This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The operationalisation of data projects has been a key factor in helping organisations turn a data deluge into a workable digital transformation strategy, and DataOps carries on from where DevOps started. It’s all data driven,” Faruqui explains.
In this post, we share how Axfood, a large Swedish food retailer, improved operations and scalability of their existing artificial intelligence (AI) and machinelearning (ML) operations by prototyping in close collaboration with AWS experts and using Amazon SageMaker. This is a guest post written by Axfood AB.
Data exploration and model development were conducted using well-known machinelearning (ML) tools such as Jupyter or Apache Zeppelin notebooks. Apache Hive was used to provide a tabular interface to data stored in HDFS, and to integrate with Apache Spark SQL. HBase is employed to offer real-time key-based access to data.
Foundational models (FMs) are marking the beginning of a new era in machinelearning (ML) and artificial intelligence (AI) , which is leading to faster development of AI that can be adapted to a wide range of downstream tasks and fine-tuned for an array of applications. Large language models (LLMs) have taken the field of AI by storm.
The service allows for simple audio dataingestion, easy-to-read transcript creation, and accuracy improvement through custom vocabularies. Hugging Face is an open-source machinelearning (ML) platform that provides tools and resources for the development of AI projects.
MachineLearning Operations (MLOps) can significantly accelerate how data scientists and ML engineers meet organizational needs. A well-implemented MLOps process not only expedites the transition from testing to production but also offers ownership, lineage, and historical data about ML artifacts used within the team.
When machinelearning (ML) models are deployed into production and employed to drive business decisions, the challenge often lies in the operation and management of multiple models. That is where Provectus , an AWS Premier Consulting Partner with competencies in MachineLearning, Data & Analytics, and DevOps, stepped in.
Select the KB and in the Data source section, choose Sync to begin dataingestion. When dataingestion completes, a green success banner appears if it is successful. Use the managed vector store to allow Amazon Bedrock to create and manage the vector store for you in Amazon OpenSearch Service.
Do you need help to move your organization’s MachineLearning (ML) journey from pilot to production? Challenges Customers may face several challenges when implementing machinelearning (ML) solutions. Ensuring data quality, governance, and security may slow down or stall ML projects. You’re not alone.
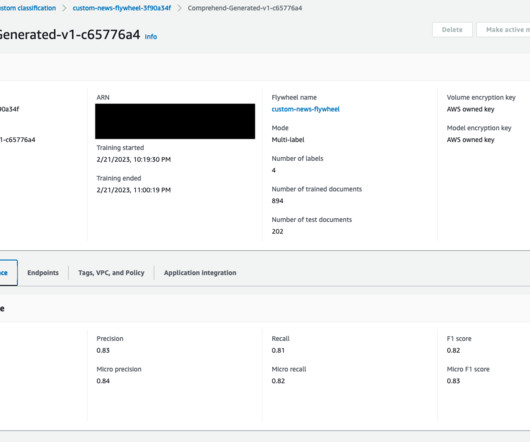
This combination of great models and continuous adaptation is what will lead to a successful machinelearning (ML) strategy. Today, we are excited to announce the launch of Amazon Comprehend flywheel—a one-stop machinelearning operations (MLOps) feature for an Amazon Comprehend model.
How to evaluate MLOps tools and platforms Like every software solution, evaluating MLOps (MachineLearning Operations) tools and platforms can be a complex task as it requires consideration of varying factors. Pay-as-you-go pricing makes it easy to scale when needed.
Furthermore, The platform’s versatility extends beyond data analysis. The pricing structure is based on the volume of dataingested, which can add up quickly for large-scale deployments. Resource Requirements Splunk’s data processing and indexing can consume significant system resources.
They can efficiently aggregate and process data over defined periods, making them ideal for identifying trends, anomalies, and correlations within the data. High-Volume DataIngestion TSDBs are built to handle large volumes of data coming in at high velocities. What are the Benefits of Using a Time Series Database?
For options 2, 3, and 4, the SageMaker Projects Portfolio provides project templates to run ML experiment pipelines, steps including dataingestion, model training, and registering the model in the model registry. Alberto Menendez is a DevOps Consultant in Professional Services at AWS.
Posted by Chansung Park, Sayak Paul (ML and Cloud GDEs) TensorFlow Extended ( TFX ) is a flexible framework allowing MachineLearning (ML) practitioners to iterate on production-grade ML workflows faster with reliability and resiliency. TFX Pipeline The ML pipeline is written entirely in TFX, from dataingestion to model deployment.
They run scripts manually to preprocess their training data, rerun the deployment scripts, manually tune their models, and spend their working hours keeping previously developed models up to date. Building end-to-end machinelearning pipelines lets ML engineers build once, rerun, and reuse many times.
Moving across the typical machinelearning lifecycle can be a nightmare. From gathering and processing data to building models through experiments, deploying the best ones, and managing them at scale for continuous value in production—it’s a lot. How to understand your users (data scientists, ML engineers, etc.).
Leverage Cloud Platforms Cloud platforms like AWS, Azure, and GCP offer a suite of scalable and flexible services for data storage, processing, and model deployment. Utilize cloud-based tools like Amazon S3 for data storage, Amazon SageMaker for model building and deployment, or Azure MachineLearning for a comprehensive managed service.
Operating such large-scale forecasting requires resilient, reusable, reproducible, and automated machinelearning (ML) workflows with fast experimentation and continuous improvements. When inference data is ingested on Amazon S3, EventBridge automatically runs the inference pipeline. Jalaj, and D. link] Kunz, M.,
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content