This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Prescriptive AI relies on several essential components that work together to turn raw data into actionable recommendations. The process begins with dataingestion and preprocessing, where prescriptive AI gathers information from different sources, such as IoT sensors, databases, and customer feedback.
Data lineage becomes even more important as the need to provide “Explainability” in models is required by regulatory bodies. Enterprise data is often complex, diverse and scattered across various repositories, making it difficult to integrate into gen AI solutions.
Operationalisation needs good orchestration to make it work, as Basil Faruqui, director of solutions marketing at BMC , explains. “If CRMs and ERPs had been going the SaaS route for a while, but we started seeing more demands from the operations world for SaaS consumption models,” explains Faruqui.
Drasi's Real-Time Data Processing Architecture Drasi’s design is centred around an advanced, modular architecture, prioritizing scalability, speed, and real-time operation. Maily, it depends on continuous dataingestion , persistent monitoring, and automated response mechanisms to ensure immediate action on data changes.
Kaushik Muniandi, engineering manager at NielsenIQ, will explain how he leveraged a data lakehouse to overcome these challenges for a text-based search application, and the performance improvements he measured.
At Snorkel, weve partnered with Databricks to create a powerful synergy between their data lakehouse and our Snorkel Flow AI data development platform. Ingesting raw data from Databricks into Snorkel Flow Efficient dataingestion is the foundation of any machine learning project. Sign up here!
Integrating proprietary enterprise data from internal knowledge bases enables chatbots to contextualize their responses to each user’s individual needs and interests. RAG architecture involves two key workflows: data preprocessing through ingestion, and text generation using enhanced context.
The book starts by explaining what it takes to be a digital maverick and how enterprises can leverage digital solutions to transform how data is utilized. A digital maverick is typically characterized by big-picture thinking, technical prowess, and the understanding that systems can be optimized through dataingestion.
TLDR; In this article, we will explain multi-hop retrieval and how it can be leveraged to build RAG systems that require complex reasoning We will showcase the technique by building a Q&A chatbot in the healthcare domain using Indexify, OpenAI, and DSPy. These pipelines are defined using declarative configuration.
However, in industrial applications, the main bottleneck in efficient document retrieval often lies in the dataingestion pipeline rather than the embedding model’s performance. Optimizing this pipeline is crucial for extracting meaningful data that aligns with the capabilities of advanced retrieval systems.
TLDR; In this article, we will explain multi-hop retrieval and how it can be leveraged to build RAG systems that require complex reasoning We will showcase the technique by building a Q&A chatbot in the healthcare domain using Indexify, OpenAI, and DSPy. These pipelines are defined using declarative configuration.
These include dataingestion, data selection, data pre-processing, FM pre-training, model tuning to one or more downstream tasks, inference serving, and data and AI model governance and lifecycle management—all of which can be described as FMOps.
Model transparency – Although achieving full transparency in generative AI models remains challenging, organizations can take several steps to enhance model transparency and explainability: Provide model cards on the model’s intended use, performance, capabilities, and potential biases.
It emphasizes the role of LLamaindex in building RAG systems, managing dataingestion, indexing, and querying. Data preparation using Roboflow, model loading and configuration PaliGemma2 (including optional LoRA/QLoRA), and data loader creation are explained.
The solution notebook feature_processor.ipynb contains the following main steps, which we explain in this post: Create two feature groups: one called car-data for raw car sales records and another called car-data-aggregated for aggregated car sales records. Choose the car-data-ingestion-pipeline.
The model will be approved by designated data scientists to deploy the model for use in production. For production environments, dataingestion and trigger mechanisms are managed via a primary Airflow orchestration. Model registry – The trained model is registered for future use.
As organisations increasingly rely on data-driven insights, effective ETL processes ensure data integrity and quality, enabling informed decision-making. Talend : An open-source ETL tool that provides extensive connectivity options and data transformation features, allowing customisation and scalability.
In this session, you will learn how explainability can help you identify poor model performance or bias, as well as discuss the most commonly used algorithms, how they work, and how to get started using them. Why is it important? What techniques are there and how do they work?
Typically, you determine the number of components to include in your model by cumulatively adding the explained variance ratio of each component until you reach 0.8–0.9 Refer to the Amazon Forecast Developer Guide for information about dataingestion , predictor training , and generating forecasts. to avoid overfitting.
Streamline ML Workflow with MLflow — II by ronilpatil This article explains how to leverage MLflow to track machine learning experiments, register a model, and serve the model into production. Building an Enterprise Data Lake with Snowflake Data Cloud & Azure using the SDLS Framework.
For example, you may start with wanting to solve the customer churn problem but end up uncovering a nasty data quality issue or lack of tools to build the most effective solution. This discovery may distract you with an initiative to overhaul the entire data capture system and dataingestion pipelines.
This post explains the functions based on a modular pipeline approach. In the following figure, we provide a reference architecture to preprocess data using AWS Batch and using Ground Truth to label the datasets. For more information on using Ground Truth to label 3D point cloud data, refer to Use Ground Truth to Label 3D Point Clouds.
At Snorkel, weve partnered with Databricks to create a powerful synergy between their data lakehouse and our Snorkel Flow AI data development platform. Ingesting raw data from Databricks into Snorkel Flow Efficient dataingestion is the foundation of any machine learning project. Sign up here!
Understanding the MLOps Lifecycle The MLOps lifecycle consists of several critical stages, each with its unique challenges: DataIngestion: Collecting data from various sources and ensuring it’s available for analysis. Data Preparation: Cleaning and transforming raw data to make it usable for machine learning.
