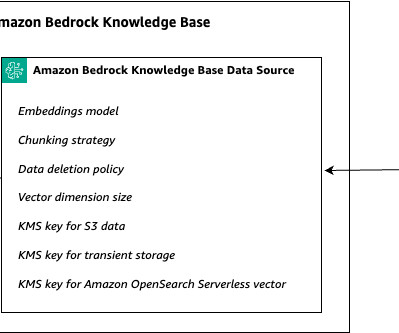
Role of metadata while indexing data in vector databases Metadata plays a crucial role when loading documents into a vector data store in Amazon Bedrock. These identifiers can be used to uniquely reference and retrieve specific documents from the vector data store.
In the context of RAG systems, tenants might have varying requirements for dataingestion frequency, document chunking strategy, or vector search configuration. Metadata filtering can be used in the silo pattern to restrict the search to a subset of documents with a specific characteristic.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content