This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Companies still often accept the risk of using internal data when exploring largelanguagemodels (LLMs) because this contextual data is what enables LLMs to change from general-purpose to domain-specific knowledge. In the generative AI or traditional AI development cycle, dataingestion serves as the entry point.
Generative AI has altered the tech industry by introducing new data risks, such as sensitive data leakage through largelanguagemodels (LLMs), and driving an increase in requirements from regulatory bodies and governments.
With the incorporation of largelanguagemodels (LLMs) in almost all fields of technology, processing large datasets for languagemodels poses challenges in terms of scalability and efficiency. If you like our work, you will love our newsletter.
Inflection AI has been making waves in the field of largelanguagemodels (LLMs) with their recent unveiling of Inflection-2.5, a model that competes with the world's leading LLMs, including OpenAI's GPT-4 and Google's Gemini. Inflection AI's rapid rise has been further fueled by a massive $1.3 Conclusion Inflection-2.5
To start simply, you could think of LLMOps ( LargeLanguageModel Operations) as a way to make machine learning work better in the real world over a long period of time. As previously mentioned: model training is only part of what machine learning teams deal with. What is LLMOps? Why are these elements so important?
In this post, we show you an example of a generative AI assistant application and demonstrate how to assess its security posture using the OWASP Top 10 for LargeLanguageModel Applications , as well as how to apply mitigations for common threats. Alternatively, you can choose to use a customer managed key.
With the increase in the growth of AI, largelanguagemodels (LLMs) have become increasingly popular due to their ability to interpret and generate human-like text. This observability ensures continuity in operations and provides valuable data for optimizing the deployment of LLMs in enterprise settings.
NVIDIA RTX Blackwell PRO GPUs large GPU memory can further assist with handling massive datasets and spikes in usage without sacrificing performance. Professionals can benefit from high-quality video playback, accelerate video dataingestion and use advanced AI-powered video editing features. 264 and HEVC decode.
Largelanguagemodels (LLMs) like OpenAI's GPT series have been trained on a diverse range of publicly accessible data, demonstrating remarkable capabilities in text generation, summarization, question answering, and planning. To use this setup, you'll need to have an OPENAI_API_KEY.
Largelanguagemodels (LLMs) fine-tuned on proprietary data have become a competitive differentiator for enterprises. When combined with Snorkel Flow, it becomes a powerful enabler for enterprises seeking to harness the full potential of their proprietary data.
By ingesting vast amounts of unlabeled data and using self-supervised techniques for model training, FMs have removed these bottlenecks and opened the avenue for widescale adoption of AI across the enterprise. These massive amounts of data that exist in every business are waiting to be unleashed to drive insights.
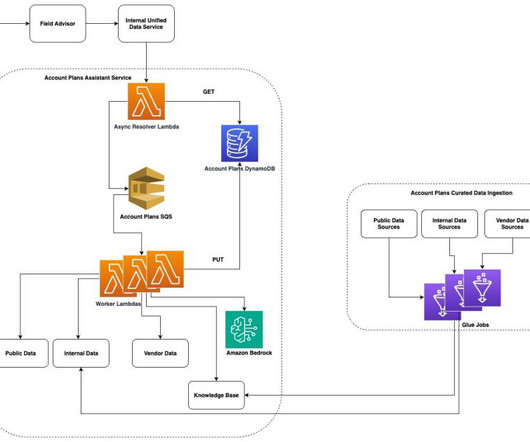
Mid-market Account Manager Amazon Q, Amazon Bedrock, and other AWS services underpin this experience, enabling us to use largelanguagemodels (LLMs) and knowledge bases (KBs) to generate relevant, data-driven content for APs. Its a game-changer for serving my full portfolio of accounts.
At Snorkel, weve partnered with Databricks to create a powerful synergy between their data lakehouse and our Snorkel Flow AI data development platform. Ingesting raw data from Databricks into Snorkel Flow Efficient dataingestion is the foundation of any machine learning project.
Both offer unique approaches to enhancing the performance and functionality of largelanguagemodels (LLMs), but they cater to the developer community’s slightly different needs and preferences. Engines: The bridge between data sources and LLMs allows seamless data access and interaction.
