This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The book starts by explaining what it takes to be a digital maverick and how enterprises can leverage digital solutions to transform how data is utilized. A digital maverick is typically characterized by big-picture thinking, technical prowess, and the understanding that systems can be optimized through dataingestion.
TLDR; In this article, we will explain multi-hop retrieval and how it can be leveraged to build RAG systems that require complex reasoning We will showcase the technique by building a Q&A chatbot in the healthcare domain using Indexify, OpenAI, and DSPy. These pipelines are defined using declarative configuration.
TLDR; In this article, we will explain multi-hop retrieval and how it can be leveraged to build RAG systems that require complex reasoning We will showcase the technique by building a Q&A chatbot in the healthcare domain using Indexify, OpenAI, and DSPy. These pipelines are defined using declarative configuration.
However, in industrial applications, the main bottleneck in efficient document retrieval often lies in the dataingestion pipeline rather than the embedding model’s performance. Optimizing this pipeline is crucial for extracting meaningful data that aligns with the capabilities of advanced retrieval systems.
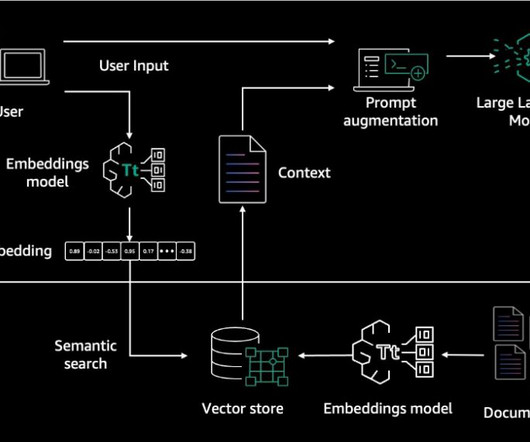
Integrating proprietary enterprise data from internal knowledge bases enables chatbots to contextualize their responses to each user’s individual needs and interests. RAG architecture involves two key workflows: data preprocessing through ingestion, and text generation using enhanced context. Navigate to the dataset folder.
Download it here and support a fellow community member. It emphasizes the role of LLamaindex in building RAG systems, managing dataingestion, indexing, and querying. Data preparation using Roboflow, model loading and configuration PaliGemma2 (including optional LoRA/QLoRA), and data loader creation are explained.
The dependencies template deploys a role to be used by Lambda and another for Step Functions, a workflow management service that will coordinate the tasks of dataingestion and processing, as well as predictor training and inference using Forecast. These determine if explainability is enabled for your predictor.
This type of ML orchestration can provide the best-informed predictions from your organization’s models, regularly trained on the most recent data. We explain the construction of these settings in the sections below. Multipersona Data Science and Machine Learning (DSML) Platforms. Download now. References. *
Amazon SageMaker Processing jobs for large scale dataingestion into OpenSearch. This notebook will ingest the SageMaker docs to an OpenSearch Service index called llm_apps_workshop_embeddings. This will download the dataset locally into the notebook and then ingest it into the OpenSearch Service index.
Core features of end-to-end MLOps platforms End-to-end MLOps platforms combine a wide range of essential capabilities and tools, which should include: Data management and preprocessing : Provide capabilities for dataingestion, storage, and preprocessing, allowing you to efficiently manage and prepare data for training and evaluation.
Windows and Mac have docker and docker-compose packaged into one application, so if you download docker on Windows or Mac, you have both docker and docker-compose. To download it, type this in your terminal curl -LFO '[link] and press enter. The docker-compose.yaml file that will be used is the official file from Apache Airflow.
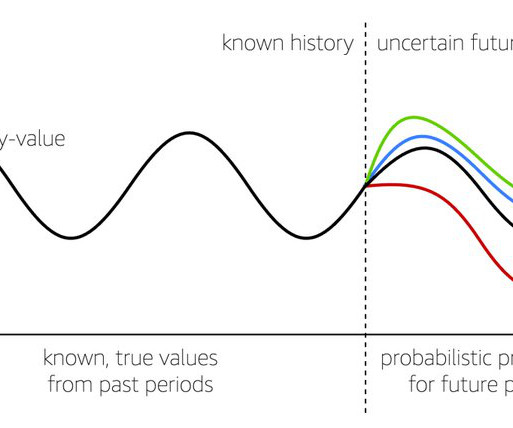
We dive into Amazon SageMaker Canvas and explain how SageMaker Canvas can solve forecasting challenges for retail and consumer packaged goods (CPG) enterprises. To download a copy of this dataset, visit. To change the quantiles from the default values as explained previously, in the left navigation pane, choose Forecast quantiles.
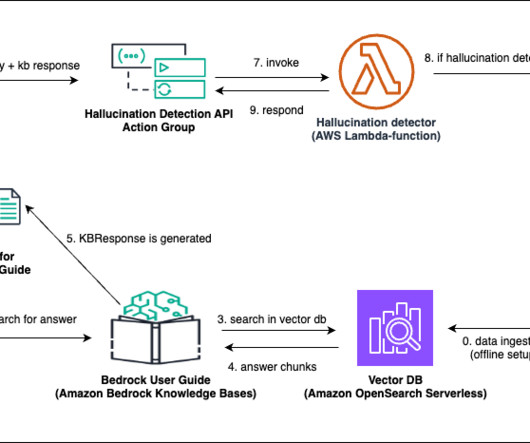
The RAG-based chatbot we use ingests the Amazon Bedrock User Guide to assist customers on queries related to Amazon Bedrock. Dataset The dataset used in the notebook is the latest Amazon Bedrock User guide PDF file, which is publicly available to download. Set up an Amazon SageMaker notebook on an ml.t3.medium
It contains two flows: Dataingestion – The dataingestion flow converts the damage datasets (images and metadata) into vector embeddings and stores them in the OpenSearch vector store. We need to initially invoke this flow to load all the historic data into OpenSearch. Upload the dataset to the S3 source bucket.
Generative AI solutions often use Retrieval Augmented Generation (RAG) architectures, which augment external knowledge sources for improving content quality, context understanding, creativity, domain-adaptability, personalization, transparency, and explainability. Download the notebook file to use in this post.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















Let's personalize your content