This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The emergence of generativeAI prompted several prominent companies to restrict its use because of the mishandling of sensitive internal data. According to CNN, some companies imposed internal bans on generativeAI tools while they seek to better understand the technology and many have also blocked the use of internal ChatGPT.
In this new era of emerging AI technologies, we have the opportunity to build AI-powered assistants tailored to specific business requirements. Large-scale dataingestion is crucial for applications such as document analysis, summarization, research, and knowledge management.
A common use case with generativeAI that we usually see customers evaluate for a production use case is a generativeAI-powered assistant. If there are security risks that cant be clearly identified, then they cant be addressed, and that can halt the production deployment of the generativeAI application.
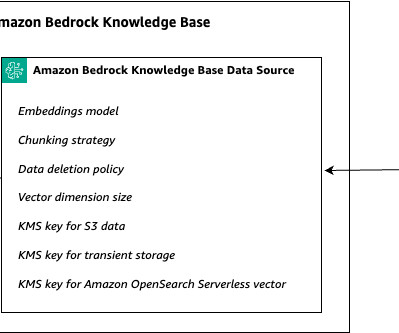
Amazon Bedrock Knowledge Bases offers fully managed, end-to-end Retrieval Augmented Generation (RAG) workflows to create highly accurate, low-latency, secure, and custom generativeAI applications by incorporating contextual information from your companys data sources.
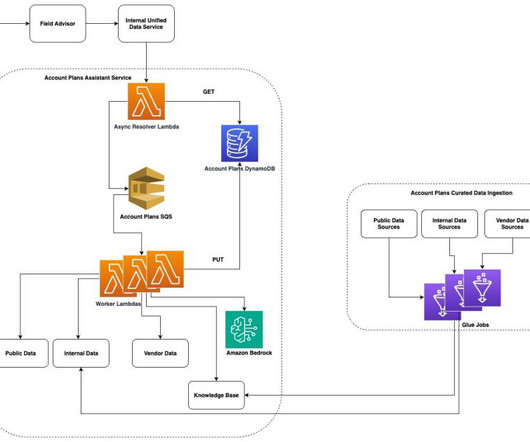
Since its launch, thousands of sales teams have used the resulting generativeAI-powered assistant to draft sections of their APs, saving time on each AP created. In this post, we showcase how the AWS Sales product team built the generativeAI account plans draft assistant.
Ahead of AI & Big Data Expo Europe , Han Heloir, EMEA gen AI senior solutions architect at MongoDB , discusses the future of AI-powered applications and the role of scalable databases in supporting generativeAI and enhancing business processes.
Today, we are excited to announce three launches that will help you enhance personalized customer experiences using Amazon Personalize and generativeAI. GenerativeAI is quickly transforming how enterprises do business. FOX Corporation (FOX) produces and distributes news, sports, and entertainment content. “We
Retrieval Augmented Generation (RAG) has emerged as a leading method for using the power of large language models (LLMs) to interact with documents in natural language. The first step is dataingestion, as shown in the following diagram. Deltek serves over 30,000 clients with industry-specific software and information solutions.
Large enterprises are building strategies to harness the power of generativeAI across their organizations. Managing bias, intellectual property, prompt safety, and data integrity are critical considerations when deploying generativeAI solutions at scale.
GenerativeAI developers can use frameworks like LangChain , which offers modules for integrating with LLMs and orchestration tools for task management and prompt engineering. A feature store maintains user profile data. A media metadata store keeps the promotion movie list up to date.
With Knowledge Bases for Amazon Bedrock, you can securely connect foundation models (FMs) in Amazon Bedrock to your company data for fully managed Retrieval Augmented Generation (RAG). You can now interact with your documents in real time without prior dataingestion or database configuration.
Amazon Kendra also supports the use of metadata for each source file, which enables both UIs to provide a link to its sources, whether it is the Spack documentation website or a CloudFront link. Furthermore, Amazon Kendra supports relevance tuning , enabling boosting certain data sources.
