This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By leveraging machinelearning algorithms, companies can prioritize leads, schedule follow-ups, and handle customer service queries accurately. Dataingested from all these sources, coupled with predictive capability, generates unmatchable analytics.
Prescriptive AI uses machinelearning and optimization models to evaluate various scenarios, assess outcomes, and find the best path forward. This capability is essential for fast-paced industries, helping businesses make quick, data-driven decisions, often with automation.
Amazon Q Business , a new generative AI-powered assistant, can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in an enterprises systems. Large-scale dataingestion is crucial for applications such as document analysis, summarization, research, and knowledge management.
This requires traditional capabilities like encryption, anonymization and tokenization, but also creating capabilities to automatically classify data (sensitivity, taxonomy alignment) by using machinelearning.
Unlike traditional queries that run on a schedule, continuous queries operate non-stop, allowing Drasi to monitor data flows in real time. This means even the smallest data change is captured immediately, giving companies a valuable advantage in responding quickly.
Be sure to check out his talk, “ Apache Kafka for Real-Time MachineLearning Without a Data Lake ,” there! The combination of data streaming and machinelearning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machinelearning tasks using the Apache Kafka ecosystem.
ArangoDB offers the same functionality as Neo4j with more than competitive… arangodb.com In the course of this project, I set up a local instance of ArangoDB using docker, and employed the ArangoDB Python Driver, python-arango, to develop dataingestion scripts. This prevents timeout and reconnect issues.
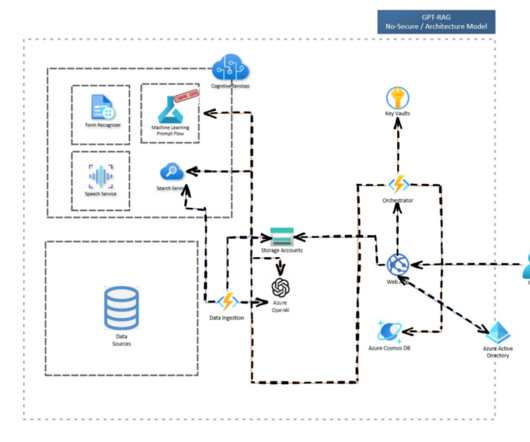
This observability ensures continuity in operations and provides valuable data for optimizing the deployment of LLMs in enterprise settings. The key components of GPT-RAG are dataingestion, Orchestrator, and front-end app.
In this post, we share how Axfood, a large Swedish food retailer, improved operations and scalability of their existing artificial intelligence (AI) and machinelearning (ML) operations by prototyping in close collaboration with AWS experts and using Amazon SageMaker. This is a guest post written by Axfood AB.
Machinelearning (ML) is becoming increasingly complex as customers try to solve more and more challenging problems. This complexity often leads to the need for distributed ML, where multiple machines are used to train a single model. Ingest the prepared data into the feature group by using the Boto3 SDK.
Summary: Dataingestion is the process of collecting, importing, and processing data from diverse sources into a centralised system for analysis. This crucial step enhances data quality, enables real-time insights, and supports informed decision-making. This is where dataingestion comes in.
As AI models grow and data volumes expand, databases must scale horizontally, to allow organisations to add capacity without significant downtime or performance degradation. Additionally, they accelerate time-to-market for AI-driven innovations by enabling rapid dataingestion and retrieval, facilitating faster experimentation.
If you think about building a data pipeline, whether you’re doing a simple BI project or a complex AI or machinelearning project, you’ve got dataingestion, data storage and processing, and data insight – and underneath all of those four stages, there’s a variety of different technologies being used,” explains Faruqui.
Mani Khanuja is a Tech Lead – Generative AI Specialist, author of the book Applied MachineLearning and High Performance Computing on AWS , and a member of the Board of Directors for Women in Manufacturing Education Foundation Board. She enjoys spending time with family and friends, reading, playing volleyball, and teaching others.
For production deployment, the no-code recipes enable easy assembly of the dataingestion pipeline to create a knowledge base and deployment of RAG or agentic chains. These solutions include two primary components: a dataingestion pipeline for building a knowledge base and a system for knowledge retrieval and summarization.
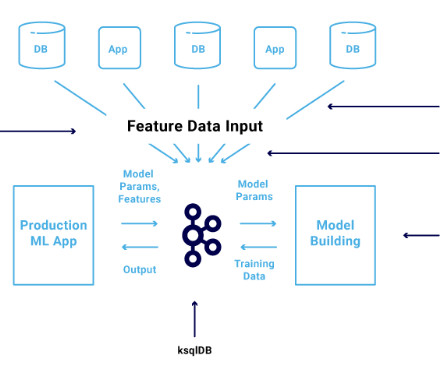
In the ever-evolving landscape of machinelearning, feature management has emerged as a key pain point for ML Engineers at Airbnb. Airbnb recognized the need for a solution that could streamline feature data management, provide real-time updates, and ensure consistency between training and production environments.
