This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
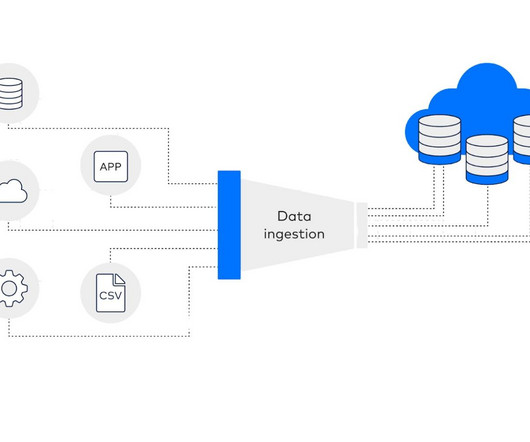
This article was published as a part of the Data Science Blogathon. Introduction to Apache Flume Apache Flume is a dataingestion mechanism for gathering, aggregating, and transmitting huge amounts of streaming data from diverse sources, such as log files, events, and so on, to a centralized data storage.
Introduction Apache Flume is a tool/service/dataingestion mechanism for gathering, aggregating, and delivering huge amounts of streaming data from diverse sources, such as log files, events, and so on, to centralized data storage. Flume is a tool that is very dependable, distributed, and customizable.
Additionally, they accelerate time-to-market for AI-driven innovations by enabling rapid dataingestion and retrieval, facilitating faster experimentation. Check out AI & Big Data Expo taking place in Amsterdam, California, and London.
Amazon Q Business , a new generative AI-powered assistant, can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in an enterprises systems. Large-scale dataingestion is crucial for applications such as document analysis, summarization, research, and knowledge management.
If you think about building a data pipeline, whether you’re doing a simple BI project or a complex AI or machine learning project, you’ve got dataingestion, data storage and processing, and data insight – and underneath all of those four stages, there’s a variety of different technologies being used,” explains Faruqui.
What is Real-Time DataIngestion? Real-time dataingestion is the practise of gathering and analysing information as it is produced, without little to no lag between the emergence of the data and its accessibility for analysis. Traders need up-to-the-second information to make informed decisions.
Understanding Drasi Drasi is an advanced event-driven architecture powered by Artificial Intelligence (AI) and designed to handle real-time data changes. Traditional data systems often rely on batch processing, where data is collected and analyzed at set intervals.
From discussing current events to seeking local recommendations, studying for exams, coding, and even casual conversations, Pi powered by Inflection-2.5 As a vertically integrated AI studio, Inflection AI handles the entire process in-house, from dataingestion and model design to high-performance infrastructure.
The list of challenges is long: cloud attack surface sprawl, complex application environments, information overload from disparate tools, noise from false positives and low-risk events, just to name a few.
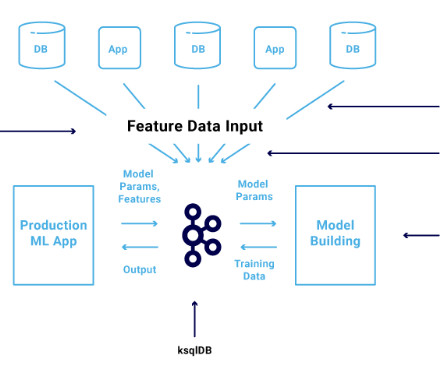
The Apache Kafka ecosystem is used more and more to build scalable and reliable machine learning infrastructure for dataingestion, preprocessing, model training, real-time predictions, and monitoring. Data processing happens in batch mode with the data stored at rest and can take minutes or even hours.
With this new capability, you can ask questions of your data without the overhead of setting up a vector database or ingestingdata, making it effortless to use your enterprise data. You can now interact with your documents in real time without prior dataingestion or database configuration.
Moreover, when delivered alongside our CatDV solution, customers can tag and catalog data to further enrich their data and prepare it for analysis and AI. Could you share insights on the use of AI with video surveillance at the Paris Olympics, and what other large-scale events or organizations have utilized this technology?
We add the record identifier model_year_status and event time ingest_time to this feature group. Now, create the car-data feature group: # Create Feature Group - Car sale records. Add the event time to the ingest_time column. Choose the car-data-ingestion-pipeline. Choose the car-data feature group.
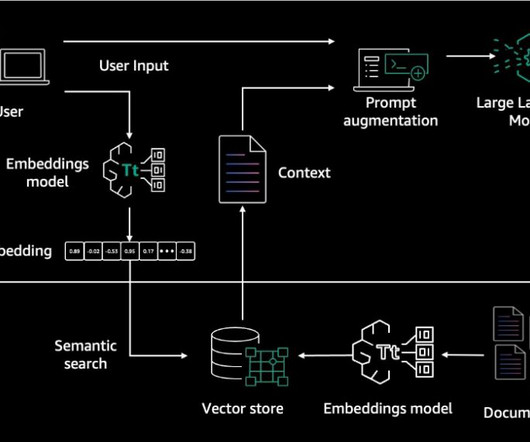
RAG architecture involves two key workflows: data preprocessing through ingestion, and text generation using enhanced context. The dataingestion workflow uses LLMs to create embedding vectors that represent semantic meaning of texts. It offers fully managed dataingestion and text generation workflows.
