This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
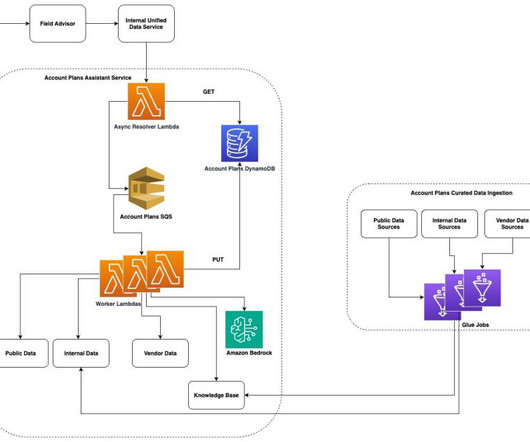
Amazon Bedrock Knowledge Bases offers fully managed, end-to-end Retrieval Augmented Generation (RAG) workflows to create highly accurate, low-latency, secure, and custom generative AI applications by incorporating contextual information from your companys data sources.
In the generative AI or traditional AI development cycle, dataingestion serves as the entry point. Here, raw data that is tailored to a company’s requirements can be gathered, preprocessed, masked and transformed into a format suitable for LLMs or other models. One potential solution is to use remote runtime options like.
Amazon Q Business , a new generative AI-powered assistant, can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in an enterprises systems. Large-scale dataingestion is crucial for applications such as document analysis, summarization, research, and knowledge management.
At its core, keyword search provides the essential baseline functionality of accurately matching user queries to product data and metadata, making sure explicit product names, brands, or attributes can be reliably retrieved. This solution has two key workflows: a dataingestion workflow and a query workflow.
Retrieval Augmented Generation (RAG) applications have become increasingly popular due to their ability to enhance generative AI tasks with contextually relevant information. Implementing RAG-based applications requires careful attention to security, particularly when handling sensitive data.
Data synthesis: The assistant can pull relevant information from multiple sources including from our customer relationship management (CRM) system, financial reports, news articles, and previous APs to provide a holistic view of our customers.
This comprehensive security setup addresses LLM10:2025 Unbound Consumption and LLM02:2025 Sensitive Information Disclosure, making sure that applications remain both resilient and secure. In the physical architecture diagram, the application controller is the LLM orchestrator AWS Lambda function.
There is also the challenge of privacy and data security, as the information provided in the prompt could potentially be sensitive or confidential. On the other hand, a Node is a snippet or “chunk” from a Document, enriched with metadata and relationships to other nodes, ensuring a robust foundation for precise data retrieval later on.
Deltek serves over 30,000 clients with industry-specific software and information solutions. Deltek is continuously working on enhancing this solution to better align it with their specific requirements, such as supporting file formats beyond PDF and implementing more cost-effective approaches for their dataingestion pipeline.
In BI systems, data warehousing first converts disparate raw data into clean, organized, and integrated data, which is then used to extract actionable insights to facilitate analysis, reporting, and data-informed decision-making. The following elements serve as a backbone for a functional data warehouse.
This multi-interface, RAG-powered approach not only strives to meet the flexibility demands of modern users, but also fosters a more informed and engaged user base, ultimately maximizing the assistants effectiveness and reach. Its versatility extends beyond team messaging to serve as an effective interface for assistants.
With Knowledge Bases for Amazon Bedrock, you can securely connect foundation models (FMs) in Amazon Bedrock to your company data for fully managed Retrieval Augmented Generation (RAG). It provides this context to the FM, which uses it to generate a more informed and precise response. What is Retrieval Augmented Generation?
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machine learning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications.
In this post, we discuss how the IEO developed UNDP’s artificial intelligence and machine learning (ML) platform—named Artificial Intelligence for Development Analytics (AIDA)— in collaboration with AWS, UNDP’s Information and Technology Management Team (UNDP ITM), and the United Nations International Computing Centre (UNICC).
