This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the ever-evolving landscape of machine learning, feature management has emerged as a key pain point for MLEngineers at Airbnb. Airbnb recognized the need for a solution that could streamline feature data management, provide real-time updates, and ensure consistency between training and production environments.
The SageMaker project template includes seed code corresponding to each step of the build and deploy pipelines (we discuss these steps in more detail later in this post) as well as the pipeline definition—the recipe for how the steps should be run. Pavel Maslov is a Senior DevOps and MLengineer in the Analytic Platforms team.
Data scientists have to address challenges like data partitioning, load balancing, fault tolerance, and scalability. MLengineers must handle parallelization, scheduling, faults, and retries manually, requiring complex infrastructure code. Ingest the prepared data into the feature group by using the Boto3 SDK.
Machine Learning Operations (MLOps) can significantly accelerate how data scientists and MLengineers meet organizational needs. A well-implemented MLOps process not only expedites the transition from testing to production but also offers ownership, lineage, and historical data about ML artifacts used within the team.
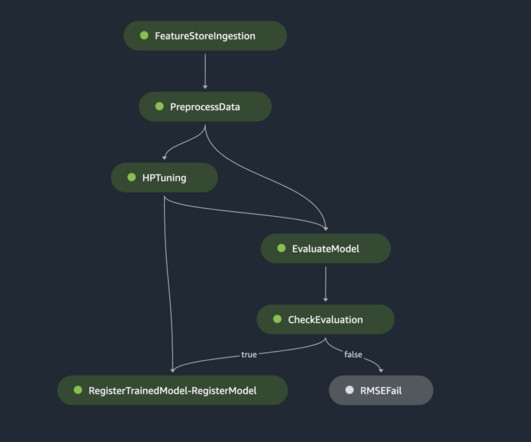
Getting a workflow ready which takes your data from its raw form to predictions while maintaining responsiveness and flexibility is the real deal. At that point, the Data Scientists or MLEngineers become curious and start looking for such implementations. 1 DataIngestion (e.g.,
From gathering and processing data to building models through experiments, deploying the best ones, and managing them at scale for continuous value in production—it’s a lot. As the number of ML-powered apps and services grows, it gets overwhelming for data scientists and MLengineers to build and deploy models at scale.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












Let's personalize your content