This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
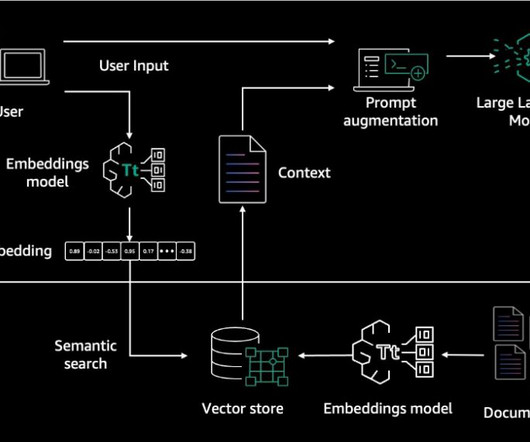
Amazon Q Business , a new generative AI-powered assistant, can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in an enterprises systems. Large-scale dataingestion is crucial for applications such as document analysis, summarization, research, and knowledge management.
Recently, pretrained language models have significantly advanced text embedding models, enabling better semantic understanding for tasks (e.g., However, in industrial applications, the main bottleneck in efficient document retrieval often lies in the dataingestion pipeline rather than the embedding model’s performance.
Building a multi-hop retrieval is a key challenge in naturallanguageprocessing (NLP) and information retrieval because it requires the system to understand the relationships between different pieces of information and how they contribute to the overall answer. These pipelines are defined using declarative configuration.
SageMaker Canvas supports multiple ML modalities and problem types, catering to a wide range of use cases based on data types, such as tabular data (our focus in this post), computer vision, naturallanguageprocessing, and document analysis. To download a copy of this dataset, visit.
Building a multi-hop retrieval is a key challenge in naturallanguageprocessing (NLP) and information retrieval because it requires the system to understand the relationships between different pieces of information and how they contribute to the overall answer. These pipelines are defined using declarative configuration.
Retrieval Augmented Generation RAG is an approach to naturallanguage generation that incorporates information retrieval into the generation process. RAG architecture involves two key workflows: data preprocessing through ingestion, and text generation using enhanced context. Navigate to the dataset folder.
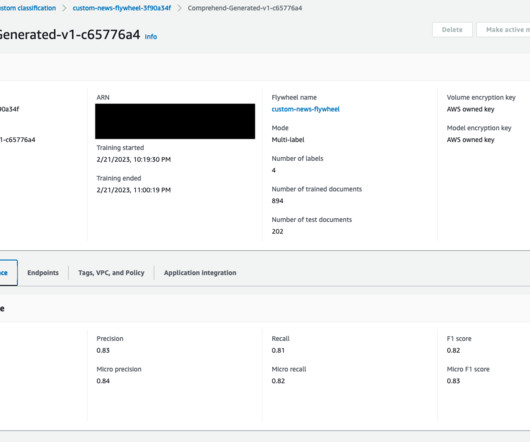
Solution overview Amazon Comprehend is a fully managed service that uses naturallanguageprocessing (NLP) to extract insights about the content of documents. An Amazon Comprehend flywheel automates this ML process, from dataingestion to deploying the model in production. Choose Create job.
Once an organization has identified its AI use cases , data scientists informally explore methodologies and solutions relevant to the business’s needs in the hunt for proofs of concept. These might include—but are not limited to—deep learning, image recognition and naturallanguageprocessing. Download Now.
Download press releases to use as our external knowledge base. Call the loader’s load_data method to parse your source files and data and convert them into LlamaIndex Document objects, ready for indexing and querying. Romina’s areas of interest are naturallanguageprocessing, large language models, and MLOps.
Amazon SageMaker Processing jobs for large scale dataingestion into OpenSearch. This notebook will ingest the SageMaker docs to an OpenSearch Service index called llm_apps_workshop_embeddings. This will download the dataset locally into the notebook and then ingest it into the OpenSearch Service index.
In Part 1 , we discussed the applications of GNNs and how to transform and prepare our IMDb data into a knowledge graph (KG). We downloaded the data from AWS Data Exchange and processed it in AWS Glue to generate KG files. Matthew Rhodes is a Data Scientist I working in the Amazon ML Solutions Lab.
Learn more The Best Tools, Libraries, Frameworks and Methodologies that ML Teams Actually Use – Things We Learned from 41 ML Startups [ROUNDUP] Key use cases and/or user journeys Identify the main business problems and the data scientist’s needs that you want to solve with ML, and choose a tool that can handle them effectively.
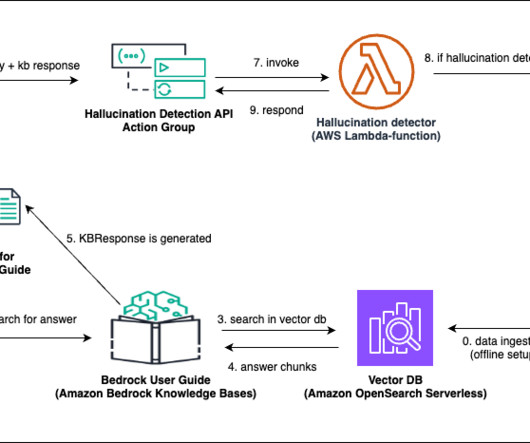
The RAG-based chatbot we use ingests the Amazon Bedrock User Guide to assist customers on queries related to Amazon Bedrock. Dataset The dataset used in the notebook is the latest Amazon Bedrock User guide PDF file, which is publicly available to download. His area of research is all things naturallanguage (like NLP, NLU, and NLG).
Data lineage and auditing – Metadata can provide information about the provenance and lineage of documents, such as the source system, dataingestion pipeline, or other transformations applied to the data. This information can be valuable for data governance, auditing, and compliance purposes.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















Let's personalize your content