This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
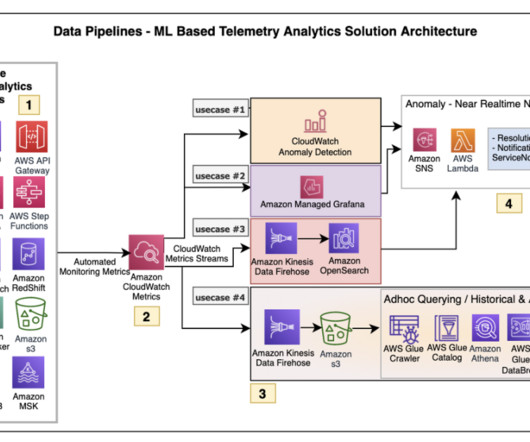
Amazon Q Business , a new generative AI-powered assistant, can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in an enterprises systems. Large-scale dataingestion is crucial for applications such as document analysis, summarization, research, and knowledge management.
This comprehensive security setup addresses LLM10:2025 Unbound Consumption and LLM02:2025 Sensitive Information Disclosure, making sure that applications remain both resilient and secure. In the physical architecture diagram, the application controller is the LLM orchestrator AWS Lambda function.
If you think about building a data pipeline, whether you’re doing a simple BI project or a complex AI or machine learning project, you’ve got dataingestion, data storage and processing, and data insight – and underneath all of those four stages, there’s a variety of different technologies being used,” explains Faruqui.
Amazon SageMaker Feature Store provides an end-to-end solution to automate feature engineering for machine learning (ML). For many ML use cases, raw data like log files, sensor readings, or transaction records need to be transformed into meaningful features that are optimized for model training. SageMaker Studio set up.
Amazon Bedrock Knowledge Bases gives foundation models (FMs) and agents contextual information from your company’s private data sources for Retrieval Augmented Generation (RAG) to deliver more relevant, accurate, and customized responses. The outbound message handler retrieves the relevant chat contact information from Amazon DynamoDB.
Thats why we use advanced technology and data analytics to streamline every step of the homeownership experience, from application to closing. Data exploration and model development were conducted using well-known machine learning (ML) tools such as Jupyter or Apache Zeppelin notebooks.
Quantum provides end-to-end data solutions that help organizations manage, enrich, and protect unstructured data, such as video and audio files, at scale. Their technology focuses on transforming data into valuable insights, enabling businesses to extract value and make informed decisions.
This multi-interface, RAG-powered approach not only strives to meet the flexibility demands of modern users, but also fosters a more informed and engaged user base, ultimately maximizing the assistants effectiveness and reach. Its versatility extends beyond team messaging to serve as an effective interface for assistants.
Deltek serves over 30,000 clients with industry-specific software and information solutions. Deltek is continuously working on enhancing this solution to better align it with their specific requirements, such as supporting file formats beyond PDF and implementing more cost-effective approaches for their dataingestion pipeline.
Through evaluations of sensors and informed decision-making support, Afri-SET empowers governments and civil society for effective air quality management. This manual synchronization process, hindered by disparate data formats, is resource-intensive, limiting the potential for widespread data orchestration.
FM-powered artificial intelligence (AI) assistants have limitations, such as providing outdated information or struggling with context outside their training data. It provides this context to the FM, which uses it to generate a more informed and precise response. Businesses incur charges for data storage and management.
In this post, we discuss how the IEO developed UNDP’s artificial intelligence and machine learning (ML) platform—named Artificial Intelligence for Development Analytics (AIDA)— in collaboration with AWS, UNDP’s Information and Technology Management Team (UNDP ITM), and the United Nations International Computing Centre (UNICC).
Amazon Q Business is a generative AI-powered assistant that can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in your enterprise systems. It empowers employees to be more creative, data-driven, efficient, prepared, and productive.
In BI systems, data warehousing first converts disparate raw data into clean, organized, and integrated data, which is then used to extract actionable insights to facilitate analysis, reporting, and data-informed decision-making. The following elements serve as a backbone for a functional data warehouse.
