This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
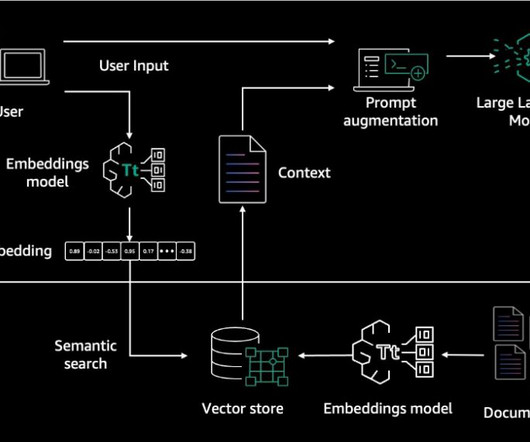
Integrating proprietary enterprise data from internal knowledge bases enables chatbots to contextualize their responses to each user’s individual needs and interests. RAG architecture involves two key workflows: data preprocessing through ingestion, and text generation using enhanced context.
TLDR; In this article, we will explain multi-hop retrieval and how it can be leveraged to build RAG systems that require complex reasoning We will showcase the technique by building a Q&A chatbot in the healthcare domain using Indexify, OpenAI, and DSPy. HR Industry: Finding perfect candidates for a job by matching certain filters.
TLDR; In this article, we will explain multi-hop retrieval and how it can be leveraged to build RAG systems that require complex reasoning We will showcase the technique by building a Q&A chatbot in the healthcare domain using Indexify, OpenAI, and DSPy. HR Industry: Finding perfect candidates for a job by matching certain filters.
We explore how to extract characteristics, also called features , from time series data using the TSFresh library —a Python package for computing a large number of time series characteristics—and perform clustering using the K-Means algorithm implemented in the scikit-learn library. to avoid overfitting.
Python = Powerful AI Research Agent By Gao Dalie () This article details building a powerful AI research agent using Pydantic AI, a web scraper (Tavily), and Llama 3.3. It emphasizes the role of LLamaindex in building RAG systems, managing dataingestion, indexing, and querying. If this sounds exciting, connect in the thread!
Transforming raw data into features using aggregation, encoding, normalization, and other operations is often needed and can require significant effort. Engineers must manually write custom data preprocessing and aggregation logic in Python or Spark for each use case. The following screenshot shows an example of the dataset.
This e-book focuses on adapting large language models (LLMs) to specific use cases by leveraging Prompt Engineering, Fine-Tuning, and Retrieval Augmented Generation (RAG), tailored for readers with an intermediate knowledge of Python. He is looking for someone with project ideas and a basic understanding of AI and coding (preferably Python).
As organisations increasingly rely on data-driven insights, effective ETL processes ensure data integrity and quality, enabling informed decision-making. Talend Talend is another powerful ETL tool that offers a comprehensive suite for data transformation, including data cleansing, normalisation, and enrichment features.
Amazon SageMaker Processing jobs for large scale dataingestion into OpenSearch. This notebook will ingest the SageMaker docs to an OpenSearch Service index called llm_apps_workshop_embeddings. This will download the dataset locally into the notebook and then ingest it into the OpenSearch Service index.
For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc., This includes features for data labeling, data versioning, data augmentation, and integration with popular data storage systems.
Andre Franca | CTO | connectedFlow Join this session to demystify the world of Causal AI, with a focus on understanding cause-and-effect relationships within data to drive optimal decisions. Learn how to use XGBoost and see firsthand how to create, tune, evaluate, and interpret a model.
This post explains the functions based on a modular pipeline approach. SageMaker has developed the distributed data parallel library , which splits data per node and optimizes the communication between the nodes. Each node has a copy of the DNN.
You can implement this workflow in Forecast either from the AWS Management Console , the AWS Command Line Interface (AWS CLI), via API calls using Python notebooks , or via automation solutions. The console and AWS CLI methods are best suited for quick experimentation to check the feasibility of time series forecasting using your data.
