This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
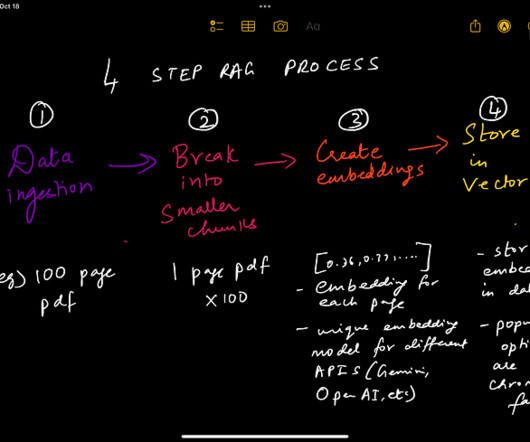
In the generative AI or traditional AI development cycle, dataingestion serves as the entry point. Here, raw data that is tailored to a company’s requirements can be gathered, preprocessed, masked and transformed into a format suitable for LLMs or other models. Increased variance: Variance measures consistency.
In-context learning has emerged as an alternative, prioritizing the crafting of inputs and prompts to provide the LLM with the necessary context for generating accurate outputs. This approach mitigates the need for extensive model retraining, offering a more efficient and accessible means of integrating private data.
This achievement follows the unveiling of Inflection-1, Inflection AI's in-house large language model (LLM), which has been hailed as the best model in its compute class. As a vertically integrated AI studio, Inflection AI handles the entire process in-house, from dataingestion and model design to high-performance infrastructure.
Contrast that with Scope 4/5 applications, where not only do you build and secure the generative AI application yourself, but you are also responsible for fine-tuning and training the underlying large language model (LLM). LLM and LLM agent The LLM provides the core generative AI capability to the assistant.
The platform’s interactive UI, powered by Gradio, enhances the user experience by simplifying the dataingestion and parsing process. It eliminates the need for numerous independent tools by offering a unified solution for dataingestion and parsing.
Configuring the Language Model Next, we configure the language model that will answer our questions: llm = ChatGoogleGenerativeAI(model="gemini-1.5-pro", 📔This is a beginner-friendly tutorial so quick notes on Retrieval Augmented Generation (RAG) and LangChain before we get started with the hands-on. pro", temperature=0.3,
At Snorkel, weve partnered with Databricks to create a powerful synergy between their data lakehouse and our Snorkel Flow AI data development platform. Ingesting raw data from Databricks into Snorkel Flow Efficient dataingestion is the foundation of any machine learning project.
The integration between the Snorkel Flow AI data development platform and AWS’s robust AI infrastructure empowers enterprises to streamline LLM evaluation and fine-tuning, transforming raw data into actionable insights and competitive advantages. Here’s what that looks like in practice.
Deltek is continuously working on enhancing this solution to better align it with their specific requirements, such as supporting file formats beyond PDF and implementing more cost-effective approaches for their dataingestion pipeline. The first step is dataingestion, as shown in the following diagram. What is RAG?
As generative AI continues to grow, the need for an efficient, automated solution to transform various data types into an LLM-ready format has become even more apparent. Meet MegaParse : an open-source tool for parsing various types of documents for LLMingestion. Check out the GitHub Page.
This manual synchronization process, hindered by disparate data formats, is resource-intensive, limiting the potential for widespread data orchestration. The platform, although functional, deals with CSV and JSON files containing hundreds of thousands of rows from various manufacturers, demanding substantial effort for dataingestion.
By facilitating efficient data integration and enhancing LLM performance, LlamaIndex is tailored for scenarios where rapid, accurate access to structured data is paramount. Key Features of LlamaIndex: Data Connectors: Facilitates the integration of various data sources, simplifying the dataingestion process.
Other steps include: dataingestion, validation and preprocessing, model deployment and versioning of model artifacts, live monitoring of large language models in a production environment, monitoring the quality of deployed models and potentially retraining them. Why are these elements so important? monitoring and automation).
The ETL (Extract, Transform, Load) process is also critical in aggregating and processing data from varied sources. Despite their effectiveness, these methods and frameworks must provide a unified, customizable solution for all LLMdata processing needs.
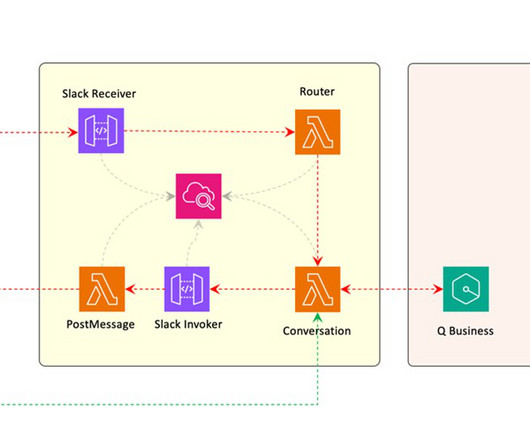
Amazon Q retrieves relevant information from its index, which is populated using data from the connected data sources (Amazon S3 and a web crawler). Amazon Q then generates a response using its internal large language model (LLM) and presents it to the user through the Amazon Q web UI.
