This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
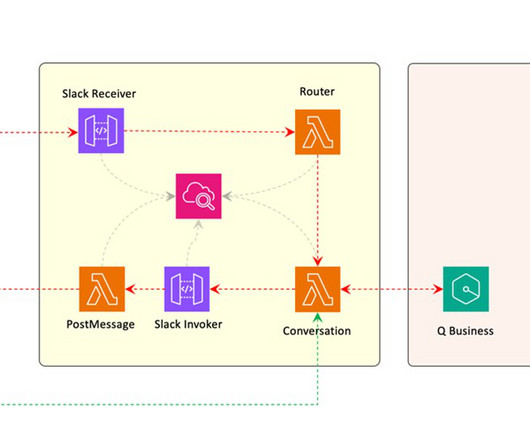
Deltek is continuously working on enhancing this solution to better align it with their specific requirements, such as supporting file formats beyond PDF and implementing more cost-effective approaches for their dataingestion pipeline. The first step is dataingestion, as shown in the following diagram. What is RAG?
This manual synchronization process, hindered by disparate data formats, is resource-intensive, limiting the potential for widespread data orchestration. The platform, although functional, deals with CSV and JSON files containing hundreds of thousands of rows from various manufacturers, demanding substantial effort for dataingestion.
By moving our core infrastructure to Amazon Q, we no longer needed to choose a large language model (LLM) and optimize our use of it, manage Amazon Bedrock agents, a vector database and semantic search implementation, or custom pipelines for dataingestion and management.
This week, I’m super excited to announce that we are finally releasing our book, ‘Building AI for Production; Enhancing LLM Abilities and Reliability with Fine-Tuning and RAG,’ where we gathered all our learnings. The design is similar to a traditional application but considers LLM-powered application-specific characters and components.
You follow the same process of dataingestion, training, and creating a batch inference job as in the previous use case. They can also introduce context and memory into LLMs by connecting and chaining LLM prompts to solve for varying use cases. Rishabh Agrawal is a Senior SoftwareEngineer working on AI services at AWS.
Fine Tuning Strategies for Language Models and Large Language Models Kevin Noel | AI Lead at Uzabase Speeda | Uzabase Japan-US Language Models (LM) and Large Language Models (LLM) have proven to have applications across many industries. This talk provides a comprehensive framework for securing LLM applications.
Topics Include: Advanced ML Algorithms & EnsembleMethods Hyperparameter Tuning & Model Optimization AutoML & Real-Time MLSystems Explainable AI & EthicalAI Time Series Forecasting & NLP Techniques Who Should Attend: ML Engineers, Data Scientists, and Technical Practitioners working on production-level ML solutions.
Core features of end-to-end MLOps platforms End-to-end MLOps platforms combine a wide range of essential capabilities and tools, which should include: Data management and preprocessing : Provide capabilities for dataingestion, storage, and preprocessing, allowing you to efficiently manage and prepare data for training and evaluation.
Agent Creator is a no-code visual tool that empowers business users and application developers to create sophisticated large language model (LLM) powered applications and agents without programming expertise. LLM Snap Pack – Facilitates interactions with Claude and other language models.
It involves two key workflows: dataingestion and text generation. The dataingestion workflow creates semantic embeddings for documents and questions, storing document embeddings in a vector database. This bucket is designated as the knowledge base data source. Anthropic’s Claude Sonnet 3.5
As enterprises adopt generative AI, many are developing intelligent assistants powered by Retrieval Augmented Generation (RAG) to take advantage of information and knowledge from their enterprise data repositories. This approach combines a retriever with an LLM to generate responses.
When inference data is ingested on Amazon S3, EventBridge automatically runs the inference pipeline. This automated workflow streamlines the entire process, from dataingestion to inference, reducing manual interventions and minimizing the risk of errors. In his spare time, Mones enjoys operatic singing and scuba diving.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















Let's personalize your content