This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Photo by Marius Masalar on Unsplash Deeplearning. A subset of machine learning utilizing multilayered neural networks, otherwise known as deep neural networks. If you’re getting started with deeplearning, you’ll find yourself overwhelmed with the amount of frameworks. Let’s answer that question.
However, in industrial applications, the main bottleneck in efficient document retrieval often lies in the dataingestion pipeline rather than the embedding model’s performance. Optimizing this pipeline is crucial for extracting meaningful data that aligns with the capabilities of advanced retrieval systems.
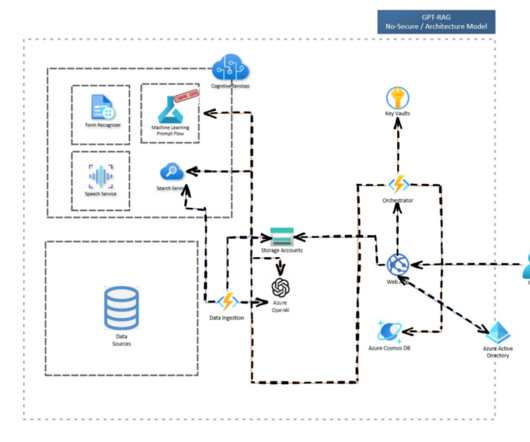
This observability ensures continuity in operations and provides valuable data for optimizing the deployment of LLMs in enterprise settings. The key components of GPT-RAG are dataingestion, Orchestrator, and front-end app.
Deltek is continuously working on enhancing this solution to better align it with their specific requirements, such as supporting file formats beyond PDF and implementing more cost-effective approaches for their dataingestion pipeline. The first step is dataingestion, as shown in the following diagram. What is RAG?
In this session, you’ll explore the following questions Why Ray was built and what it is How AIR, built atop Ray, allows you to easily program and scale your machine learning workloads AIR’s interoperability and easy integration points with other systems for storage and metadata needs AIR’s cutting-edge features for accelerating the machine learning (..)
Understanding the MLOps Lifecycle The MLOps lifecycle consists of several critical stages, each with its unique challenges: DataIngestion: Collecting data from various sources and ensuring it’s available for analysis. Data Preparation: Cleaning and transforming raw data to make it usable for machine learning.
The service allows for simple audio dataingestion, easy-to-read transcript creation, and accuracy improvement through custom vocabularies. The framework provisions resources in a safe, repeatable manner, allowing for a significant acceleration of the development process.
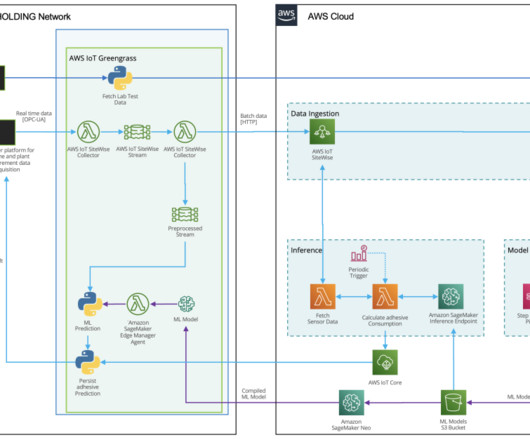
In that post, you can learn more about the developmental lifecycle of a generative AI application and the additional skills, processes, and technologies needed to operationalize generative AI applications. AWS provides several services to support this; the following diagram illustrates these at a high level.
SageMaker has developed the distributed data parallel library , which splits data per node and optimizes the communication between the nodes. You can use the SageMaker Python SDK to trigger a job with data parallelism with minimal modifications to the training script.
MongoDB Atlas offers automatic sharding, horizontal scalability, and flexible indexing for high-volume dataingestion. Among all, the native time series capabilities is a standout feature, making it ideal for a managing high volume of time-series data, such as business critical application data, telemetry, server logs and more.
DeepLearning & Multi-Modal Models TrackPush Neural NetworksFurther Dive into the latest advancements in neural networks, multimodal learning, and self-supervised models. This track provides practical guidance on building and optimizing deep learningsystems.
Core features of end-to-end MLOps platforms End-to-end MLOps platforms combine a wide range of essential capabilities and tools, which should include: Data management and preprocessing : Provide capabilities for dataingestion, storage, and preprocessing, allowing you to efficiently manage and prepare data for training and evaluation.
Earth.com’s leadership team recognized the vast potential of EarthSnap and set out to create an application that utilizes the latest deeplearning (DL) architectures for computer vision (CV). EarthSnap was developed by Earth.com , a leading online platform for enthusiasts who are passionate about the environment, nature, and science.
Over the course of this session, you will develop an understanding of no-code and low-code frameworks, how they are used in the ML workflow, how they can be used for dataingestion and analysis, and for building, training, and deploying ML models. Sign me up!
Amazon SageMaker Processing jobs for large scale dataingestion into OpenSearch. This notebook will ingest the SageMaker docs to an OpenSearch Service index called llm_apps_workshop_embeddings. This will download the dataset locally into the notebook and then ingest it into the OpenSearch Service index.
The tool of choice for this project was NLP Lab for its powerful pre-annotation capabilities, allowing them to annotate the dataset efficiently and train a tailored deeplearning model for automatic pre-annotation of new content in a couple of clicks.
