This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
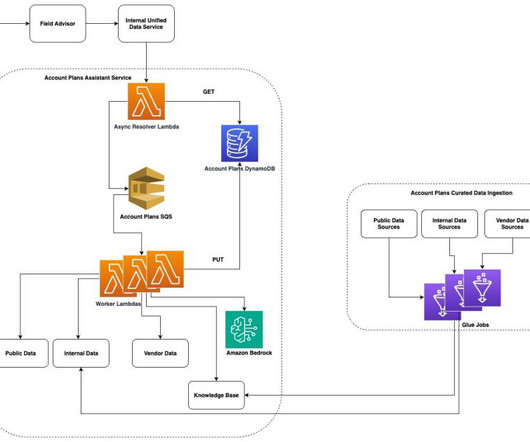
One of these strategies is using Amazon Simple Storage Service (Amazon S3) folder structures and Amazon Bedrock Knowledge Bases metadata filtering to enable efficient data segmentation within a single knowledge base. The S3 bucket, containing customer data and metadata, is configured as a knowledge base data source.
Companies still often accept the risk of using internal data when exploring largelanguagemodels (LLMs) because this contextual data is what enables LLMs to change from general-purpose to domain-specific knowledge. In the generative AI or traditional AI development cycle, dataingestion serves as the entry point.
Mid-market Account Manager Amazon Q, Amazon Bedrock, and other AWS services underpin this experience, enabling us to use largelanguagemodels (LLMs) and knowledge bases (KBs) to generate relevant, data-driven content for APs. Its a game-changer for serving my full portfolio of accounts.
In this post, we show you an example of a generative AI assistant application and demonstrate how to assess its security posture using the OWASP Top 10 for LargeLanguageModel Applications , as well as how to apply mitigations for common threats. Alternatively, you can choose to use a customer managed key.
Largelanguagemodels (LLMs) like OpenAI's GPT series have been trained on a diverse range of publicly accessible data, demonstrating remarkable capabilities in text generation, summarization, question answering, and planning. Among the indexes, ‘VectorStoreIndex' is often the go-to choice.
To start simply, you could think of LLMOps ( LargeLanguageModel Operations) as a way to make machine learning work better in the real world over a long period of time. As previously mentioned: model training is only part of what machine learning teams deal with. What is LLMOps? Why are these elements so important?
Retrieval Augmented Generation (RAG) has emerged as a leading method for using the power of largelanguagemodels (LLMs) to interact with documents in natural language. The first step is dataingestion, as shown in the following diagram. This structure can be used to optimize dataingestion.
You follow the same process of dataingestion, training, and creating a batch inference job as in the previous use case. Announcing LangChain integration to seamlessly integrate Amazon Personalize with the LangChain framework LangChain is a powerful open-source framework that allows for integration with largelanguagemodels (LLMs).
This post highlights how Twilio enabled natural language-driven data exploration of business intelligence (BI) data with RAG and Amazon Bedrock. Twilio’s use case Twilio wanted to provide an AI assistant to help their data analysts find data in their data lake.
Largelanguagemodels (LLMs) are revolutionizing fields like search engines, natural language processing (NLP), healthcare, robotics, and code generation. A feature store maintains user profile data. A media metadata store keeps the promotion movie list up to date.
Core features of end-to-end MLOps platforms End-to-end MLOps platforms combine a wide range of essential capabilities and tools, which should include: Data management and preprocessing : Provide capabilities for dataingestion, storage, and preprocessing, allowing you to efficiently manage and prepare data for training and evaluation.
The teams built a new dataingestion mechanism, allowing the CTR files to be jointly delivered with the audio file to an S3 bucket. In the future, Principal plans to continue expanding postprocessing capabilities with additional data aggregation, analytics, and natural language generation (NLG) models for text summarization.
Opensearch Dashboards provides powerful search and analytical capabilities, allowing teams to dive deeper into generative AI model behavior, user interactions, and system-wide metrics. This workflow includes the following steps: Data can be securely transferred to AWS using either custom or existing tools or the AWS Transfer family.