Amazon DataZone makes it straightforward for engineers, data scientists, product managers, analysts, and business users to access data throughout an organization so they can discover, use, and collaborate to derive data-driven insights. He supports enterprise customers migrate and modernize their workloads on AWS cloud.
When storing a vector index for your knowledge base in an Aurora database cluster, make sure that the table for your index contains a column for each metadata property in your metadata files before starting dataingestion.
The SageMaker Jumpstart machinelearning hub offers a suite of tools for building, training, and deploying machinelearning models at scale. When combined with Snorkel Flow, it becomes a powerful enabler for enterprises seeking to harness the full potential of their proprietary data.
Universities and other higher learning institutions have collected massive amounts of data over the years, and now they are exploring options to use that data for deeper insights and better educational outcomes. You can use machinelearning (ML) to generate these insights and build predictive models.
Data exploration and model development were conducted using well-known machinelearning (ML) tools such as Jupyter or Apache Zeppelin notebooks. Apache Hive was used to provide a tabular interface to data stored in HDFS, and to integrate with Apache Spark SQL.
At Snorkel, weve partnered with Databricks to create a powerful synergy between their data lakehouse and our Snorkel Flow AI data development platform. Ingesting raw data from Databricks into Snorkel Flow Efficient dataingestion is the foundation of any machinelearning project.
It demands substantial effort in data preparation, coupled with a difficult optimization procedure, necessitating a certain level of machinelearning expertise. Data Indexes : Post dataingestion, LlamaIndex assists in indexing this data into a retrievable format.
MPII is using a machinelearning (ML) bid optimization engine to inform upstream decision-making processes in power asset management and trading. This solution helps market analysts design and perform data-driven bidding strategies optimized for power asset profitability.
Data scientists often spend up to 80% of their time on data engineering in data science projects. Objective of Data Engineering: The main goal is to transform raw data into structured data suitable for downstream tasks such as machinelearning.
At its core, Amazon Bedrock provides the foundational infrastructure for robust performance, security, and scalability for deploying machinelearning (ML) models. Data flow Here is an example of this data flow for an Agent Creator pipeline that involves dataingestion, preprocessing, and vectorization using Chunker and Embedding Snaps.
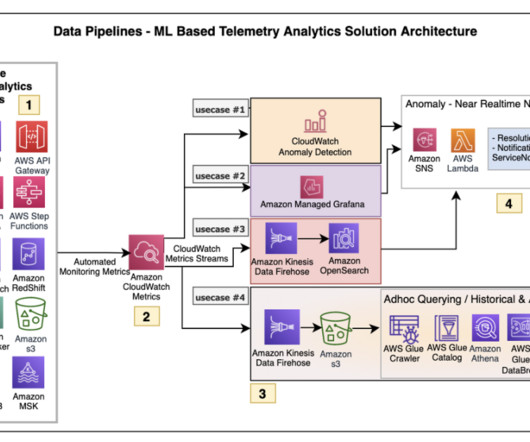
Over the years, an overwhelming surplus of security-related data and alerts from the rapidly expanding cloud digital footprint has put an enormous load on security solutions that need greater scalability, speed and efficiency than ever before.
enhances data management through automated insights generation, self-tuning performance optimization and predictive analytics. It leverages machinelearning algorithms to continuously learn and adapt to workload patterns, delivering superior performance and reducing administrative efforts.
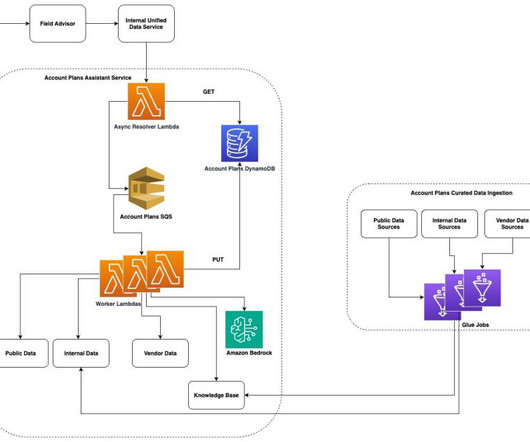
Through its RAG architecture, we semantically search and use metadata filtering to retrieve relevant context from diverse sources: internal sales enablement materials, historic APs, SEC filings, news articles, executive engagements and data from our CRM systems.
