This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
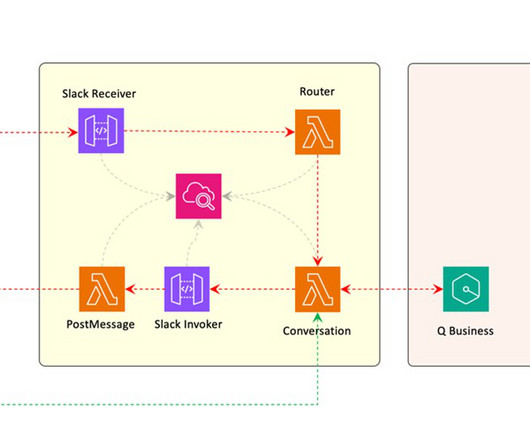
Amazon Q Business , a new generative AI-powered assistant, can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in an enterprises systems. Large-scale dataingestion is crucial for applications such as document analysis, summarization, research, and knowledge management.
On the other hand, a Node is a snippet or “chunk” from a Document, enriched with metadata and relationships to other nodes, ensuring a robust foundation for precise data retrieval later on. Data Indexes : Post dataingestion, LlamaIndex assists in indexing this data into a retrievable format.
The book starts by explaining what it takes to be a digital maverick and how enterprises can leverage digital solutions to transform how data is utilized. A digital maverick is typically characterized by big-picture thinking, technical prowess, and the understanding that systems can be optimized through dataingestion.
Each stage of the pipeline can perform structured extraction using any AI model or transform ingesteddata. The pipelines start working immediately upon dataingestion into Indexify, making them ideal for interactive applications and low-latency use cases. These pipelines are defined using declarative configuration.
Each stage of the pipeline can perform structured extraction using any AI model or transform ingesteddata. The pipelines start working immediately upon dataingestion into Indexify, making them ideal for interactive applications and low-latency use cases. These pipelines are defined using declarative configuration.
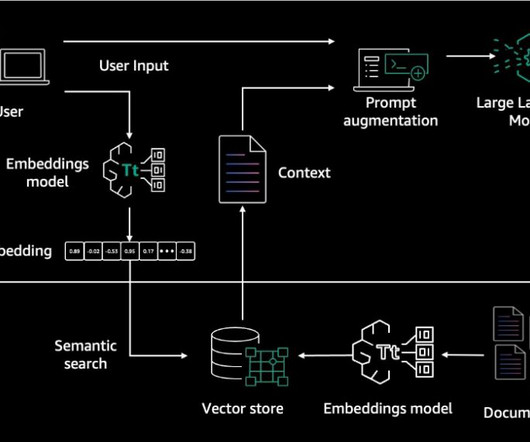
RAG architecture involves two key workflows: data preprocessing through ingestion, and text generation using enhanced context. The dataingestion workflow uses LLMs to create embedding vectors that represent semantic meaning of texts. It offers fully managed dataingestion and text generation workflows.
However, in industrial applications, the main bottleneck in efficient document retrieval often lies in the dataingestion pipeline rather than the embedding model’s performance. Optimizing this pipeline is crucial for extracting meaningful data that aligns with the capabilities of advanced retrieval systems.
We work backward from the customers business objectives, so I download an annual report from the customer website, upload it in Field Advisor, ask about the key business and tech objectives, and get a lot of valuable insights. I then use Field Advisor to brainstorm ideas on how to best position AWS services.
DataIngestion and Storage Resumes and job descriptions are collected from users and employers, respectively. AWS S3 is used to store and manage the data. DataIngestion and Storage: A Symphony in S3 Harmony We begin our masterpiece by curating the raw materials — the resumes and job descriptions.
Download it here and support a fellow community member. It emphasizes the role of LLamaindex in building RAG systems, managing dataingestion, indexing, and querying. Featured Community post from the Discord Max.berry_33008 has created a library of 24,000 prompts across 270 topics & featuring 90 prompt techniques.
Download the following student dataset to your local computer. The label column name is Target, and it contains categorical data: dropout, enrolled, and graduate. Dataingestion The first step for any ML process is to ingest the data. Set up SageMaker Canvas. The dataset comes under the Attribution 4.0
The dependencies template deploys a role to be used by Lambda and another for Step Functions, a workflow management service that will coordinate the tasks of dataingestion and processing, as well as predictor training and inference using Forecast. IAM roles define permissions within AWS for users and services.
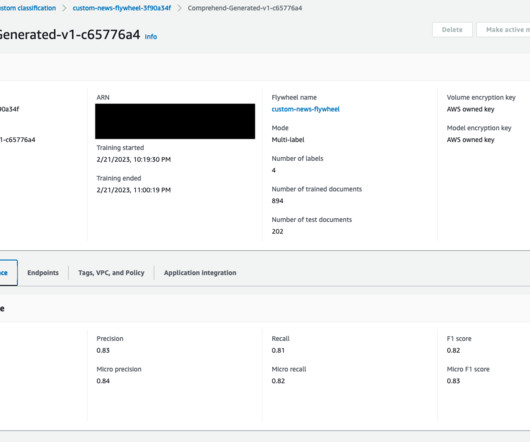
An Amazon Comprehend flywheel automates this ML process, from dataingestion to deploying the model in production. This feature also allows you to automate model retraining after new datasets are ingested and available in the flywheel´s data lake. Choose where you want to save the output file in your S3 location.