As one of the most rapidly developing fields in AI, the capabilities for and applications of LargeLanguageModels (LLMs) are changing and growing continuously. It can be hard to keep on top of all the advancements. At ODSC West this October 29th-31st, you’ll find a wide range of workshops, tutorials, and talks on LLMs and RAG.
This talk will explore a new capability that transforms diverse clinical data (EHR, FHIR, notes, and PDFs) into a unified patient timeline, enabling natural language question answering.
Topics Include: Agentic AI DesignPatterns LLMs & RAG forAgents Agent Architectures &Chaining Evaluating AI Agent Performance Building with LangChain and LlamaIndex Real-World Applications of Autonomous Agents Who Should Attend: Data Scientists, Developers, AI Architects, and ML Engineers seeking to build cutting-edge autonomous systems.
Amazon SageMaker Canvas is a no-code machine learning (ML) service that empowers business analysts and domain experts to build, train, and deploy ML models without writing a single line of code. As the data scientist, complete the following steps: In the Environments section of the Banking-Consumer-ML project, choose SageMaker Studio.
TL;DR LLMOps involves managing the entire lifecycle of LargeLanguageModels (LLMs), including data and prompt management, model fine-tuning and evaluation, pipeline orchestration, and LLM deployment. What is LargeLanguageModel Operations (LLMOps)? What the future of LLMOps looks like.
During my talk at NeurIPS, I broke down five key lessons learned from teams facing large-scale model training and monitoring. Real-time monitoring prevents costly failures Imagine this: you’re training a largelanguagemodel on thousands of GPUs at a cost of hundreds of thousands of dollars per day.
In order to train transformer models on internet-scale data, huge quantities of PBAs were needed. In November 2022, ChatGPT was released, a largelanguagemodel (LLM) that used the transformer architecture, and is widely credited with starting the current generative AI boom. 32xlarge 0 16 0 128 512 512 4 x 1.9
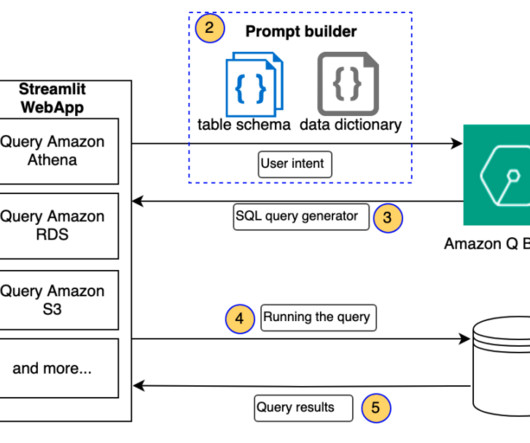
One of the most common applications of generative artificial intelligence (AI) and largelanguagemodels (LLMs) in an enterprise environment is answering questions based on the enterprise’s knowledge corpus. In response, Amazon Q Business provides an appropriate Athena query to run.
To make that possible, your data scientists would need to store enough details about the environment the model was created in and the related metadata so that the model could be recreated with the same or similar outcomes. Your ML platform must have versioning in-built because code and data mostly make up the ML system.
Although these models can provide precise estimates based on historical data, they can’t be generalized to provide a quick range of estimates and any changes to the damage dataset (which includes updated makes and models) or varying repair estimates based on parts, labor, and facility. This technique is called semantic search.
AWS customers use Amazon Kendra with largelanguagemodels (LLMs) to quickly create secure, generative AI –powered conversational experiences on top of your enterprise content. This requires implementing information extraction models, optimizing text processing, and balancing sparse and dense retrieval methods.
This post dives deep into Amazon Bedrock Knowledge Bases , which helps with the storage and retrieval of data in vector databases for RAG-based workflows, with the objective to improve largelanguagemodel (LLM) responses for inference involving an organization’s datasets.
Next, you need to index this data to make it available for a Retrieval Augmented Generation (RAG) approach, where relevant passages are delivered with high accuracy to a largelanguagemodel (LLM). When the data source state is Active , choose Sync now.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content