Introduction Large Language Models (LLMs) have opened up a new world of possibilities, powering everything from advanced chatbots to autonomous AI agents. However, to unlock their full potential, you often need robust frameworks that handle dataingestion, prompt engineering, memory storage, and tool usage.
However, building a successful LLM application involves much more than just leveraging advanced technology. When embarking on the journey of building an LLM application, one of the first and most crucial decisions is choosing the foundation model. Create Targeted Evaluation Sets for Comparing LLM Performance in Your Specific Use Case.
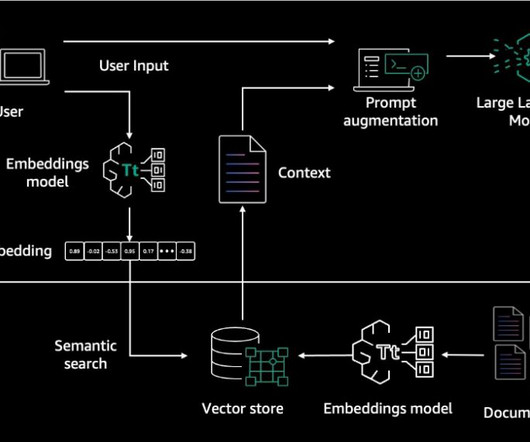
RAG architecture involves two key workflows: data preprocessing through ingestion, and text generation using enhanced context. The dataingestion workflow uses LLMs to create embedding vectors that represent semantic meaning of texts. It offers fully managed dataingestion and text generation workflows.
Introduction Retrieval-Augmented Generation (RAG) systems have emerged as a powerful approach to building LLM-powered applications. RAG systems operate by first retrieving information from external knowledge sources using a retrieval model, and then using this information to prompt LLMs to generate responses. pip install dspy-ai==2.0.8
LlamaIndex Llama Index is a Python-based framework designed for constructing LLM applications. It acts as a versatile and straightforward data framework, seamlessly connecting custom data sources to LLMs. Phoenix introduces LLM Traces, allowing users to trace the execution of their LLM Applications.
Image by Narciso on Pixabay Introduction Query Pipelines is a new declarative API to orchestrate simple-to-advanced workflows within LlamaIndex to query over your data. Other frameworks have built similar approaches, an easier way to build LLM workflows over your data like RAG systems, query unstructured data or structured data extraction.
Introduction Retrieval-Augmented Generation (RAG) systems have emerged as a powerful approach to building LLM-powered applications. RAG systems operate by first retrieving information from external knowledge sources using a retrieval model, and then using this information to prompt LLMs to generate responses. pip install dspy-ai==2.0.8
Fine Tuning Strategies for Language Models and Large Language Models Kevin Noel | AI Lead at Uzabase Speeda | Uzabase Japan-US Language Models (LM) and Large Language Models (LLM) have proven to have applications across many industries. This talk provides a comprehensive framework for securing LLM applications.
By moving our core infrastructure to Amazon Q, we no longer needed to choose a large language model (LLM) and optimize our use of it, manage Amazon Bedrock agents, a vector database and semantic search implementation, or custom pipelines for dataingestion and management.
As long as the LookML file doesn’t exceed the context window of the LLM used to generate the final response, we don’t split the file into chunks and instead pass the file in its entirety to the embeddings model. The two subsets of LookML metadata provide distinct types of information about the data lake.
You can deploy open-source evaluation metrics like RAGAS as custom metrics to make sure LLM responses are grounded, mitigate bias, and prevent hallucinations. For a more detailed description, see Scaling AI and Machine Learning Workloads with Ray on AWS and Build a RAG dataingestion pipeline for large scale ML workloads.
The personalization of LLM applications can be achieved by incorporating up-to-date user information, which typically involves integrating several components. These task-specific prompts are then fed into the LLM, which is tasked with predicting the likelihood of interaction between a particular user and item.
Unlocking accurate and insightful answers from vast amounts of text is an exciting capability enabled by large language models (LLMs). When building LLM applications, it is often necessary to connect and query external data sources to provide relevant context to the model.
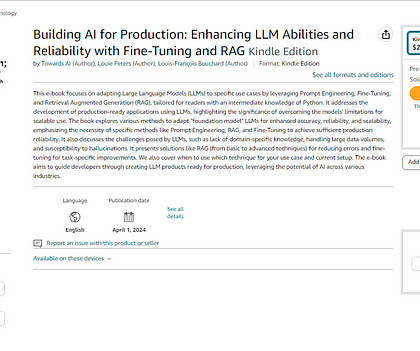
This week, I’m super excited to announce that we are finally releasing our book, ‘Building AI for Production; Enhancing LLM Abilities and Reliability with Fine-Tuning and RAG,’ where we gathered all our learnings. The design is similar to a traditional application but considers LLM-powered application-specific characters and components.
In the RAG-based approach we convert the user question into vector embeddings using an LLM and then do a similarity search for these embeddings in a pre-populated vector database holding the embeddings for the enterprise knowledge corpus. Amazon SageMaker Processing jobs for large scale dataingestion into OpenSearch.
