This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
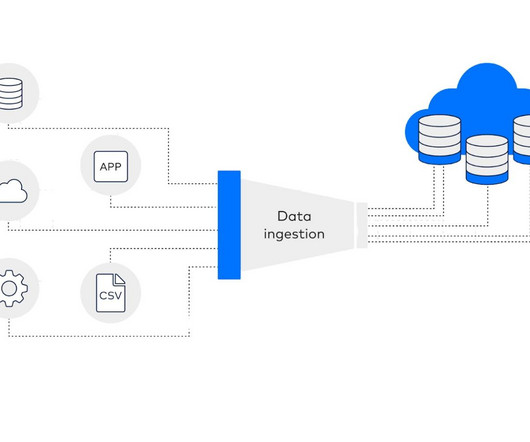
In the generative AI or traditional AI development cycle, dataingestion serves as the entry point. Here, raw data that is tailored to a company’s requirements can be gathered, preprocessed, masked and transformed into a format suitable for LLMs or other models. One potential solution is to use remote runtime options like.
On the other hand, AI-powered CRMs are faster and provide actionable insights based on real-time data. The collected data is more accurate, which leads to better customer information. On the operations front, it enables data democratization and ensures data governance.
How Prescriptive AI Transforms Data into Actionable Strategies Prescriptive AI goes beyond simply analyzing data; it recommends actions based on that data. While descriptive AI looks at past information and predictive AI forecasts what might happen, prescriptive AI takes it further.
Amazon Q Business , a new generative AI-powered assistant, can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in an enterprises systems. Large-scale dataingestion is crucial for applications such as document analysis, summarization, research, and knowledge management.
Moreover, data is often an afterthought in the design and deployment of gen AI solutions, leading to inefficiencies and inconsistencies. Unlocking the full potential of enterprise data for generative AI At IBM, we have developed an approach to solving these data challenges.
Designed to track and react to data changes as they happen, Drasi operates continuously. Unlike batch-processing systems, it does not wait for intervals to process information. Understanding Drasi Drasi is an advanced event-driven architecture powered by Artificial Intelligence (AI) and designed to handle real-time data changes.
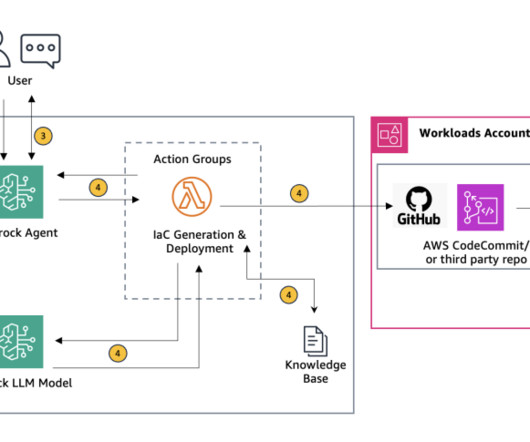
This comprehensive security setup addresses LLM10:2025 Unbound Consumption and LLM02:2025 Sensitive Information Disclosure, making sure that applications remain both resilient and secure. In the physical architecture diagram, the application controller is the LLM orchestrator AWS Lambda function.
Summary: Dataingestion is the process of collecting, importing, and processing data from diverse sources into a centralised system for analysis. This crucial step enhances data quality, enables real-time insights, and supports informed decision-making. This is where dataingestion comes in.
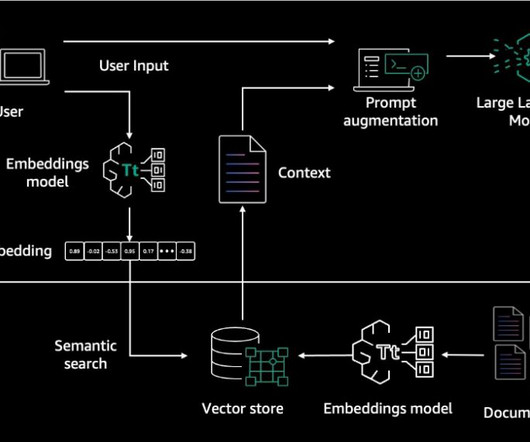
Amazon Bedrock Knowledge Bases offers fully managed, end-to-end Retrieval Augmented Generation (RAG) workflows to create highly accurate, low-latency, secure, and custom generative AI applications by incorporating contextual information from your companys data sources. Finally, the generated response is sent back to the user.
What is Real-Time DataIngestion? Real-time dataingestion is the practise of gathering and analysing information as it is produced, without little to no lag between the emergence of the data and its accessibility for analysis. Traders need up-to-the-second information to make informed decisions.
