This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Steep learning curve for data scientists: Many of Rockets data scientists did not have experience with Spark, which had a more nuanced programming model compared to other popular ML solutions like scikit-learn. This created a challenge for data scientists to become productive.
Large language models (LLMs) have taken the field of AI by storm. Scale and accelerate the impact of AI There are several steps to building and deploying a foundational model (FM). brings new generativeAI capabilities—powered by FMs and traditional machine learning (ML)—into a powerful studio spanning the AI lifecycle.
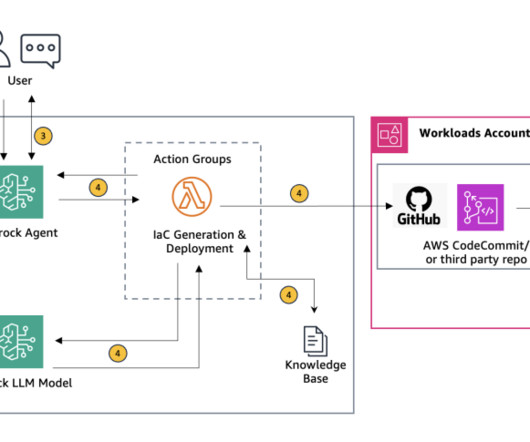
In this blog post, we explore how Agents for Amazon Bedrock can be used to generate customized, organization standards-compliant IaC scripts directly from uploaded architecture diagrams. Select the KB and in the Data source section, choose Sync to begin dataingestion. Double-check all entered information for accuracy.
If you prefer to generate post call recording summaries with Amazon Bedrock rather than Amazon SageMaker, checkout this Bedrock sample solution. The service allows for simple audio dataingestion, easy-to-read transcript creation, and accuracy improvement through custom vocabularies.
The model will be approved by designated data scientists to deploy the model for use in production. For production environments, dataingestion and trigger mechanisms are managed via a primary Airflow orchestration. Pavel Maslov is a Senior DevOps and ML engineer in the Analytic Platforms team.
For options 2, 3, and 4, the SageMaker Projects Portfolio provides project templates to run ML experiment pipelines, steps including dataingestion, model training, and registering the model in the model registry. Alberto Menendez is a DevOps Consultant in Professional Services at AWS.
When inference data is ingested on Amazon S3, EventBridge automatically runs the inference pipeline. This automated workflow streamlines the entire process, from dataingestion to inference, reducing manual interventions and minimizing the risk of errors. He is also a cycling enthusiast.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













Let's personalize your content