With the IoT, tracking website clicks, capturing call data records for a mobile network carrier, tracking events generated by “smart meters” and embedded devices can all generate huge volumes of transactions. Many consider a NoSQL database essential for high dataingestion rates.
Chronon empowers ML practitioners to define features and centralize data computation for model training and production inference, guaranteeing accuracy and consistency throughout the process. Whether real-time eventdata or historical snapshots, Chronon handles it all seamlessly.
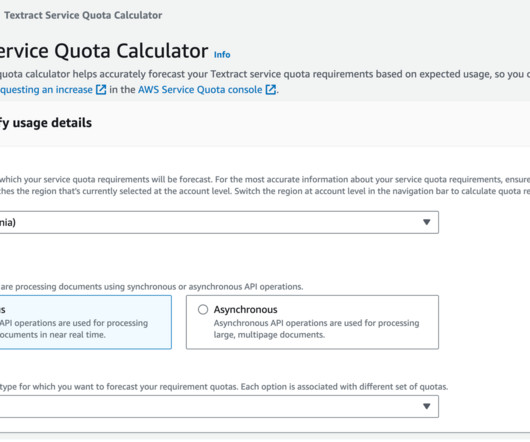
Effectively manage your data and its lifecycle Data plays a key role throughout your IDP solution. Starting with the initial dataingestion, data is pushed through various stages of processing, and finally returned as output to end-users. Amazon Textract requires at least 150 DPI.
You can also use Amazon EventBridge to monitor events related to Amazon Bedrock. This allows you to create rules that invoke specific actions when certain events occur, enhancing the automation and responsiveness of your observability setup (for more details, see Monitor Amazon Bedrock ).
It performs strict input validation by extracting the event payload from API Gateway and conducting both syntactic and semantic validation. By default, Amazon Bedrock encrypts all knowledge base-related data using an AWS managed key. Alternatively, you can choose to use a customer managed key.
Summary: Apache NiFi is a powerful open-source dataingestion platform design to automate data flow management between systems. Its architecture includes FlowFiles, repositories, and processors, enabling efficient data processing and transformation.
It emphasizes the role of LLamaindex in building RAG systems, managing dataingestion, indexing, and querying. The article details how these leaks occur, citing examples of real-world incidents, and explores the roles of developers, users, and attackers in these events.
Dataingestion and extraction Evaluation reports are prepared and submitted by UNDP program units across the globe—there is no standard report layout template or format. The dataingestion and extraction component ingests and extracts content from these unstructured documents.
Amazon Athena to provide developers and business analysts SQL access to the generated data for analysis and troubleshooting. Amazon EventBridge to trigger the dataingestion and ML pipeline on a schedule and in response to events. This construct provides a fully event-driven workflow.
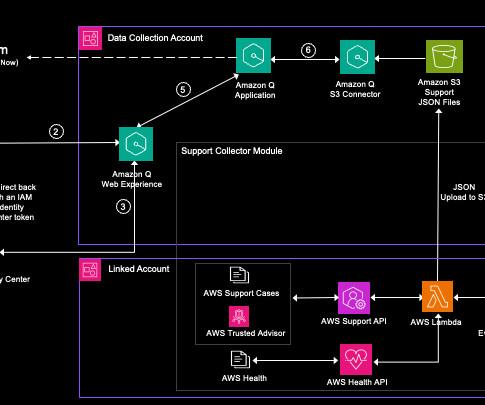
Amazon Q Business is a fully managed, secure, generative-AI powered enterprise chat assistant that enables natural language interactions with your organization’s data. The collected data can be analyzed using Amazon Q Business. It is giving ConfigurationConflict errors. Based on past support cases, please provide a resolution.
The service allows for simple audio dataingestion, easy-to-read transcript creation, and accuracy improvement through custom vocabularies. This S3 event triggers the Notification Lambda function, which pushes the summary to an Amazon Simple Notification Service (Amazon SNS) topic.
With an understanding of the problem and solution, the subsequent sections dive into how to automate data sourcing through the crawling of architecture diagrams from credible sources. Lastly, we cover the dataingestion by an intelligent search service, powered by ML.
Rockets legacy data science architecture is shown in the following diagram. The diagram depicts the flow; the key components are detailed below: DataIngestion: Data is ingested into the system using Attunity dataingestion in Spark SQL.