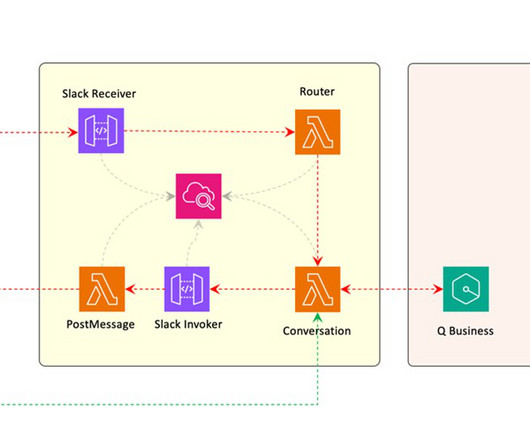
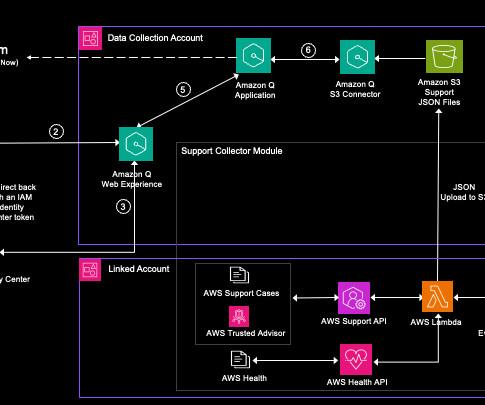
Amazon Q retrieves relevant information from its index, which is populated using data from the connected data sources (Amazon S3 and a web crawler). Amazon Q then generates a response using its internal largelanguagemodel (LLM) and presents it to the user through the Amazon Q web UI.
The book starts by explaining what it takes to be a digital maverick and how enterprises can leverage digital solutions to transform how data is utilized. A digital maverick is typically characterized by big-picture thinking, technical prowess, and the understanding that systems can be optimized through dataingestion.
Recently, pretrained languagemodels have significantly advanced text embedding models, enabling better semantic understanding for tasks (e.g., However, in industrial applications, the main bottleneck in efficient document retrieval often lies in the dataingestion pipeline rather than the embedding model’s performance.
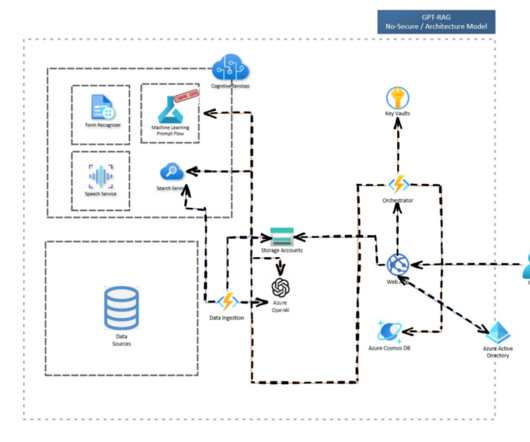
Retrieval Augmented Generation (RAG) has emerged as a leading method for using the power of largelanguagemodels (LLMs) to interact with documents in natural language. The first step is dataingestion, as shown in the following diagram. This structure can be used to optimize dataingestion.
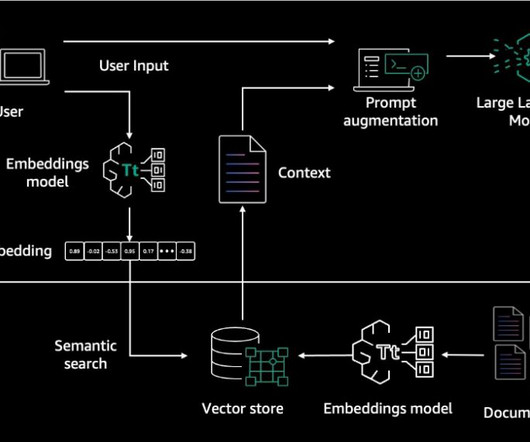
The original query is augmented with the retrieved documents, providing context for the largelanguagemodel (LLM). Using the query embedding and the metadata filter, relevant documents are retrieved from the knowledge base. The LLM generates a response based on the augmented query and retrieved context.
This solution addresses the complexities data engineering teams face by providing a unified platform for dataingestion, transformation, and orchestration. Image Source Key Components of LakeFlow: LakeFlow Connect: This component offers point-and-click dataingestion from numerous databases and enterprise applications.
This post presents a solution that uses a generative artificial intelligence (AI) to standardize air quality data from low-cost sensors in Africa, specifically addressing the air quality data integration problem of low-cost sensors. A human-in-the-loop mechanism safeguards dataingestion.
By moving our core infrastructure to Amazon Q, we no longer needed to choose a largelanguagemodel (LLM) and optimize our use of it, manage Amazon Bedrock agents, a vector database and semantic search implementation, or custom pipelines for dataingestion and management.
In simple terms, RAG is a natural language processing (NLP) approach that blends retrieval and generation models to enhance the quality of generated content. It addresses challenges faced by LargeLanguageModels (LLMs), including limited knowledge access, lack of transparency, and hallucinations in answers.
Chatbots also offer valuable data-driven insights into customer behavior while scaling effortlessly as the user base grows; therefore, they present a cost-effective solution for engaging customers. Chatbots use the advanced natural language capabilities of largelanguagemodels (LLMs) to respond to customer questions.