This is particularly useful for tracking access to sensitive resources such as personally identifiable information (PII), model updates, and other critical activities, enabling enterprises to maintain a robust audit trail and compliance. For more information, see Monitor Amazon Bedrock with Amazon CloudWatch.
The personalization of LLM applications can be achieved by incorporating up-to-date user information, which typically involves integrating several components. A feature store maintains user profile data. A media metadata store keeps the promotion movie list up to date.
Simple methods for time series forecasting use historical values of the same variable whose future values need to be predicted, whereas more complex, machine learning (ML)-based methods use additional information, such as the time series data of related variables. For more information, refer to Training Predictors.
Identifying keywords such as use cases and industry verticals in these sources also allows the information to be captured and for more relevant search results to be displayed to the user. Lastly, we cover the dataingestion by an intelligent search service, powered by ML.
Content redaction: Each customer audio interaction is recorded as a stereo WAV file, but could potentially include sensitive information such as HIPAA-protected and personally identifiable information (PII). Scalability: This architecture needed to immediately scale to thousands of calls per day and millions of calls per year.
The dataset is a collection of 147,702 product listings with multilingual metadata and 398,212 unique catalogue images. There are 16 files that include product description and metadata of Amazon products in the format of listings/metadata/listings_.json.gz. We use the first metadata file in this demo. unsqueeze(0).to(device)
Amazon Bedrock Knowledge Bases provides foundation models (FMs) and agents in Amazon Bedrock contextual information from your company’s private data sources for Retrieval Augmented Generation (RAG) to deliver more relevant, accurate, and customized responses. In the Choose data source section, select SharePoint. Choose Next.
In this post, we illustrate how to handle OOC by utilizing the power of the IMDb dataset (the premier source of global entertainment metadata) and knowledge graphs. Creates a Lambda function to process and load movie metadata and embeddings to OpenSearch Service indexes ( **-ReadFromOpenSearchLambda-** ).
Core features of end-to-end MLOps platforms End-to-end MLOps platforms combine a wide range of essential capabilities and tools, which should include: Data management and preprocessing : Provide capabilities for dataingestion, storage, and preprocessing, allowing you to efficiently manage and prepare data for training and evaluation.
Adding more clusters decreases the inertia value, but it also decreases the information contained in each cluster. Refer to the Amazon Forecast Developer Guide for information about dataingestion , predictor training , and generating forecasts. In the following code snippet, we determine the optimal number of clusters.
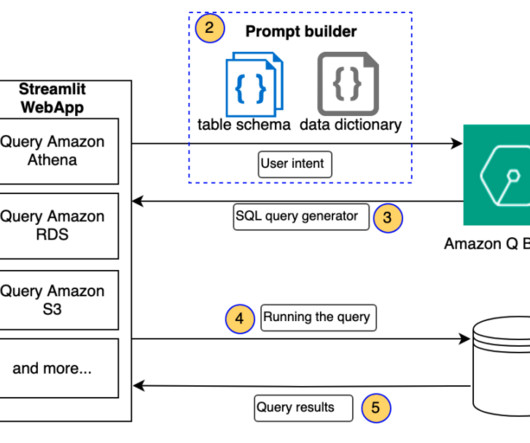
In this post, we discuss an architecture to query structured data using Amazon Q Business, and build out an application to query cost and usage data in Amazon Athena with Amazon Q Business. You can extend this architecture to use additional data sources, query validation, and prompting techniques to cover a wider range of use cases.
This talk will explore a new capability that transforms diverse clinical data (EHR, FHIR, notes, and PDFs) into a unified patient timeline, enabling natural language question answering.
Tackling these challenges is key to effectively connecting readers with content they find informative and engaging. In this solution, you can also ingest certain items and interactions data attributes into Amazon DynamoDB. For example, article metadata may contain company and industry names in the article.