Creates two indexes for text ( ooc_text ) and kNN embedding search ( ooc_knn ) and bulk uploads data from the combined dataframe through the ingest_data_into_ops function. This dataingestion process takes 5–10 minutes and can be monitored through the Amazon CloudWatch logs on the Monitoring tab of the Lambda function.
Thirdly, the presence of GPUs enabled the labeled data to be processed. Together, these elements lead to the start of a period of dramatic progress in ML, with NN being redubbed deeplearning. In order to train transformer models on internet-scale data, huge quantities of PBAs were needed.
Stripling, PhD | Lead AI & ML Content Developer | Google Cloud In a no-code or low-code world you don’t have to have mastered coding to deploy machine learning models. Conclusion Can’t wait to start learning from these incredible speakers and experts?
I recently took the Azure Data Scientist Associate certification exam DP-100, thankfully I passed after about 3–4 months for studying the Microsoft Data Science Learning Path and the Coursera Microsoft Azure Data Scientist Associate Specialization.
Once an organization has identified its AI use cases , data scientists informally explore methodologies and solutions relevant to the business’s needs in the hunt for proofs of concept. These might include—but are not limited to—deeplearning, image recognition and natural language processing.
Recommended How to Solve the DataIngestion and Feature Store Component of the MLOps Stack Read more A unified architecture for ML systems One of the challenges in building machine-learning systems is architecting the system. In Table 1 below, I’ve compiled a list of different ML systems that follow the unified architecture.
Dataingestion HAYAT HOLDING has a state-of-the art infrastructure for acquiring, recording, analyzing, and processing measurement data. Two types of data sources exist for this use case. KEAS ranks first in the industry with its approximately 7,000 employees and exports to more than 100 countries.
BERT and Sentence Transformers : These advanced models use DeepLearning and transformer architectures to generate context-aware embeddings, enabling nuanced understanding for tasks like semantic search and question answering.
This service enables Data Scientists to query data on their terms using serverless or provisioned resources at scale. It also integrates deeply with Power BI and Azure Machine Learning, providing a seamless workflow from dataingestion to advanced analytics.
Discretization methods: To apply SSMs to discrete-time data, various discretization methods are used, such as Zero-Order Hold (ZOH) or bilinear transformations. Normalization layers: Like many deeplearning models, SSMs often incorporate normalization layers (e.g., LayerNorm) to stabilize training.
In this phase, you submit a text search query or image search query through the deeplearning model (CLIP) to encode as embeddings. The dataingestion for this practice should finish within 60 seconds. It also runs a simple query to verify if the data has been ingested into the index successfully.
Personas associated with this phase may be primarily Infrastructure Team but may also include all of Data Engineers, Machine Learning Engineers, and Data Scientists. Model Development (Inner Loop): The inner loop element consists of your iterative data science workflow.
You have learned how to trigger a DAG in Airflow, create a DAG from scratch, and initiate its execution. In the upcoming part of this series, we will delve into advanced concepts of Airflow, including backfilling techniques and building an ETL pipeline in Airflow for dataingestion into Postgres and Google Cloud BigQuery.
Related DeepLearning Model Optimization Methods Read more Example Scenario: Deploying customer service chatbot Imagine that you are in charge of implementing a LLM-powered chatbot for customer support. Develop the text preprocessing pipeline Dataingestion: Use Unstructured.io
1 DataIngestion (e.g., Apache Kafka, Amazon Kinesis) 2 Data Preprocessing (e.g., Scikit-learn, Feature Tools) 4 Model Training (e.g., Scikit-learn, MLflow) 6 Model Deployment (e.g., Each of these architectural patterns plays a crucial role in enhancing the efficiency of machine learning pipelines.
Data flow Here is an example of this data flow for an Agent Creator pipeline that involves dataingestion, preprocessing, and vectorization using Chunker and Embedding Snaps. He focuses on Deeplearning including NLP and Computer Vision domains.
Zeta’s AI innovations over the past few years span 30 pending and issued patents, primarily related to the application of deeplearning and generative AI to marketing technology. Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from dataingestion to model deployment.
This helps address the requirements of the generative AI fine-tuning lifecycle, from dataingestion and multi-node fine-tuning to inference and evaluation. Refer to the installation instructions and PyTorch documentation to learn more about torchtune and its concepts.
Google Data Studio: Turn data into informative dashboards and reports. Data & ML/LLM Ops on GCP Vertex AI: End-to-end platform to build, deploy, and scale ML models. TensorFlow Enterprise: High-performance deeplearning on Google Cloud. Natural Language AI: Analyze and understand text data for LLM applications.
Google Data Studio: Turn data into informative dashboards and reports. Data & ML/LLM Ops on GCP Vertex AI: End-to-end platform to build, deploy, and scale ML models. TensorFlow Enterprise: High-performance deeplearning on Google Cloud. Natural Language AI: Analyze and understand text data for LLM applications.
Name Short Description Algorithmia Securely govern your machine learning operations with a healthy ML lifecycle. An end-to-end enterprise-grade platform for data scientists, data engineers, DevOps, and managers to manage the entire machine learning & deeplearning product life-cycle. Allegro.io
Depending on the complexity of the problem and the structure of underlying data, the predictive models at Zalando range from simple statistical averages, over tree-based models to a Transformer-based deeplearning architecture (Kunz et al. DeepLearning based Forecasting: a case study from the online fashion industry.”
Data lineage and auditing – Metadata can provide information about the provenance and lineage of documents, such as the source system, dataingestion pipeline, or other transformations applied to the data. This information can be valuable for data governance, auditing, and compliance purposes.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content