This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
One of these strategies is using Amazon Simple Storage Service (Amazon S3) folder structures and Amazon Bedrock Knowledge Bases metadata filtering to enable efficient data segmentation within a single knowledge base. The S3 bucket, containing customer data and metadata, is configured as a knowledge base data source.
In the generative AI or traditional AI development cycle, dataingestion serves as the entry point. Here, raw data that is tailored to a company’s requirements can be gathered, preprocessed, masked and transformed into a format suitable for LLMs or other models. Increased variance: Variance measures consistency.
In-context learning has emerged as an alternative, prioritizing the crafting of inputs and prompts to provide the LLM with the necessary context for generating accurate outputs. This approach mitigates the need for extensive model retraining, offering a more efficient and accessible means of integrating private data.
Contrast that with Scope 4/5 applications, where not only do you build and secure the generative AI application yourself, but you are also responsible for fine-tuning and training the underlying large language model (LLM). LLM and LLM agent The LLM provides the core generative AI capability to the assistant.
Deltek is continuously working on enhancing this solution to better align it with their specific requirements, such as supporting file formats beyond PDF and implementing more cost-effective approaches for their dataingestion pipeline. The first step is dataingestion, as shown in the following diagram. What is RAG?
This post highlights how Twilio enabled natural language-driven data exploration of business intelligence (BI) data with RAG and Amazon Bedrock. Twilio’s use case Twilio wanted to provide an AI assistant to help their data analysts find data in their data lake.
You follow the same process of dataingestion, training, and creating a batch inference job as in the previous use case. They can also introduce context and memory into LLMs by connecting and chaining LLM prompts to solve for varying use cases. We are excited to launch LangChain integration.
The personalization of LLM applications can be achieved by incorporating up-to-date user information, which typically involves integrating several components. These task-specific prompts are then fed into the LLM, which is tasked with predicting the likelihood of interaction between a particular user and item.
Other steps include: dataingestion, validation and preprocessing, model deployment and versioning of model artifacts, live monitoring of large language models in a production environment, monitoring the quality of deployed models and potentially retraining them. Why are these elements so important? monitoring and automation).
Additionally, you can enable model invocation logging to collect invocation logs, full request response data, and metadata for all Amazon Bedrock model API invocations in your AWS account. Before you can enable invocation logging, you need to set up an Amazon Simple Storage Service (Amazon S3) or CloudWatch Logs destination.
Fine Tuning Strategies for Language Models and Large Language Models Kevin Noel | AI Lead at Uzabase Speeda | Uzabase Japan-US Language Models (LM) and Large Language Models (LLM) have proven to have applications across many industries. This talk provides a comprehensive framework for securing LLM applications.
Core features of end-to-end MLOps platforms End-to-end MLOps platforms combine a wide range of essential capabilities and tools, which should include: Data management and preprocessing : Provide capabilities for dataingestion, storage, and preprocessing, allowing you to efficiently manage and prepare data for training and evaluation.
Combining healthcare-specific LLMs along with a terminology service and scalable dataingestion pipelines, it excels in complex queries and is ideal for organizations seeking OMOP data enrichment.
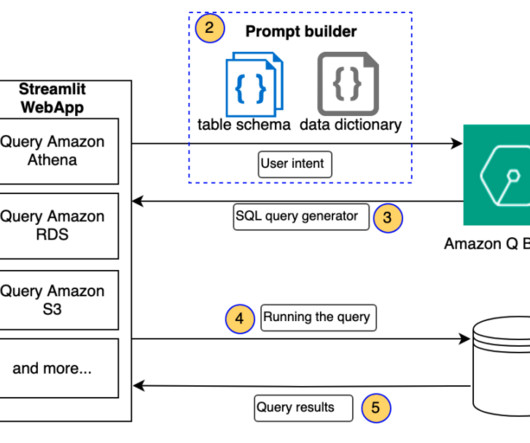
In this post, we discuss an architecture to query structured data using Amazon Q Business, and build out an application to query cost and usage data in Amazon Athena with Amazon Q Business. You can extend this architecture to use additional data sources, query validation, and prompting techniques to cover a wider range of use cases.
Streamlining Unstructured Data for Retrieval Augmented Generatio n Matt Robinson | Open Source Tech Lead | Unstructured Learn about the complexities of handling unstructured data, and practical strategies for extracting usable text and metadata from it. You’ll also discuss loading processed data into destination storage.
Topics Include: MLOps Fundamentals LLM Deployment & Monitoring Cloud Infrastructure forLLMs Observability & Cost Management Operationalizing Local LLMs Responsibly Who Should Attend: MLOps Engineers, Data Scientists, and AI Developers responsible for deploying AIsystems.
TL;DR LLMOps involves managing the entire lifecycle of Large Language Models (LLMs), including data and prompt management, model fine-tuning and evaluation, pipeline orchestration, and LLM deployment. Prompt-response management: Refining LLM-backed applications through continuous prompt-response optimization and quality control.
In order to train transformer models on internet-scale data, huge quantities of PBAs were needed. In November 2022, ChatGPT was released, a large language model (LLM) that used the transformer architecture, and is widely credited with starting the current generative AI boom. 32xlarge 0 16 0 128 512 512 4 x 1.9
This metadata includes details such as make, model, year, area of the damage, severity of the damage, parts replacement cost, and labor required to repair. The information contained in these datasets—the images and the corresponding metadata—is converted to numerical vectors using a process called multimodal embedding.
This post dives deep into Amazon Bedrock Knowledge Bases , which helps with the storage and retrieval of data in vector databases for RAG-based workflows, with the objective to improve large language model (LLM) responses for inference involving an organization’s datasets. The LLM response is passed back to the agent.
As enterprises adopt generative AI, many are developing intelligent assistants powered by Retrieval Augmented Generation (RAG) to take advantage of information and knowledge from their enterprise data repositories. This approach combines a retriever with an LLM to generate responses.
Next, you need to index this data to make it available for a Retrieval Augmented Generation (RAG) approach, where relevant passages are delivered with high accuracy to a large language model (LLM). A data source connector is a component of Amazon Q that helps integrate and synchronize data from multiple repositories into one index.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























Let's personalize your content