This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
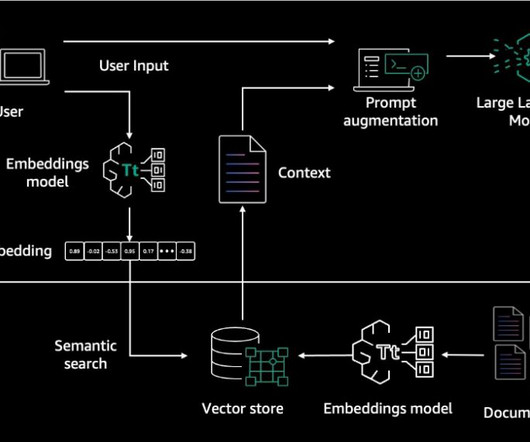
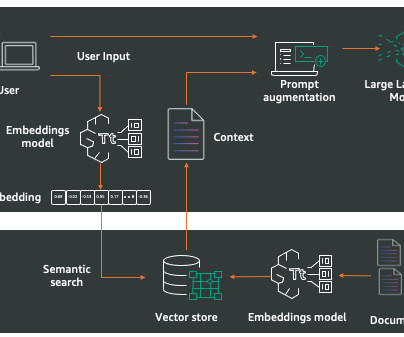
On the other hand, a Node is a snippet or “chunk” from a Document, enriched with metadata and relationships to other nodes, ensuring a robust foundation for precise data retrieval later on. Data Indexes : Post dataingestion, LlamaIndex assists in indexing this data into a retrievable format.
Problem Statement In this experiment, I will build a Multi-Hop Question-Answering chatbot using Indexify, OpenAI, and DSPy (a Declarative Sequencing Python framework). Each stage of the pipeline can perform structured extraction using any AI model or transform ingesteddata. pip install gradio==4.31.0 pip install dspy-ai==2.0.8
Problem Statement In this experiment, I will build a Multi-Hop Question-Answering chatbot using Indexify, OpenAI, and DSPy (a Declarative Sequencing Python framework). Each stage of the pipeline can perform structured extraction using any AI model or transform ingesteddata. pip install gradio==4.31.0 pip install dspy-ai==2.0.8
RAG architecture involves two key workflows: data preprocessing through ingestion, and text generation using enhanced context. The dataingestion workflow uses LLMs to create embedding vectors that represent semantic meaning of texts. It offers fully managed dataingestion and text generation workflows.
Download it here and support a fellow community member. Python = Powerful AI Research Agent By Gao Dalie () This article details building a powerful AI research agent using Pydantic AI, a web scraper (Tavily), and Llama 3.3. It emphasizes the role of LLamaindex in building RAG systems, managing dataingestion, indexing, and querying.
Many ML systems benefit from having the feature store as their data platform, including: Interactive ML systems receive a user request and respond with a prediction. An interactive ML system either downloads a model and calls it directly or calls a model hosted in a model-serving infrastructure.
The DataRobot provider for Apache Airflow is a Python package built from source code available in a public GitHub repository and published in PyPi (The Python Package Index). The integration uses the DataRobot Python API Client , which communicates with DataRobot instances via REST API. DataRobot Python API Client >= 2.27.1.
You can implement this workflow in Forecast either from the AWS Management Console , the AWS Command Line Interface (AWS CLI), via API calls using Python notebooks , or via automation solutions. The console and AWS CLI methods are best suited for quick experimentation to check the feasibility of time series forecasting using your data.
In Part 1 , we discussed the applications of GNNs and how to transform and prepare our IMDb data into a knowledge graph (KG). We downloaded the data from AWS Data Exchange and processed it in AWS Glue to generate KG files. Initializes the OpenSearch Service client using the Boto3 Python library.
Amazon SageMaker Processing jobs for large scale dataingestion into OpenSearch. This notebook will ingest the SageMaker docs to an OpenSearch Service index called llm_apps_workshop_embeddings. This will download the dataset locally into the notebook and then ingest it into the OpenSearch Service index.
Download press releases to use as our external knowledge base. Deploy with the SageMaker Python SDK You can use the SageMaker Python SDK to deploy the LLMs, as shown in the code available in the repository. Deploy an embedding model from the Amazon SageMaker JumpStart hub. Query the knowledge base.
This includes preparing data, creating a SageMaker model, and performing batch transform using the model. Data overview and preparation You can use a SageMaker Studio notebook with a Python 3 (Data Science) kernel to run the sample code. data/images' local_file_name = Path(s3_path).name path local_data_root = f'.
Windows and Mac have docker and docker-compose packaged into one application, so if you download docker on Windows or Mac, you have both docker and docker-compose. To download it, type this in your terminal curl -LFO '[link] and press enter. This is necessary because additional Python modules need to be installed.
For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc., This includes features for data labeling, data versioning, data augmentation, and integration with popular data storage systems.
Some industries rely not only on traditional data but also need data from sources such as security logs, IoT sensors, and web applications to provide the best customer experience. For example, before any video streaming services, users had to wait for videos or audio to get downloaded. pip install tensorflow== 2.7.1 !pip
A typical data pipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process. DataIngestion : Involves raw data collection from origin and storage using architectures such as batch, streaming or event-driven.
The Widespread Adoption of Open DataScience The use of open source data science tools has absolutely explodedwere talking a whopping 650% growth over the past five years. Additionally, a clear majority of current projects ( 85% to be exact) leverage open-source programming languages like Python and R rather than proprietary options.
This content builds on posts such as Deploy a Slack gateway for Amazon Bedrock by adding integrations to Amazon Bedrock Knowledge Bases and Amazon Bedrock Guardrails, and the Bolt for Python library to simplify Slack message acknowledgement and authentication requirements.
Data lineage and auditing – Metadata can provide information about the provenance and lineage of documents, such as the source system, dataingestion pipeline, or other transformations applied to the data. This information can be valuable for data governance, auditing, and compliance purposes.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content