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machine learning (ML) services to run their daily workloads. Data is the foundational layer for all generativeAI and ML applications.
The teams built a new dataingestion mechanism, allowing the CTR files to be jointly delivered with the audio file to an S3 bucket. In the future, Principal plans to continue expanding postprocessing capabilities with additional data aggregation, analytics, and natural language generation (NLG) models for text summarization.
This talk will explore a new capability that transforms diverse clinical data (EHR, FHIR, notes, and PDFs) into a unified patient timeline, enabling natural language question answering.
In this session, you will explore the flow of Imperva’s botnet detection, including data extraction, feature selection, clustering, validation, and fine-tuning, as well as the organization’s method for measuring the results of unsupervised learning problems using a query engine.
It provides the ability to extract structured data, metadata, and other information from documents ingested from SharePoint to provide relevant search results based on the user query. For more information, see Encryption of transient data storage during dataingestion. Choose Next.
As the data scientist, complete the following steps: In the Environments section of the Banking-Consumer-ML project, choose SageMaker Studio. On the Asset catalog tab, search for and choose the data asset Bank. You can view the metadata and schema of the banking dataset to understand the data attributes and columns.
At ODSC East 2025 , were excited to present 12 curated tracks designed to equip data professionals, machine learning engineers, and AI practitioners with the tools they need to thrive in this dynamic landscape. This track will explore how AI and machine learning are accelerating breakthroughs in life sciences.
Other steps include: dataingestion, validation and preprocessing, model deployment and versioning of model artifacts, live monitoring of large language models in a production environment, monitoring the quality of deployed models and potentially retraining them. This triggers a bunch of quality checks (e.g.
In order to train transformer models on internet-scale data, huge quantities of PBAs were needed. In November 2022, ChatGPT was released, a large language model (LLM) that used the transformer architecture, and is widely credited with starting the current generativeAI boom. 32xlarge 0 16 0 128 512 512 4 x 1.9
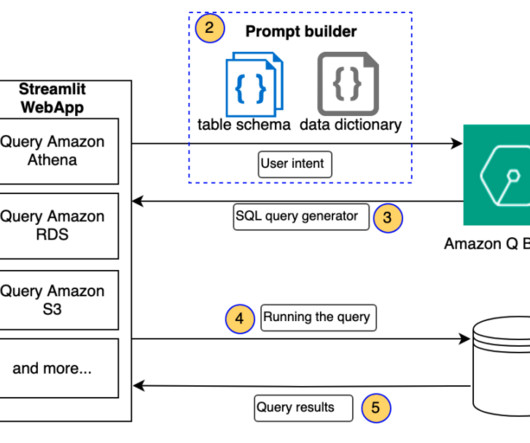
In this post, we discuss an architecture to query structured data using Amazon Q Business, and build out an application to query cost and usage data in Amazon Athena with Amazon Q Business. You can extend this architecture to use additional data sources, query validation, and prompting techniques to cover a wider range of use cases.
However, manual inspection and damage detection can be a time-consuming and error-prone process, especially when dealing with large volumes of vehicle data, the complexity of assessing vehicle damage, and the potential for human error in the assessment. We need to initially invoke this flow to load all the historic data into OpenSearch.
AWS customers use Amazon Kendra with large language models (LLMs) to quickly create secure, generativeAI –powered conversational experiences on top of your enterprise content. This approach combines a retriever with an LLM to generate responses. A retriever is responsible for finding relevant documents based on the user query.
Customers across all industries are experimenting with generativeAI to accelerate and improve business outcomes. They contribute to the effectiveness and feasibility of generativeAI applications across various domains.
With the advent of foundation models (FMs) and their remarkable natural language processing capabilities, a new opportunity has emerged to unlock the value of their data assets. Retrieval Augmented Generation (RAG) has emerged as a simple yet effective approach to achieve a desired level of specialization.
Users such as database administrators, data analysts, and application developers need to be able to query and analyze data to optimize performance and validate the success of their applications. GenerativeAI provides the ability to take relevant information from a data source and deliver well-constructed answers back to the user.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content