Set up regular game days to test workload and team responses to simulated events. Learn from all operational failures – Drive improvement through lessons learned from all operational events and failures. By centralizing datasets within the flywheel’s dedicated Amazon S3 data lake, you ensure efficient data management.
For instance, FOX Sports experienced a 400% increase in viewership content starts post-event when applied. You follow the same process of dataingestion, training, and creating a batch inference job as in the previous use case. Amazon Personalize has helped us achieve high levels of automation in content customization.
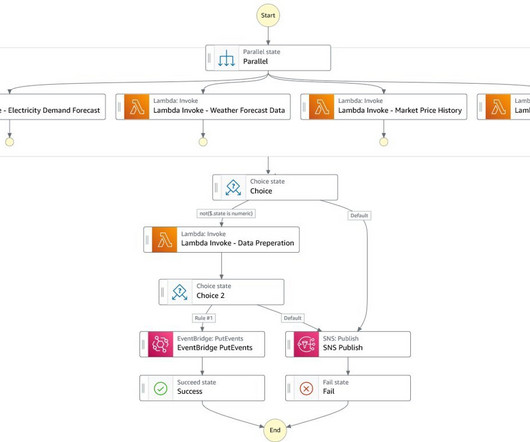
In this case, we are developing a forecasting model, so there are two main steps to complete: Train the model to make predictions using historical data. Apply the trained model to make predictions of future events. The model will be approved by designated data scientists to deploy the model for use in production.
MongoDB Atlas offers automatic sharding, horizontal scalability, and flexible indexing for high-volume dataingestion. Among all, the native time series capabilities is a standout feature, making it ideal for a managing high volume of time-series data, such as business critical application data, telemetry, server logs and more.
We use an S3 bucket in this solution to store source data and trigger the workflow, resulting in a forecast. Lambda is a serverless, event-driven compute service that lets you run code without provisioning or managing servers. Amazon S3 is a low-cost, highly available, resilient, object storage service.
Traditional maintenance activities rely on a sizable workforce distributed across key locations along the BHS dispatched by operators in the event of an operational fault. Eliminating noise from the data After a few weeks, we noticed that Lookout for Equipment was emitting some events thought to be false positives.
In the later part of this article, we will discuss its importance and how we can use machine learning for streaming data analysis with the help of a hands-on example. What is streaming data? This will also help us observe the importance of stream data. It can be used to collect, store, and process streaming data in real-time.
Within this data ocean, a specific type holds immense value: time series data. This data captures measurements or events at specific points in time, essentially creating a digital record of how something changes over time. Aggregation and Downsampling TSDBs offer functionalities to aggregate data over time intervals (e.g.,
To proactively recommend articles on companies or industries that users are reading about, you can record how frequently readers are engaging with articles about specific companies and industries, and use this data with Amazon Personalize filters to further tailor the recommended content.
Streamlining Unstructured Data for Retrieval Augmented Generatio n Matt Robinson | Open Source Tech Lead | Unstructured Learn about the complexities of handling unstructured data, and practical strategies for extracting usable text and metadata from it. You’ll also discuss loading processed data into destination storage.
Serverless architectures – IDP is often an event-driven solution, initiated by user uploads or scheduled jobs. Additionally, the solution must handle high data volumes with low latency and high throughput. These advantages can enable you to optimize the usage and cost of underlying AI services.
Other steps include: dataingestion, validation and preprocessing, model deployment and versioning of model artifacts, live monitoring of large language models in a production environment, monitoring the quality of deployed models and potentially retraining them.
Furthermore, The platform’s versatility extends beyond data analysis. The pricing structure is based on the volume of dataingested, which can add up quickly for large-scale deployments. Resource Requirements Splunk’s data processing and indexing can consume significant system resources.
In this workshop, you’ll explore no-code and low-code frameworks, how they are used in the ML workflow, how they can be used for dataingestion and analysis, and how they can be used for building, training, and deploying ML models. You can also get data science training on-demand wherever you are with our Ai+ Training platform.
Learn more about our first-announced sessions coming to the event this April 23rd-25th below. Causal AI: from Data to Action Dr. Andre Franca | CTO | connectedFlow Explore the world of Causal AI for data science practitioners, with a focus on understanding cause-and-effect relationships within data to drive optimal decisions.
The lead data scientist approves the model locally in the ML Dev Account. This step consists of the following sub-steps: After the data scientists approve the model, it triggers an event bus in Amazon EventBridge that ships the event to the ML Shared Services Account.
Streamlining Unstructured Data for Retrieval Augmented Generation Matt Robinson | Open Source Tech Lead | Unstructured In this talk, you’ll explore the complexities of handling unstructured data, and offer practical strategies for extracting usable text and metadata from unstructured data. Interested in attending an ODSC event?
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content