A tech deep-dive to build the ultimate hiring platform using largelanguagemodels & vector databases Photo by Cytonn Photography on Unsplash “Do you know what’s harder than finding a needle in a haystack? DataIngestion and Storage Resumes and job descriptions are collected from users and employers, respectively.
In the evolving landscape of artificial intelligence, languagemodels are becoming increasingly integral to a variety of applications, from customer service to real-time data analysis. One key challenge, however, remains: preparing documents for ingestion into largelanguagemodels (LLMs).
Generative AI architecture components Before diving deeper into the common operating model patterns, this section provides a brief overview of a few components and AWS services used in the featured architectures. LLMs may hallucinate, which means a model can provide a confident but factually incorrect response.
This e-book focuses on adapting largelanguagemodels (LLMs) to specific use cases by leveraging Prompt Engineering, Fine-Tuning, and Retrieval Augmented Generation (RAG), tailored for readers with an intermediate knowledge of Python.
They also plan on incorporating offline LLMs as they can process sensitive or confidential information without the need to transmit data over the internet. This will reduce the risk of data breaches and unauthorized access. Check out the GitHub and Documentation.
Introduction LargeLanguageModels (LLMs) have opened up a new world of possibilities, powering everything from advanced chatbots to autonomous AI agents. However, to unlock their full potential, you often need robust frameworks that handle dataingestion, prompt engineering, memory storage, and tool usage.
Manage data through standard methods of dataingestion and use Enriching LLMs with new data is imperative for LLMs to provide more contextual answers without the need for extensive fine-tuning or the overhead of building a specific corporate LLM.
Effectively manage your data and its lifecycle Data plays a key role throughout your IDP solution. Starting with the initial dataingestion, data is pushed through various stages of processing, and finally returned as output to end-users. Amazon Textract requires at least 150 DPI.
The teams built a new dataingestion mechanism, allowing the CTR files to be jointly delivered with the audio file to an S3 bucket. In the future, Principal plans to continue expanding postprocessing capabilities with additional data aggregation, analytics, and natural language generation (NLG) models for text summarization.
The Hugging Face containers host a largelanguagemodel (LLM) from the Hugging Face Hub. The service allows for simple audio dataingestion, easy-to-read transcript creation, and accuracy improvement through custom vocabularies. Amazon Transcribe’s new ASR foundation model supports 100+ language variants.
Largelanguagemodels (LLMs) fine-tuned on proprietary data have become a competitive differentiator for enterprises. When combined with Snorkel Flow, it becomes a powerful enabler for enterprises seeking to harness the full potential of their proprietary data.
Largelanguagemodels (LLMs) are revolutionizing fields like search engines, natural language processing (NLP), healthcare, robotics, and code generation. For ingestion, data can be updated in an offline mode, whereas inference needs to happen in milliseconds.
You follow the same process of dataingestion, training, and creating a batch inference job as in the previous use case. Announcing LangChain integration to seamlessly integrate Amazon Personalize with the LangChain framework LangChain is a powerful open-source framework that allows for integration with largelanguagemodels (LLMs).
As one of the most rapidly developing fields in AI, the capabilities for and applications of LargeLanguageModels (LLMs) are changing and growing continuously. It can be hard to keep on top of all the advancements. At ODSC West this October 29th-31st, you’ll find a wide range of workshops, tutorials, and talks on LLMs and RAG.
At Snorkel, weve partnered with Databricks to create a powerful synergy between their data lakehouse and our Snorkel Flow AI data development platform. Ingesting raw data from Databricks into Snorkel Flow Efficient dataingestion is the foundation of any machine learning project.
Understanding the MLOps Lifecycle The MLOps lifecycle consists of several critical stages, each with its unique challenges: DataIngestion: Collecting data from various sources and ensuring it’s available for analysis. Data Preparation: Cleaning and transforming raw data to make it usable for machine learning.
Unlocking accurate and insightful answers from vast amounts of text is an exciting capability enabled by largelanguagemodels (LLMs). When building LLM applications, it is often necessary to connect and query external data sources to provide relevant context to the model.
Topics Include: Agentic AI DesignPatterns LLMs & RAG forAgents Agent Architectures &Chaining Evaluating AI Agent Performance Building with LangChain and LlamaIndex Real-World Applications of Autonomous Agents Who Should Attend: Data Scientists, Developers, AI Architects, and ML Engineers seeking to build cutting-edge autonomous systems.
Amazon Q Business is a fully managed, secure, generative-AI powered enterprise chat assistant that enables natural language interactions with your organization’s data. By default, Amazon Q Business will only produce responses using the data you’re indexing. This behavior is aligned with the use cases related to our solution.
Finally, I will outline ongoing work and future directions, including improving dataingestion, enhancing model transparency, and refining the contextual application of AI within functional medicine.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content