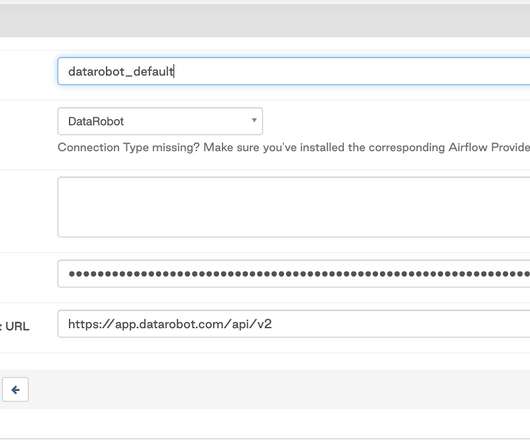
This type of ML orchestration can provide the best-informed predictions from your organization’s models, regularly trained on the most recent data. The DataRobot provider for Apache Airflow is a Python package built from source code available in a public GitHub repository and published in PyPi (The Python Package Index).
That is where Provectus , an AWS Premier Consulting Partner with competencies in Machine Learning, Data & Analytics, and DevOps, stepped in. They needed a cloud platform and a strategic partner with proven expertise in delivering production-ready AI/ML solutions, to quickly bring EarthSnap to the market.
These skills enable professionals to leverage Azure’s cloud technologies effectively and address complex data challenges. Below are the essential skills required for thriving in this role: Programming Proficiency: Expertise in languages such as Python or R for coding and data manipulation.
Summary: This blog explains how to build efficient data pipelines, detailing each step from data collection to final delivery. Introduction Data pipelines play a pivotal role in modern data architecture by seamlessly transporting and transforming raw data into valuable insights.
Andre Franca | CTO | connectedFlow Explore the world of Causal AI for data science practitioners, with a focus on understanding cause-and-effect relationships within data to drive optimal decisions. Don’t miss this chance to learn from some of the data practitioners defining the future of the industry. Sign me up!
In the image, you can see that the extract the weather data and extract metadata information about the location need to run in parallel. This is necessary because additional Python modules need to be installed. Similarly, if you need to complete a Python process, you will need the Python operator.
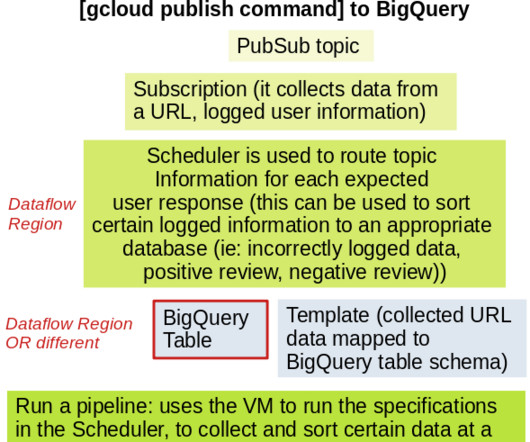
BigQuery is very useful in terms of having a centralized location of structured data; ingestion on GCP is wonderful using the ‘bq load’ command line tool for uploading local .csv PubSub and Dataflow are solutions for storing newly created data from website/application activity, in either BigQuery or Google Cloud Storage.
This post, part of the Governing the ML lifecycle at scale series ( Part 1 , Part 2 , Part 3 ), explains how to set up and govern a multi-account ML platform that addresses these challenges. You can choose which option to use depending on your setup.
The components comprise implementations of the manual workflow process you engage in for automatable steps, including: Dataingestion (extraction and versioning). Data validation (writing tests to check for data quality). Data preprocessing. Is it a black-box model, or can the decisions be explained?
A typical pipeline may include: DataIngestion: The process begins with ingesting raw data from different sources, such as databases, files, or APIs. For example, Scikit-learn, a popular Python library, offers the Pipeline class to streamline preprocessing and model training. to log your experiments.
Inconsistent data formats, missing values, and data bias can significantly impact the success of large-scale Data Science projects. Ensuring data quality and implementing robust data pipelines for cleaning and standardization becomes paramount.
.” — Conor Murphy , Lead Data Scientist at Databricks, in “Survey of Production ML Tech Stacks” at the Data+AI Summit 2022 Your team should be motivated by MLOps to show everything that goes into making a machine learning model, from getting the data to deploying and monitoring the model. Responsible AI and explainability.
Generative AI solutions often use Retrieval Augmented Generation (RAG) architectures, which augment external knowledge sources for improving content quality, context understanding, creativity, domain-adaptability, personalization, transparency, and explainability. data # Assing local directory path to a python variable local_data_path = "./data/"
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content