Companies are presented with significant opportunities to innovate and address the challenges associated with handling and processing the large volumes of data generated by AI. Organizations generate and collect large amounts of information from various sources such as social media, customer interactions, IoT sensors and enterprise systems.
Amazon Bedrock Knowledge Bases gives foundation models (FMs) and agents contextual information from your company’s private data sources for Retrieval Augmented Generation (RAG) to deliver more relevant, accurate, and customized responses. The outbound message handler retrieves the relevant chat contact information from Amazon DynamoDB.
If you think about building a data pipeline, whether you’re doing a simple BI project or a complex AI or machine learning project, you’ve got dataingestion, data storage and processing, and data insight – and underneath all of those four stages, there’s a variety of different technologies being used,” explains Faruqui.
There is also the challenge of privacy and data security, as the information provided in the prompt could potentially be sensitive or confidential. On the other hand, a Node is a snippet or “chunk” from a Document, enriched with metadata and relationships to other nodes, ensuring a robust foundation for precise data retrieval later on.
The list of challenges is long: cloud attack surface sprawl, complex application environments, information overload from disparate tools, noise from false positives and low-risk events, just to name a few. Explore QRadar Log Insights To learn more, visit the QRadar Log Insights page for information on the QRadar suite of security products.
Deltek serves over 30,000 clients with industry-specific software and information solutions. Deltek is continuously working on enhancing this solution to better align it with their specific requirements, such as supporting file formats beyond PDF and implementing more cost-effective approaches for their dataingestion pipeline.
LLaMA, Chinchilla, and PaLM-540B on a wide range of benchmarks commonly used for comparing LLMs, Inflection-1 enables users to interact with Pi, Inflection AI's personal AI, in a simple and natural way, receiving fast, relevant, and helpful information and advice. Outperforming industry giants such as GPT-3.5, The post Inflection-2.5:
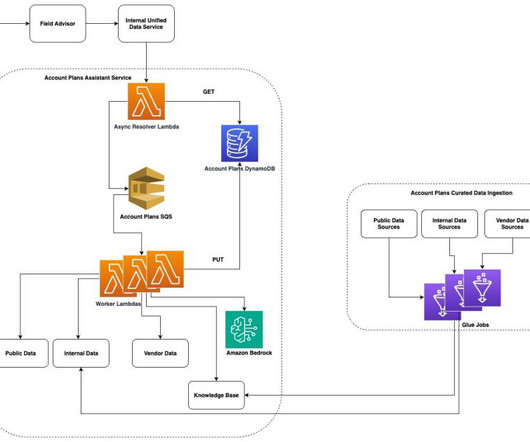
Data synthesis: The assistant can pull relevant information from multiple sources including from our customer relationship management (CRM) system, financial reports, news articles, and previous APs to provide a holistic view of our customers.
FM-powered artificial intelligence (AI) assistants have limitations, such as providing outdated information or struggling with context outside their training data. It provides this context to the FM, which uses it to generate a more informed and precise response. Businesses incur charges for data storage and management.
Heres a sampling of what some of our more active users had to say about their experience with Field Advisor: I use Field Advisor to review executive briefing documents, summarize meetings and outline actions, as well analyze dense information into key points with prompts. Field Advisor continues to enable me to work smarter, not harder.
Thats why we use advanced technology and data analytics to streamline every step of the homeownership experience, from application to closing. Rockets legacy data science architecture is shown in the following diagram. Data Storage and Processing: All compute is done as Spark jobs inside of a Hadoop cluster using Apache Livy and Spark.
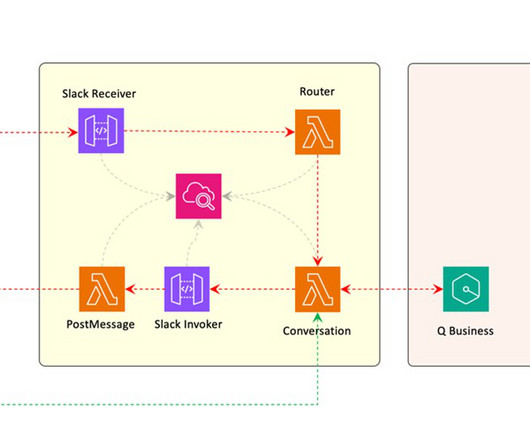
This multi-interface, RAG-powered approach not only strives to meet the flexibility demands of modern users, but also fosters a more informed and engaged user base, ultimately maximizing the assistants effectiveness and reach. Its versatility extends beyond team messaging to serve as an effective interface for assistants.
