This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The operationalisation of data projects has been a key factor in helping organisations turn a data deluge into a workable digital transformation strategy, and DataOps carries on from where DevOps started. It’s all data driven,” Faruqui explains. And everybody agrees that in production, this should be automated.”
Thats why we use advanced technology and data analytics to streamline every step of the homeownership experience, from application to closing. This created a challenge for data scientists to become productive. Rockets legacy data science architecture is shown in the following diagram.
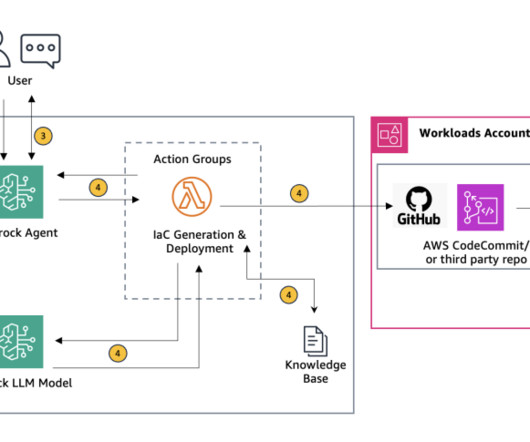
After being configured, an agent builds the prompt and augments it with your company-specific information to provide responses back to the user in natural language. During the IaC generation process, Amazon Bedrock agents actively probe for additional information by analyzing the provided diagrams and querying the user to fill any gaps.
The service allows for simple audio dataingestion, easy-to-read transcript creation, and accuracy improvement through custom vocabularies. It has been trained on a wide-ranging corpus of text data to understand various contexts and nuances of language. Mateusz Zaremba is a DevOps Architect at AWS Professional Services.
That is where Provectus , an AWS Premier Consulting Partner with competencies in Machine Learning, Data & Analytics, and DevOps, stepped in. It also persists a manifest file to Amazon S3, including all necessary information to recreate that dataset version.
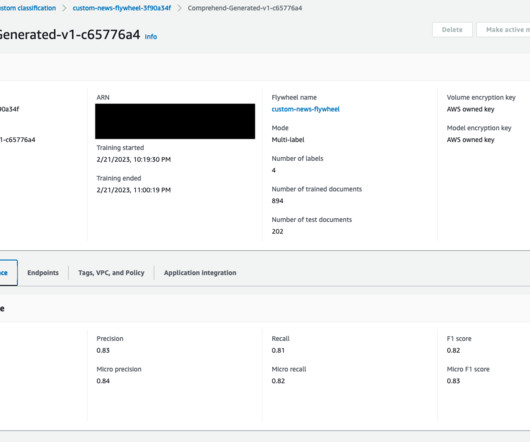
It helps you extract information by recognizing sentiments, key phrases, entities, and much more, allowing you to take advantage of state-of-the-art models and adapt them for your specific use case. An Amazon Comprehend flywheel automates this ML process, from dataingestion to deploying the model in production.
Introduction The digital revolution has ushered in an era of data deluge. From sensor networks and IoT devices to financial transactions and social media activity, we’re constantly generating a tidal wave of information. Within this data ocean, a specific type holds immense value: time series data.
Furthermore, The platform’s versatility extends beyond data analysis. Its ability to provide a unified view of the data makes it easier to manage it. Search and Investigation Capabilities One of the unique features of Splunk is that it allows better data analysis.
The first part is all about the core TFX pipeline handling all the steps from dataingestion to model deployment. We built a simple yet complete ML pipeline with support for automatic dataingestion, data preprocessing, model training, model evaluation, and model deployment in TFX. Hub service.
Core features of end-to-end MLOps platforms End-to-end MLOps platforms combine a wide range of essential capabilities and tools, which should include: Data management and preprocessing : Provide capabilities for dataingestion, storage, and preprocessing, allowing you to efficiently manage and prepare data for training and evaluation.
In the Account info section, provide the following information: For Select how to share , select Organization node. For options 2, 3, and 4, the SageMaker Projects Portfolio provides project templates to run ML experiment pipelines, steps including dataingestion, model training, and registering the model in the model registry.
The components comprise implementations of the manual workflow process you engage in for automatable steps, including: Dataingestion (extraction and versioning). Data validation (writing tests to check for data quality). Data preprocessing. Let’s briefly go over each of the components below. CSV, Parquet, etc.)
” — Isaac Vidas , Shopify’s ML Platform Lead, at Ray Summit 2022 Monitoring Monitoring is an essential DevOps practice, and MLOps should be no different. Collaboration The principles you have learned in this guide are mostly born out of DevOps principles. My Story DevOps Engineers Who they are?
Data collection – Updated shop prices lead to updated demand. The new information is used to enhance the training sets used in Step 1 for forecasting discounts. When inference data is ingested on Amazon S3, EventBridge automatically runs the inference pipeline. The following diagram illustrates this workflow.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















Let's personalize your content