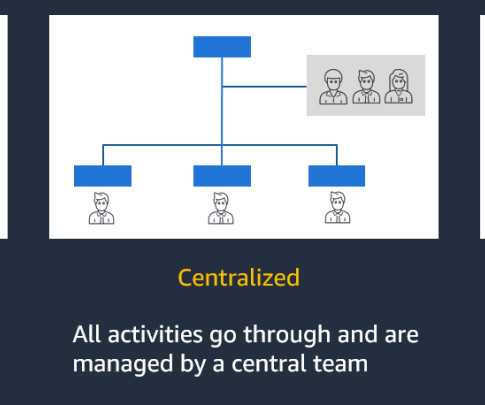
However, even in a decentralized model, often LOBs must align with central governance controls and obtain approvals from the CCoE team for production deployment, adhering to global enterprise standards for areas such as access policies, model risk management, data privacy, and compliance posture, which can introduce governance complexities.
They also plan on incorporating offline LLMs as they can process sensitive or confidential information without the need to transmit data over the internet. This will reduce the risk of data breaches and unauthorized access. Check out the GitHub and Documentation. If you like our work, you will love our newsletter.
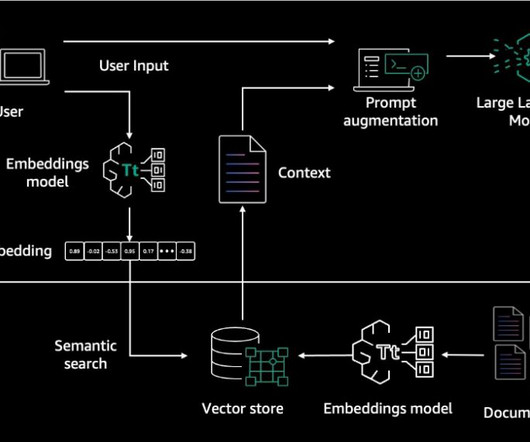
One way to enable more contextual conversations is by linking the chatbot to internal knowledge bases and information systems. Integrating proprietary enterprise data from internal knowledge bases enables chatbots to contextualize their responses to each user’s individual needs and interests.
This approach, when applied to generative AI solutions, means that a specific AI or machine learning (ML) platform configuration can be used to holistically address the operational excellence challenges across the enterprise, allowing the developers of the generative AI solution to focus on business value.
With such high-value data, much of which holds highly sensitive financial and personal information, the mainframe is a potential target for cyber criminals. Many consider a NoSQL database essential for high dataingestion rates. trillion instructions per day.
RAG models retrieve relevant information from a large corpus of text and then use a generative language model to synthesize an answer based on the retrieved information. Choose Sync to initiate the dataingestion job. After the dataingestion job is complete, choose the desired FM to use for retrieval and generation.
RAG models first retrieve relevant information from a large corpus of text and then use a FM to synthesize an answer based on the retrieved information. Choose Sync to initiate the dataingestion job. On the Amazon Bedrock console, navigate to the created knowledge base.
The service allows for simple audio dataingestion, easy-to-read transcript creation, and accuracy improvement through custom vocabularies. Hugging Face is an open-source machine learning (ML) platform that provides tools and resources for the development of AI projects.
This post, part of the Governing the ML lifecycle at scale series ( Part 1 , Part 2 , Part 3 ), explains how to set up and govern a multi-account ML platform that addresses these challenges. An enterprise might have the following roles involved in the ML lifecycles. This ML platform provides several key benefits.
Content redaction: Each customer audio interaction is recorded as a stereo WAV file, but could potentially include sensitive information such as HIPAA-protected and personally identifiable information (PII). Scalability: This architecture needed to immediately scale to thousands of calls per day and millions of calls per year.
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machine learning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications.
Amazon DataZone makes it straightforward for engineers, data scientists, product managers, analysts, and business users to access data throughout an organization so they can discover, use, and collaborate to derive data-driven insights.
Many existing LLMs require specific formats and well-structured data to function effectively. Parsing and transforming different types of documents—ranging from PDFs to Word files—for machine learning tasks can be tedious, often leading to information loss or requiring extensive manual intervention. Unstructured with Check Table 0.77
The personalization of LLM applications can be achieved by incorporating up-to-date user information, which typically involves integrating several components. One such component is a feature store, a tool that stores, shares, and manages features for machine learning (ML) models.