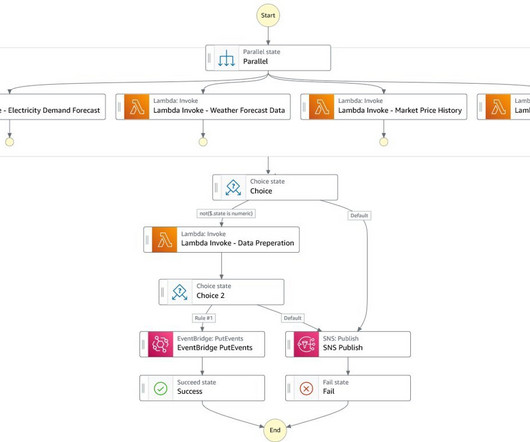
Deltek is continuously working on enhancing this solution to better align it with their specific requirements, such as supporting file formats beyond PDF and implementing more cost-effective approaches for their dataingestion pipeline. The first step is dataingestion, as shown in the following diagram. What is RAG?
Creating RESTful APIs and services with JuliaImage Generated by AI on Gencraft U+1F44B Hello and welcome back to our series to explore the Julia programming language to develop end-to-end machinelearning (ML) projects. In this post, we will introduce a package that could help develop RESTful APIs in Julia U+1F680.
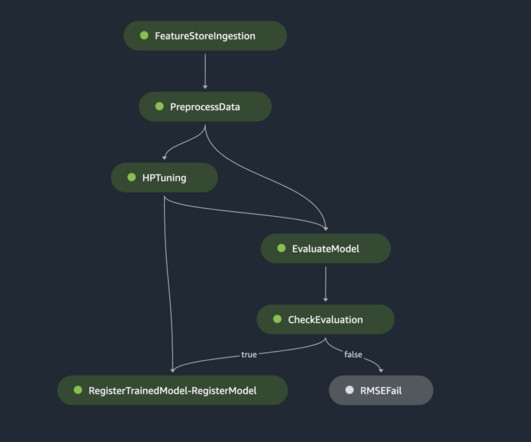
Training and evaluating models is just the first step toward machine-learning success. For this, we have to build an entire machine-learning system around our models that manages their lifecycle, feeds properly prepared data into them, and sends their output to downstream systems. But what is an ML pipeline?
Zeta’s AI innovation is powered by a proprietary machinelearning operations (MLOps) system, developed in-house. Context In early 2023, Zeta’s machinelearning (ML) teams shifted from traditional vertical teams to a more dynamic horizontal structure, introducing the concept of pods comprising diverse skill sets.
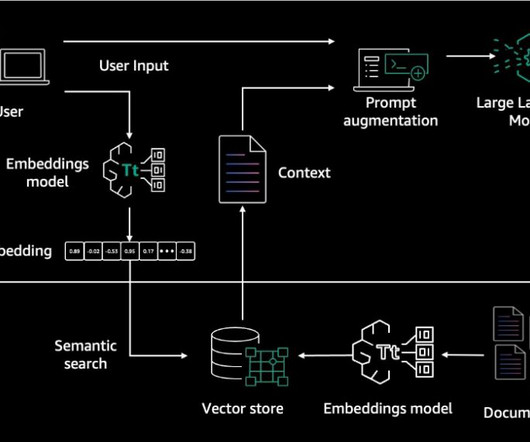
RAG architecture involves two key workflows: data preprocessing through ingestion, and text generation using enhanced context. The dataingestion workflow uses LLMs to create embedding vectors that represent semantic meaning of texts. It offers fully managed dataingestion and text generation workflows.
With this new capability, you can ask questions of your data without the overhead of setting up a vector database or ingestingdata, making it effortless to use your enterprise data. You can now interact with your documents in real time without prior dataingestion or database configuration.
Choose Sync to initiate the dataingestion job. After data synchronization is complete, select the desired FM to use for retrieval and generation (it requires model access to be granted to this FM in Amazon Bedrock before using). He specializes in generative AI, machinelearning, and system design.
In this post, we show you how Amazon Web Services (AWS) helps in solving forecasting challenges by customizing machinelearning (ML) models for forecasting. To use the forecasting data within these applications, an endpoint for the forecasting model is required.
MachineLearning Operations (MLOps) can significantly accelerate how data scientists and ML engineers meet organizational needs. A well-implemented MLOps process not only expedites the transition from testing to production but also offers ownership, lineage, and historical data about ML artifacts used within the team.
The architectures strengths lie in its consistency across environments, automatic dataingestion processes, and comprehensive monitoring capabilities. To learn more about the AWS services used in this solution, refer to the Amazon Q User Guide , Deploy a Slack gateway for Amazon Bedrock , and the Amazon Kendra Developer Guide.
Moving across the typical machinelearning lifecycle can be a nightmare. From gathering and processing data to building models through experiments, deploying the best ones, and managing them at scale for continuous value in production—it’s a lot. How to understand your users (data scientists, ML engineers, etc.).
Choose Sync to initiate the dataingestion job. After the dataingestion job is complete, choose the desired FM to use for retrieval and generation. About the Authors Sandeep Singh is a Senior Generative AI Data Scientist at Amazon Web Services, helping businesses innovate with generative AI.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content