Figures present another challenge captions might be separated from their images, and important visual information gets lost in translation. Traditional systems frequently misinterpret these elements, turning a simple equation into gibberish or losing critical technical information. Interpret visual scenes to answer questions.
Lesson 1: Use a data model built for public health. US public health agencies would benefit from choosing disease surveillance solutions that come with a proven, public health data model that offers relevant terminology, relationships and models. It is crucial to establish data sharing agreements in advance of an emergency.
At Snorkel, weve partnered with Databricks to create a powerful synergy between their data lakehouse and our Snorkel Flow AI data development platform. Ingesting raw data from Databricks into Snorkel Flow Efficient dataingestion is the foundation of any machine learning project. Sign up here!
Quantum provides end-to-end data solutions that help organizations manage, enrich, and protect unstructured data, such as video and audio files, at scale. Their technology focuses on transforming data into valuable insights, enabling businesses to extract value and make informed decisions.
Amazon Q Business is a generative AI-powered assistant that can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in your enterprise systems. It empowers employees to be more creative, data-driven, efficient, prepared, and productive.
One way to enable more contextual conversations is by linking the chatbot to internal knowledge bases and information systems. Integrating proprietary enterprise data from internal knowledge bases enables chatbots to contextualize their responses to each user’s individual needs and interests.
Through evaluations of sensors and informed decision-making support, Afri-SET empowers governments and civil society for effective air quality management. This manual synchronization process, hindered by disparate data formats, is resource-intensive, limiting the potential for widespread data orchestration.
RAG systems operate by first retrieving information from external knowledge sources using a retrieval model, and then using this information to prompt LLMs to generate responses. In multi-hop retrieval, the system gathers information across multiple steps or “hops” to answer complex questions or gather detailed information.
After being configured, an agent builds the prompt and augments it with your company-specific information to provide responses back to the user in natural language. During the IaC generation process, Amazon Bedrock agents actively probe for additional information by analyzing the provided diagrams and querying the user to fill any gaps.
In the era of information, data analysis is one of the most powerful tools for any business providing them with insights about market trends, customer behavior, and operational inefficiencies. GWalkR builds upon R’s robust data manipulation and visualization capabilities but presents them in a user-friendly format.
In BI systems, data warehousing first converts disparate raw data into clean, organized, and integrated data, which is then used to extract actionable insights to facilitate analysis, reporting, and data-informed decision-making. The following elements serve as a backbone for a functional data warehouse.
RAG systems operate by first retrieving information from external knowledge sources using a retrieval model, and then using this information to prompt LLMs to generate responses. In multi-hop retrieval, the system gathers information across multiple steps or “hops” to answer complex questions or gather detailed information.
Data flow Here is an example of this data flow for an Agent Creator pipeline that involves dataingestion, preprocessing, and vectorization using Chunker and Embedding Snaps. This data was then integrated into Salesforce as a real-time feed of market insights.
They also plan on incorporating offline LLMs as they can process sensitive or confidential information without the need to transmit data over the internet. This will reduce the risk of data breaches and unauthorized access.
RAG models retrieve relevant information from a large corpus of text and then use a generative language model to synthesize an answer based on the retrieved information. Choose Sync to initiate the dataingestion job. After the dataingestion job is complete, choose the desired FM to use for retrieval and generation.
Rather than using paper records, data is now collected and stored using digital tools. However, even digital information has to be stored somewhere. While databases were the traditional way to store large amounts of data, a new storage method has developed that can store even more significant and varied amounts of data.
With such high-value data, much of which holds highly sensitive financial and personal information, the mainframe is a potential target for cyber criminals. Many consider a NoSQL database essential for high dataingestion rates. trillion instructions per day.
One way to mitigate LLMs from giving incorrect information is by using a technique known as Retrieval Augmented Generation (RAG). RAG combines the powers of pre-trained language models with a retrieval-based approach to generate more informed and accurate responses.
Many existing LLMs require specific formats and well-structured data to function effectively. Parsing and transforming different types of documents—ranging from PDFs to Word files—for machine learning tasks can be tedious, often leading to information loss or requiring extensive manual intervention. Unstructured with Check Table 0.77
This is particularly useful for tracking access to sensitive resources such as personally identifiable information (PII), model updates, and other critical activities, enabling enterprises to maintain a robust audit trail and compliance. For more information, see Monitor Amazon Bedrock with Amazon CloudWatch.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content