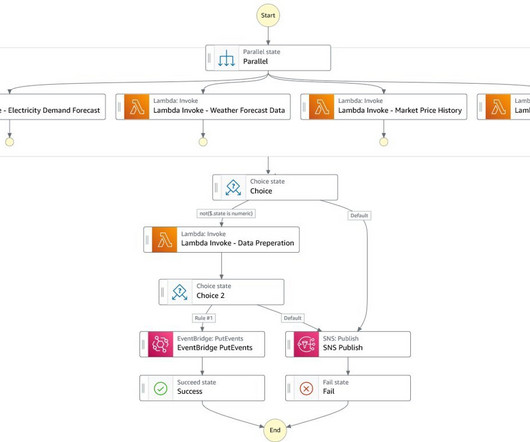
By exploring these challenges, organizations can recognize the importance of real-time forecasting and explore innovative solutions to overcome these hurdles, enabling them to stay competitive, make informed decisions, and thrive in today’s fast-paced business environment. For more information, refer to the following resources.
AWS provides various services catered to time series data that are low code/no code, which both machine learning (ML) and non-ML practitioners can use for building ML solutions. We recommend running this notebook on Amazon SageMaker Studio , a web-based, integrated development environment (IDE) for ML.
You can use machine learning (ML) to generate these insights and build predictive models. Educators can also use ML to identify challenges in learning outcomes, increase success and retention among students, and broaden the reach and impact of online learning content. Download the following student dataset to your local computer.
I highly recommend anyone coming from a Machine Learning or Deep Learning modeling background who wants to learn about deploying models (MLOps) on a cloud platform to take this exam or an equivalent; the exam also includes topics on SQL dataingestion with Azure and Databricks, which is also a very important skill to have in Data Science.
MPII is using a machine learning (ML) bid optimization engine to inform upstream decision-making processes in power asset management and trading. This solution helps market analysts design and perform data-driven bidding strategies optimized for power asset profitability. Data comes from disparate sources in a number of formats.
At the higher levels of automation (Level 2 and above), the AD system performs multiple functions: Data collection – The AV system gathers information about the vehicle’s surroundings in real time with centimeter accuracy. AV systems fuse data from the devices that are integrated together to build a comprehensive perception.
The IDP Well-Architected Custom Lens follows the AWS Well-Architected Framework, reviewing the solution with six pillars with the granularity of a specific AI or machine learning (ML) use case, and providing the guidance to tackle common challenges. Additionally, the solution must handle high data volumes with low latency and high throughput.
This combination of great models and continuous adaptation is what will lead to a successful machine learning (ML) strategy. It helps you extract information by recognizing sentiments, key phrases, entities, and much more, allowing you to take advantage of state-of-the-art models and adapt them for your specific use case.
When machine learning (ML) models are deployed into production and employed to drive business decisions, the challenge often lies in the operation and management of multiple models. That is where Provectus , an AWS Premier Consulting Partner with competencies in Machine Learning, Data & Analytics, and DevOps, stepped in.
Machine learning (ML) is becoming increasingly complex as customers try to solve more and more challenging problems. This complexity often leads to the need for distributed ML, where multiple machines are used to train a single model. SageMaker is a fully managed service for building, training, and deploying ML models.
Effectively manage your data and its lifecycle Data plays a key role throughout your IDP solution. Starting with the initial dataingestion, data is pushed through various stages of processing, and finally returned as output to end-users. He is passionate about automotive, AI/ML and developer productivity.
We downloaded the data from AWS Data Exchange and processed it in AWS Glue to generate KG files. In Part 2 , we demonstrated how to use Amazon Neptune ML (in Amazon SageMaker ) to train the KG and create KG embeddings. The KG files were stored in Amazon Simple Storage Service (Amazon S3) and then loaded in Amazon Neptune.
In this post, we discuss a machine learning (ML) solution for complex image searches using Amazon Kendra and Amazon Rekognition. Amazon Kendra is an intelligent search service powered by ML, and Amazon Rekognition is an ML service that can identify objects, people, text, scenes, and activities from images or videos.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
Simple methods for time series forecasting use historical values of the same variable whose future values need to be predicted, whereas more complex, machine learning (ML)-based methods use additional information, such as the time series data of related variables. For more information, refer to Training Predictors.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content