This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
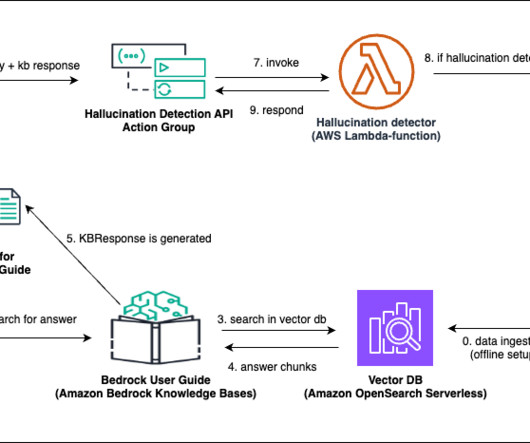
Deltek is continuously working on enhancing this solution to better align it with their specific requirements, such as supporting file formats beyond PDF and implementing more cost-effective approaches for their dataingestion pipeline. The first step is dataingestion, as shown in the following diagram. What is RAG?
It’s a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like Anthropic, Cohere, Meta, Mistral AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsibleAI.
Fine Tuning Strategies for Language Models and Large Language Models Kevin Noel | AI Lead at Uzabase Speeda | Uzabase Japan-US Language Models (LM) and Large Language Models (LLM) have proven to have applications across many industries. This talk provides a comprehensive framework for securing LLM applications.
As long as the LookML file doesn’t exceed the context window of the LLM used to generate the final response, we don’t split the file into chunks and instead pass the file in its entirety to the embeddings model. The two subsets of LookML metadata provide distinct types of information about the data lake.
Combining healthcare-specific LLMs along with a terminology service and scalable dataingestion pipelines, it excels in complex queries and is ideal for organizations seeking OMOP data enrichment.
The AI Paradigm Shift: Under the Hood of a Large Language Models Valentina Alto | Azure Specialist — Data and Artificial Intelligence | Microsoft Develop an understanding of Generative AI and Large Language Models, including the architecture behind them, their functioning, and how to leverage their unique conversational capabilities.
Whats Next in AI TrackExplore the Cutting-Edge Stay ahead of the curve with insights into the future of AI. This track will cover the latest best practices for managing AI models from development to deployment. This track will guide you in aligning AI systems with ethical standards and minimizing bias.
Core features of end-to-end MLOps platforms End-to-end MLOps platforms combine a wide range of essential capabilities and tools, which should include: Data management and preprocessing : Provide capabilities for dataingestion, storage, and preprocessing, allowing you to efficiently manage and prepare data for training and evaluation.
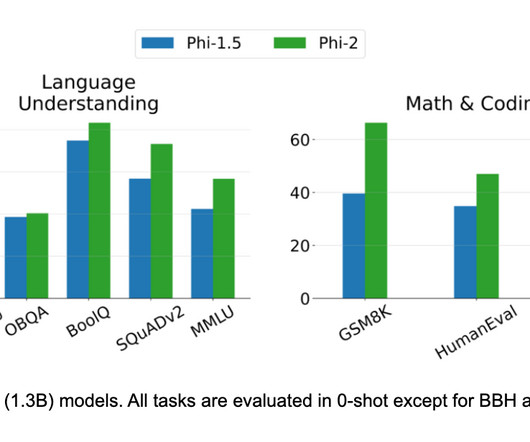
ResponsibleAI Development: Phi-2 highlights the importance of considering responsible development practices when building large language models. FlashInfer emerges as a powerful open-source library focused on optimizing attention kernels , the lifeblood of LLM performance.
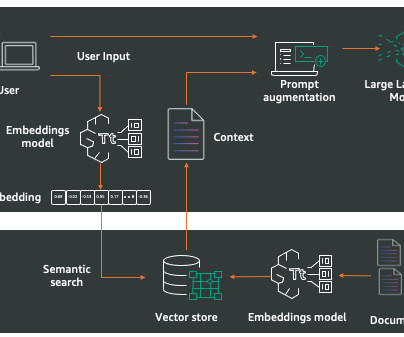
Hallucinations in large language models (LLMs) refer to the phenomenon where the LLM generates an output that is plausible but factually incorrect or made-up. The retriever module is responsible for retrieving relevant passages or documents from a large corpus of textual data based on the input query or context.
To demonstrate, we create a generative AI-enabled Slack assistant with an integration to Amazon Bedrock Knowledge Bases that can expose the combined knowledge of the AWS Well-Architected Framework while implementing safeguards and responsibleAI using Amazon Bedrock Guardrails.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsibleAI.
This post dives deep into Amazon Bedrock Knowledge Bases , which helps with the storage and retrieval of data in vector databases for RAG-based workflows, with the objective to improve large language model (LLM) responses for inference involving an organization’s datasets. The LLMresponse is passed back to the agent.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















Let's personalize your content