The dependencies template deploys a role to be used by Lambda and another for Step Functions, a workflow management service that will coordinate the tasks of dataingestion and processing, as well as predictor training and inference using Forecast. These determine if explainability is enabled for your predictor.
When combined with Snorkel Flow, it becomes a powerful enabler for enterprises seeking to harness the full potential of their proprietary data. What the Snorkel Flow + AWS integrations offer Streamlined dataingestion and management: With Snorkel Flow, organizations can easily access and manage unstructured data stored in Amazon S3.
Data engineering – Identifies the data sources, sets up dataingestion and pipelines, and prepares data using Data Wrangler. Data science – The heart of ML EBA and focuses on feature engineering, model training, hyperparameter tuning, and model validation.
That is where Provectus , an AWS Premier Consulting Partner with competencies in Machine Learning, Data & Analytics, and DevOps, stepped in. They needed a cloud platform and a strategic partner with proven expertise in delivering production-ready AI/ML solutions, to quickly bring EarthSnap to the market.
Explainability – Providing transparency into why certain stories are recommended builds user trust. We discuss more about how to use items and interactions data attributes in DynamoDB later in this post. The following diagram illustrates the dataingestion architecture.
Topics Include: Advanced ML Algorithms & EnsembleMethods Hyperparameter Tuning & Model Optimization AutoML & Real-Time MLSystems Explainable AI & EthicalAI Time Series Forecasting & NLP Techniques Who Should Attend: ML Engineers, Data Scientists, and Technical Practitioners working on production-level ML solutions.
This evolution underscores the demand for innovative platforms that simplify dataingestion and transformation, enabling faster, more reliable decision-making. Tamer stressed the importance of integrating explainability into AI solutions to enhance trust andutility.
Andre Franca | CTO | connectedFlow Join this session to demystify the world of Causal AI, with a focus on understanding cause-and-effect relationships within data to drive optimal decisions. In particular, you’ll explore Google’s Vertex AI for both no-code and low-code ML model training, and Google’s Colab, a free Jupyter Notebook service.
Core features of end-to-end MLOps platforms End-to-end MLOps platforms combine a wide range of essential capabilities and tools, which should include: Data management and preprocessing : Provide capabilities for dataingestion, storage, and preprocessing, allowing you to efficiently manage and prepare data for training and evaluation.
This type of ML orchestration can provide the best-informed predictions from your organization’s models, regularly trained on the most recent data. We explain the construction of these settings in the sections below. Values in the training_data and score_settings depend on the intake/output type.
It takes something that’s hard to do but important to get right — forecasting — and supercharges data scientists. With automated feature engineering, automated model development, and more explainable forecasts, data scientists can build more models with more accuracy, speed, and confidence. Forecasting the future is difficult.
The first part is all about the core TFX pipeline handling all the steps from dataingestion to model deployment. We built a simple yet complete ML pipeline with support for automatic dataingestion, data preprocessing, model training, model evaluation, and model deployment in TFX. Hub service.
Andre Franca | CTO | connectedFlow Explore the world of Causal AI for data science practitioners, with a focus on understanding cause-and-effect relationships within data to drive optimal decisions. Don’t miss this chance to learn from some of the data practitioners defining the future of the industry. Sign me up!
Summary: This blog explains how to build efficient data pipelines, detailing each step from data collection to final delivery. Introduction Data pipelines play a pivotal role in modern data architecture by seamlessly transporting and transforming raw data into valuable insights.
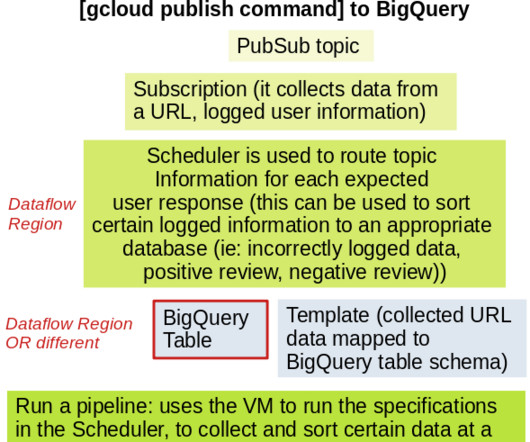
BigQuery is very useful in terms of having a centralized location of structured data; ingestion on GCP is wonderful using the ‘bq load’ command line tool for uploading local .csv PubSub and Dataflow are solutions for storing newly created data from website/application activity, in either BigQuery or Google Cloud Storage.
Data Visualization: Ability to create compelling visualisations to communicate insights effectively. Problem-solving and Communication Skills: Strong analytical skills and the ability to explain complex concepts to non-technical stakeholders.
This post, part of the Governing the ML lifecycle at scale series ( Part 1 , Part 2 , Part 3 ), explains how to set up and govern a multi-account ML platform that addresses these challenges. You can choose which option to use depending on your setup.
Develop the text preprocessing pipeline Dataingestion: Use Unstructured.io to ingestdata from health forums, medical journals, and wellness blogs. Next, preprocess this data by cleaning, normalizing text, and splitting it into manageable chunks.
In the upcoming part of this series, we will delve into advanced concepts of Airflow, including backfilling techniques and building an ETL pipeline in Airflow for dataingestion into Postgres and Google Cloud BigQuery. You have learned how to trigger a DAG in Airflow, create a DAG from scratch, and initiate its execution.
Amazon SageMaker Processing jobs for large scale dataingestion into OpenSearch. This notebook will ingest the SageMaker docs to an OpenSearch Service index called llm_apps_workshop_embeddings. This will download the dataset locally into the notebook and then ingest it into the OpenSearch Service index.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content