Summary: Apache NiFi is a powerful open-source dataingestion platform design to automate data flow management between systems. Its architecture includes FlowFiles, repositories, and processors, enabling efficient data processing and transformation. FlowFile At the core of NiFi’s architecture is the FlowFile.
As the data scientist, complete the following steps: In the Environments section of the Banking-Consumer-ML project, choose SageMaker Studio. On the Asset catalog tab, search for and choose the data asset Bank. You can view the metadata and schema of the banking dataset to understand the data attributes and columns.
The ML components for dataingestion, preprocessing, and model training were available as disjointed Python scripts and notebooks, which required a lot of manual heavy lifting on the part of engineers. It also persists a manifest file to Amazon S3, including all necessary information to recreate that dataset version.
A feature store typically comprises a feature repository, a feature serving layer, and a metadata store. It can also transform incoming data on the fly. The metadata store manages the metadata associated with each feature, such as its origin and transformations. What are the components of a feature store?
These work together to enable efficient data processing and analysis: · Hive Metastore It is a central repository that stores metadata about Hive’s tables, partitions, and schemas. It applies the data structure during querying rather than dataingestion. Thus, it helps in informed decision-making.
Today, companies are facing a continual need to store tremendous volumes of data. The demand for information repositories enabling business intelligence and analytics is growing exponentially, giving birth to cloud solutions. The tool’s high storage capacity is perfect for keeping large information volumes.
It provides insights into considerations for choosing the right tool, ensuring businesses can optimize their data integration processes for better analytics and decision-making. Introduction In todays data-driven world, organizations are overwhelmed with vast amounts of information.
Data Processes and Organizational Structure Data Governance access controls enable the end-users to see how data processing works inside an organization. It can include data refresh cadences, PII limitations, regulatory data regulations, or even data access. It ensures the safe storage of data.
Hence, the quality of data is significant here. Quality data fuels business decisions, informs scientific research, drives technological innovations, and shapes our understanding of the world. The Relevance of Data Quality Data quality refers to the accuracy, completeness, consistency, and reliability of data.
The image below shows an example of DAG; the graph is directed, information flows from A throughout the graph, and it is acyclic since the info from A doesn't get back to A. To understand this, imagine you have a pipeline that extracts weather information from an API, cleans the weather information, and loads it into a database.
To make that possible, your data scientists would need to store enough details about the environment the model was created in and the related metadata so that the model could be recreated with the same or similar outcomes. Your ML platform must have versioning in-built because code and data mostly make up the ML system.
Data contains information, and information can be used to predict future behaviors, from the buying habits of customers to securities returns. The financial services industry (FSI) is no exception to this, and is a well-established producer and consumer of data and analytics. 32xlarge 0 16 0 128 512 512 4 x 1.9
While there are many similarities with MLOps, LLMOps is unique because it requires specialized handling of natural-language data, prompt-response management, and complex ethical considerations. Retrieval Augmented Generation (RAG) enables LLMs to extract and synthesize information like an advanced search engine.
The components comprise implementations of the manual workflow process you engage in for automatable steps, including: Dataingestion (extraction and versioning). Data validation (writing tests to check for data quality). Data preprocessing. Let’s briefly go over each of the components below. CSV, Parquet, etc.)
This approach not only enhances efficiency, but also provides valuable insights that can help automotive businesses make more informed decisions. This metadata includes details such as make, model, year, area of the damage, severity of the damage, parts replacement cost, and labor required to repair.
As enterprises adopt generative AI, many are developing intelligent assistants powered by Retrieval Augmented Generation (RAG) to take advantage of information and knowledge from their enterprise data repositories. These diverse data sources come with their own ways of encapsulating entities of information.
An LLM-powered agent, which is responsible for orchestrating steps to respond to the request, checks if additional information is needed from knowledge sources. The agent invokes the process to retrieve information from the knowledge source. The relevant information (enhanced context) from the knowledge source is returned to the agent.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content