To make it available, download the DAG file from the repository to the dags/ directory in your project (browse GitHub tags to download to the same source code version as your installed DataRobot provider) and refresh the page. Multipersona Data Science and Machine Learning (DSML) Platforms. Download now. References. *
Many ML systems benefit from having the feature store as their data platform, including: Interactive ML systems receive a user request and respond with a prediction. An interactive ML system either downloads a model and calls it directly or calls a model hosted in a model-serving infrastructure.
Platforms like DataRobot AI Cloud support business analysts and data scientists by simplifying data prep, automating model creation, and easing ML operations ( MLOps ). These features reduce the need for a large workforce of data professionals. Download Now. Download Now. BARC ANALYST REPORT.
Download press releases to use as our external knowledge base. Call the loader’s load_data method to parse your source files and data and convert them into LlamaIndex Document objects, ready for indexing and querying. Deploy an embedding model from the Amazon SageMaker JumpStart hub. Query the knowledge base.
Amazon SageMaker Processing jobs for large scale dataingestion into OpenSearch. This notebook will ingest the SageMaker docs to an OpenSearch Service index called llm_apps_workshop_embeddings. This will download the dataset locally into the notebook and then ingest it into the OpenSearch Service index.
In Part 1 , we discussed the applications of GNNs and how to transform and prepare our IMDb data into a knowledge graph (KG). We downloaded the data from AWS Data Exchange and processed it in AWS Glue to generate KG files. The following diagram illustrates the complete architecture implemented as part of this series.
/data/images' local_file_name = Path(s3_path).name The first step is to download the pre-trained model weighting file, put it into a model.tar.gz The dataingestion for this practice should finish within 60 seconds. It also runs a simple query to verify if the data has been ingested into the index successfully.
It works well with data visualisation platforms like Kibana for analytics and reporting. Rich Ecosystem Elasticsearch is part of the larger Elastic Stack, which includes tools like Logstash for dataingestion and Kibana for data visualisation. Thus, it offers an end-to-end solution for data processing and analysis.
Windows and Mac have docker and docker-compose packaged into one application, so if you download docker on Windows or Mac, you have both docker and docker-compose. To download it, type this in your terminal curl -LFO '[link] and press enter. The docker-compose.yaml file that will be used is the official file from Apache Airflow.
Some industries rely not only on traditional data but also need data from sources such as security logs, IoT sensors, and web applications to provide the best customer experience. For example, before any video streaming services, users had to wait for videos or audio to get downloaded.
A typical data pipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process. DataIngestion : Involves raw data collection from origin and storage using architectures such as batch, streaming or event-driven.
Core features of end-to-end MLOps platforms End-to-end MLOps platforms combine a wide range of essential capabilities and tools, which should include: Data management and preprocessing : Provide capabilities for dataingestion, storage, and preprocessing, allowing you to efficiently manage and prepare data for training and evaluation.
To download a copy of this dataset, visit. To generate the forecast prediction, select the Download prediction dropdown menu button to download the forecast prediction chart as image or forecast prediction values as CSV file. When its complete, the Status will show as Ready , as shown in the following screenshot.
You could further optimize the time for training in the following graph by using a SageMaker managed warm pool and accessing pre-downloaded models using Amazon Elastic File System (Amazon EFS). Make sure you download the base model from Hugging Face before it’s fine-tuned using the use_downloaded_model parameter. 24xlarge instance.
Retrieval Augmented Generation Amazon Bedrock Knowledge Bases gives FMs contextual information from your private data sources for RAG to deliver more relevant, accurate, and customized responses. The RAG workflow consists of two key components: dataingestion and text generation.
It enables accessing, transforming, analyzing, and visualizing data on a single workstation. Databricks offers a cloud-based platform optimized for data engineering and collaborative analytics at scale. It brings together dataingestion, transformation, model training, and deployment in one integrated workflow.
It contains two flows: Dataingestion – The dataingestion flow converts the damage datasets (images and metadata) into vector embeddings and stores them in the OpenSearch vector store. We need to initially invoke this flow to load all the historic data into OpenSearch. Upload the dataset to the S3 source bucket.
The RAG-based chatbot we use ingests the Amazon Bedrock User Guide to assist customers on queries related to Amazon Bedrock. Dataset The dataset used in the notebook is the latest Amazon Bedrock User guide PDF file, which is publicly available to download.
Data lineage and auditing – Metadata can provide information about the provenance and lineage of documents, such as the source system, dataingestion pipeline, or other transformations applied to the data. This information can be valuable for data governance, auditing, and compliance purposes.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content