The Hugging Face containers host a large language model (LLM) from the Hugging Face Hub. The service allows for simple audio dataingestion, easy-to-read transcript creation, and accuracy improvement through custom vocabularies. Amazon Transcribe’s new ASR foundation model supports 100+ language variants.
It emphasizes the role of LLamaindex in building RAG systems, managing dataingestion, indexing, and querying. Finally, it offers best practices for fine-tuning, emphasizing data quality, parameter optimization, and leveraging transfer learning techniques. This article examines data leakage in LLMs.
At Snorkel, weve partnered with Databricks to create a powerful synergy between their data lakehouse and our Snorkel Flow AI data development platform. Ingesting raw data from Databricks into Snorkel Flow Efficient dataingestion is the foundation of any machine learning project.
You follow the same process of dataingestion, training, and creating a batch inference job as in the previous use case. They can also introduce context and memory into LLMs by connecting and chaining LLM prompts to solve for varying use cases. We are excited to launch LangChain integration.
The integration between the Snorkel Flow AI data development platform and AWS’s robust AI infrastructure empowers enterprises to streamline LLM evaluation and fine-tuning, transforming raw data into actionable insights and competitive advantages. Heres what that looks like in practice.
Combining healthcare-specific LLMs along with a terminology service and scalable dataingestion pipelines, it excels in complex queries and is ideal for organizations seeking OMOP data enrichment.
Chatbot on custom knowledge base using LLaMA Index — Pragnakalp Techlabs: AI, NLP, Chatbot, Python Development LlamaIndex is an impressive data framework designed to support the development of applications utilizing LLMs (Large Language Models). With LlamaIndex, you can use a smart interface to search and retrieve your data.
LlamaIndex is an impressive data framework designed to support the development of applications utilizing LLMs (Large Language Models). It offers a wide range of essential tools that simplify tasks such as dataingestion, organization, retrieval, and integration with different application frameworks.
Photo by Andrew Neel on Unsplash Introduction If you are working or have worked on any data science task then you definitely used pandas. So, pandas is a library which helps with performing dataingestion and transformations. Here is the github link. Now let's try it out. Latest order date.
Streamlining Unstructured Data for Retrieval Augmented Generatio n Matt Robinson | Open Source Tech Lead | Unstructured Learn about the complexities of handling unstructured data, and practical strategies for extracting usable text and metadata from it. You’ll also discuss loading processed data into destination storage.
Amazon Q Business is a fully managed, secure, generative-AI powered enterprise chat assistant that enables natural language interactions with your organization’s data. By default, Amazon Q Business will only produce responses using the data you’re indexing. This behavior is aligned with the use cases related to our solution.
The Neptune Scale experiment tracker supports fault tolerance and is designed to maintain progress despite hardware failures, making it adaptable for enterprise teams tackling LLM fine-tuning, compliance, and building domain-specific models. Scaling large language model (LLM) operations is a challenge that many of us are facing right now.
The AI Paradigm Shift: Under the Hood of a Large Language Models Valentina Alto | Azure Specialist — Data and Artificial Intelligence | Microsoft Develop an understanding of Generative AI and Large Language Models, including the architecture behind them, their functioning, and how to leverage their unique conversational capabilities.
Tyler wrote a blog post discusses a new method called Mélange for optimizing the cost efficiency of Large Language Model (LLM) deployments by exploiting GPU heterogeneity. Requirements for the new System Notion decided to build an in-house data lake with the following objectives: Store raw and processed data at scale.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































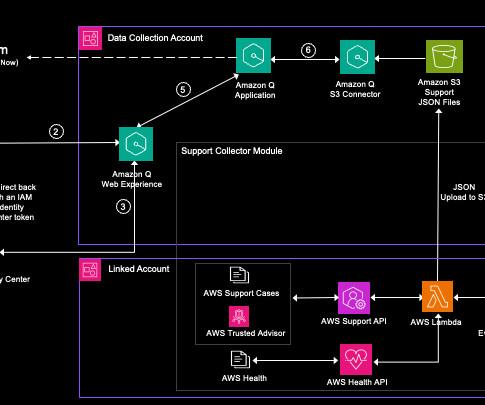


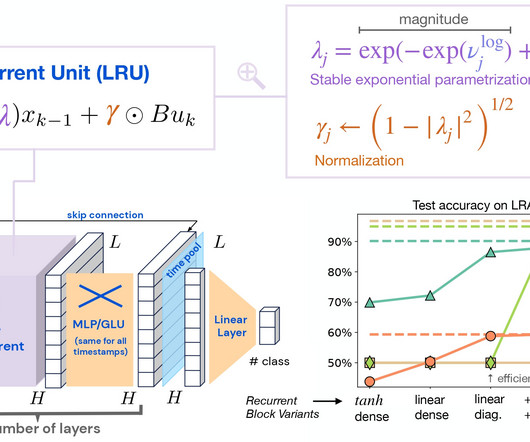






Let's personalize your content